INSIGHT: End-to-End Neuro-Symbolic Visual Reinforcement Learning with Language Explanations

0

Sign in to get full access
Overview
- This paper presents INSIGHT, an end-to-end neuro-symbolic visual reinforcement learning system that can learn to solve complex visual tasks and provide natural language explanations of its reasoning.
- INSIGHT combines deep reinforcement learning with symbolic planning and language generation to enable agents to learn task-solving policies and articulate their decision-making process.
- The system is evaluated on a series of challenging visual tasks, demonstrating its ability to learn effective behaviors and generate high-quality explanations that provide insight into the agent's internal decision-making.
Plain English Explanation
INSIGHT: End-to-End Neuro-Symbolic Visual Reinforcement Learning with Language Explanations is a new AI system that can solve complex visual tasks and explain its reasoning in plain language.
The key idea is to combine two powerful AI techniques - reinforcement learning for learning effective task-solving policies, and natural language generation for producing explanations that reveal the agent's internal decision-making.
By bridging the divide between neural networks and symbolic reasoning, INSIGHT can learn to navigate visual environments, make decisions, and then explain its actions in clear, natural language. This allows the system to not just perform well on tasks, but also provide meaningful insights into how it is accomplishing them.
The researchers evaluate INSIGHT on a variety of challenging visual scenarios, showing that it can learn effective behaviors while also generating high-quality explanations that give the user a window into the agent's inner workings. This type of "explainable AI" is an important step towards building intelligent systems that are not just capable, but also transparent and trustworthy.
Technical Explanation
INSIGHT: End-to-End Neuro-Symbolic Visual Reinforcement Learning with Language Explanations is a novel AI system that combines deep reinforcement learning, symbolic planning, and language generation to enable agents to learn to solve complex visual tasks and provide natural language explanations of their reasoning.
The core architecture of INSIGHT consists of several key components:
- A deep reinforcement learning module that learns effective task-solving policies through interaction with the environment
- A symbolic planner that reasons about high-level goals, constraints, and causal relationships
- A language generation module that converts the planner's symbolic representations into natural language explanations
By integrating these neuro-symbolic elements, INSIGHT is able to learn complex behaviors while also maintaining an internal model of its decision-making process that can be explicitly articulated through language.
The researchers evaluate INSIGHT on a diverse set of visual tasks, including object manipulation, navigation, and multi-agent coordination. The results demonstrate that the system is able to learn effective policies that achieve high rewards, while also generating explanations that provide insight into how the agent is reasoning and making decisions.
The explanations produced by INSIGHT go beyond simple step-by-step descriptions, and instead capture the agent's higher-level planning and reasoning. This allows the system to not just describe what it is doing, but to explain why it is doing it, making the agent's behavior more transparent and interpretable.
Critical Analysis
The INSIGHT system represents an important step forward in the field of explainable AI, demonstrating how neuro-symbolic architectures can enable agents to learn complex behavior while also maintaining the ability to articulate their reasoning.
However, the paper also acknowledges several limitations and areas for future work. For example, the current implementation is limited to relatively simple visual environments, and it is unclear how well the system would scale to more complex, real-world scenarios. Additionally, the language generation component, while impressive, is still relatively constrained and may struggle with more open-ended or nuanced forms of explanation.
There are also open questions about the fidelity and truthfulness of the explanations produced by INSIGHT. While the system aims to provide meaningful insights into its decision-making, it is possible that the explanations could be biased or incomplete, potentially leading to misunderstandings about the agent's true reasoning.
Further research is needed to address these challenges and to explore the broader implications of integrating neuro-symbolic approaches for building more transparent and trustworthy AI systems. Nevertheless, the INSIGHT work represents an important step forward in this direction and serves as a valuable contribution to the ongoing efforts to make AI more interpretable and accountable.
Conclusion
INSIGHT: End-to-End Neuro-Symbolic Visual Reinforcement Learning with Language Explanations presents a novel AI system that combines deep reinforcement learning, symbolic planning, and natural language generation to enable agents to learn complex visual tasks while also providing meaningful explanations of their decision-making.
By bridging the divide between neural networks and symbolic reasoning, INSIGHT demonstrates the potential for neuro-symbolic architectures to produce intelligent behavior that is not just effective, but also transparent and interpretable. The ability to generate high-quality natural language explanations is a significant advance towards building AI systems that are more trustworthy and accountable.
While the current implementation has some limitations, the INSIGHT work represents an important step forward in the field of explainable AI and lays the groundwork for future research aimed at developing even more sophisticated and capable AI systems that can effectively communicate their inner workings to human users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
INSIGHT: End-to-End Neuro-Symbolic Visual Reinforcement Learning with Language Explanations
Lirui Luo, Guoxi Zhang, Hongming Xu, Yaodong Yang, Cong Fang, Qing Li
Neuro-symbolic reinforcement learning (NS-RL) has emerged as a promising paradigm for explainable decision-making, characterized by the interpretability of symbolic policies. NS-RL entails structured state representations for tasks with visual observations, but previous methods cannot refine the structured states with rewards due to a lack of efficiency. Accessibility also remains an issue, as extensive domain knowledge is required to interpret symbolic policies. In this paper, we present a neuro-symbolic framework for jointly learning structured states and symbolic policies, whose key idea is to distill the vision foundation model into an efficient perception module and refine it during policy learning. Moreover, we design a pipeline to prompt GPT-4 to generate textual explanations for the learned policies and decisions, significantly reducing users' cognitive load to understand the symbolic policies. We verify the efficacy of our approach on nine Atari tasks and present GPT-generated explanations for policies and decisions.
Read more6/14/2024
🏅
0
Vision-Language Models Provide Promptable Representations for Reinforcement Learning
William Chen, Oier Mees, Aviral Kumar, Sergey Levine
Humans can quickly learn new behaviors by leveraging background world knowledge. In contrast, agents trained with reinforcement learning (RL) typically learn behaviors from scratch. We thus propose a novel approach that uses the vast amounts of general and indexable world knowledge encoded in vision-language models (VLMs) pre-trained on Internet-scale data for embodied RL. We initialize policies with VLMs by using them as promptable representations: embeddings that encode semantic features of visual observations based on the VLM's internal knowledge and reasoning capabilities, as elicited through prompts that provide task context and auxiliary information. We evaluate our approach on visually-complex, long horizon RL tasks in Minecraft and robot navigation in Habitat. We find that our policies trained on embeddings from off-the-shelf, general-purpose VLMs outperform equivalent policies trained on generic, non-promptable image embeddings. We also find our approach outperforms instruction-following methods and performs comparably to domain-specific embeddings. Finally, we show that our approach can use chain-of-thought prompting to produce representations of common-sense semantic reasoning, improving policy performance in novel scenes by 1.5 times.
Read more5/24/2024

0
Neural Reward Machines
Elena Umili, Francesco Argenziano, Roberto Capobianco
Non-markovian Reinforcement Learning (RL) tasks are very hard to solve, because agents must consider the entire history of state-action pairs to act rationally in the environment. Most works use symbolic formalisms (as Linear Temporal Logic or automata) to specify the temporally-extended task. These approaches only work in finite and discrete state environments or continuous problems for which a mapping between the raw state and a symbolic interpretation is known as a symbol grounding (SG) function. Here, we define Neural Reward Machines (NRM), an automata-based neurosymbolic framework that can be used for both reasoning and learning in non-symbolic non-markovian RL domains, which is based on the probabilistic relaxation of Moore Machines. We combine RL with semisupervised symbol grounding (SSSG) and we show that NRMs can exploit high-level symbolic knowledge in non-symbolic environments without any knowledge of the SG function, outperforming Deep RL methods which cannot incorporate prior knowledge. Moreover, we advance the research in SSSG, proposing an algorithm for analysing the groundability of temporal specifications, which is more efficient than baseline techniques of a factor $10^3$.
Read more8/19/2024
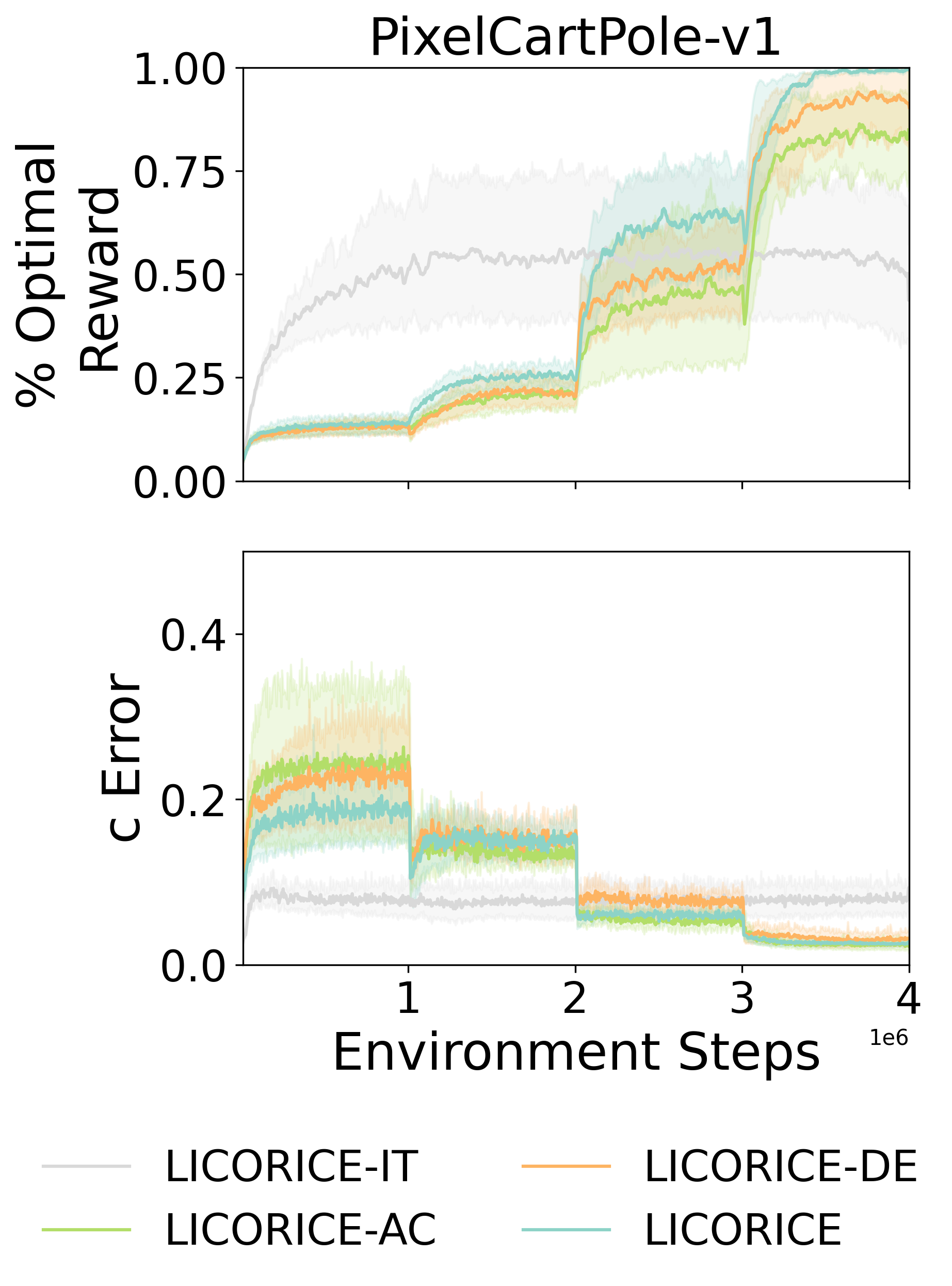
0
Concept-Based Interpretable Reinforcement Learning with Limited to No Human Labels
Zhuorui Ye, Stephanie Milani, Geoffrey J. Gordon, Fei Fang
Recent advances in reinforcement learning (RL) have predominantly leveraged neural network-based policies for decision-making, yet these models often lack interpretability, posing challenges for stakeholder comprehension and trust. Concept bottleneck models offer an interpretable alternative by integrating human-understandable concepts into neural networks. However, a significant limitation in prior work is the assumption that human annotations for these concepts are readily available during training, necessitating continuous real-time input from human annotators. To overcome this limitation, we introduce a novel training scheme that enables RL algorithms to efficiently learn a concept-based policy by only querying humans to label a small set of data, or in the extreme case, without any human labels. Our algorithm, LICORICE, involves three main contributions: interleaving concept learning and RL training, using a concept ensembles to actively select informative data points for labeling, and decorrelating the concept data with a simple strategy. We show how LICORICE reduces manual labeling efforts to to 500 or fewer concept labels in three environments. Finally, we present an initial study to explore how we can use powerful vision-language models to infer concepts from raw visual inputs without explicit labels at minimal cost to performance.
Read more7/23/2024