Confidence-based Estimators for Predictive Performance in Model Monitoring

0

Sign in to get full access
Overview
- This paper presents a new approach for estimating the predictive performance of machine learning models, with a focus on providing reliable confidence intervals.
- The proposed method addresses challenges in model monitoring, where accurate performance estimates are critical for detecting model degradation or drift over time.
- The authors introduce a confidence-based estimator that can provide more robust and reliable performance estimates compared to traditional approaches.
Plain English Explanation
This research paper introduces a new way to measure how well a machine learning model is performing. When you use a model to make predictions, it's important to know how accurate those predictions are. The traditional methods for measuring a model's performance can sometimes give misleading results, especially if the model's behavior changes over time.
The researchers developed a new technique that provides more trustworthy estimates of the model's predictive performance. This is particularly useful in the context of model monitoring, where you need to keep an eye on a model's performance to make sure it's still working well.
The key idea is to use the model's own confidence in its predictions to get a better sense of the overall model performance. This can help detect when a model's performance starts to degrade or become miscalibrated, which is crucial for maintaining reliable and trustworthy machine learning systems.
The authors demonstrate the effectiveness of their approach through experiments, showing that it can provide more accurate and reliable performance estimates compared to standard methods. This work has important implications for building robust and trustworthy AI models, especially in high-stakes applications where model performance is critical.
Technical Explanation
The paper introduces a new confidence-based estimator for predictive performance in the context of model monitoring. The proposed approach aims to address the limitations of traditional performance evaluation metrics, which can be sensitive to distributional shifts or other changes in the data over time.
The key idea is to leverage the model's own confidence in its predictions to derive more robust and reliable estimates of the model's overall predictive performance. The authors develop a confidence-based estimator that can provide tighter confidence intervals for the true performance, compared to standard methods like cross-validation or holdout testing.
The confidence-based estimator works by first calibrating the model's predictions to ensure that the reported confidence levels align with the true correctness probability. It then uses this calibrated confidence information to derive performance estimates that are more resilient to changes in the data distribution.
The authors evaluate their approach on several benchmark datasets and show that the confidence-based estimator outperforms traditional methods in terms of accuracy and reliability of the performance estimates. They also demonstrate the utility of the approach in the context of model monitoring, where it can help detect performance degradation or model drift more effectively.
Critical Analysis
The paper presents a solid technical contribution to the field of model monitoring and performance evaluation. The authors have carefully designed their confidence-based estimator and provided a thorough evaluation of its properties.
One potential limitation of the approach is that it relies on the model's ability to produce well-calibrated confidence estimates. If the model is not well-calibrated, the confidence-based estimator may not provide the expected benefits. The authors acknowledge this challenge and suggest further research on improving model calibration, which is an active area of investigation in the machine learning community.
Additionally, the paper focuses on the supervised learning setting, and it would be interesting to see how the confidence-based estimator could be extended to other problem domains, such as unsupervised learning or reinforcement learning. The authors mention this as a potential direction for future work.
Overall, this paper makes an important contribution to the field of model monitoring and performance evaluation, and the proposed confidence-based estimator has the potential to improve the reliability and robustness of machine learning systems, especially in high-stakes applications.
Conclusion
This research paper introduces a novel confidence-based estimator for predictive performance in the context of model monitoring. The proposed approach addresses the limitations of traditional performance evaluation metrics by leveraging the model's own confidence information to derive more robust and reliable estimates of the true model performance.
The authors demonstrate the effectiveness of their method through extensive experiments, showing that the confidence-based estimator can outperform standard techniques in terms of accuracy and reliability of the performance estimates. This work has important implications for building trustworthy and robust machine learning systems, especially in high-stakes applications where model performance is critical.
The paper also highlights the need for further research on improving model calibration and extending the confidence-based estimator to other problem domains, such as unsupervised learning and reinforcement learning. Overall, this work represents a significant contribution to the field of model monitoring and performance evaluation, and it will likely inspire further advancements in this important area of machine learning research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Confidence-based Estimators for Predictive Performance in Model Monitoring
Juhani Kivimaki, Jakub Bia{l}ek, Jukka K. Nurminen, Wojtek Kuberski
After a machine learning model has been deployed into production, its predictive performance needs to be monitored. Ideally, such monitoring can be carried out by comparing the model's predictions against ground truth labels. For this to be possible, the ground truth labels must be available relatively soon after inference. However, there are many use cases where ground truth labels are available only after a significant delay, or in the worst case, not at all. In such cases, directly monitoring the model's predictive performance is impossible. Recently, novel methods for estimating the predictive performance of a model when ground truth is unavailable have been developed. Many of these methods leverage model confidence or other uncertainty estimates and are experimentally compared against a naive baseline method, namely Average Confidence (AC), which estimates model accuracy as the average of confidence scores for a given set of predictions. However, until now the theoretical properties of the AC method have not been properly explored. In this paper, we try to fill this gap by reviewing the AC method and show that under certain general assumptions, it is an unbiased and consistent estimator of model accuracy with many desirable properties. We also compare this baseline estimator against some more complex estimators empirically and show that in many cases the AC method is able to beat the others, although the comparative quality of the different estimators is heavily case-dependent.
Read more7/12/2024

0
Confidence Interval Estimation of Predictive Performance in the Context of AutoML
Konstantinos Paraschakis, Andrea Castellani, Giorgos Borboudakis, Ioannis Tsamardinos
Any supervised machine learning analysis is required to provide an estimate of the out-of-sample predictive performance. However, it is imperative to also provide a quantification of the uncertainty of this performance in the form of a confidence or credible interval (CI) and not just a point estimate. In an AutoML setting, estimating the CI is challenging due to the ``winner's curse, i.e., the bias of estimation due to cross-validating several machine learning pipelines and selecting the winning one. In this work, we perform a comparative evaluation of 9 state-of-the-art methods and variants in CI estimation in an AutoML setting on a corpus of real and simulated datasets. The methods are compared in terms of inclusion percentage (does a 95% CI include the true performance at least 95% of the time), CI tightness (tighter CIs are preferable as being more informative), and execution time. The evaluation is the first one that covers most, if not all, such methods and extends previous work to imbalanced and small-sample tasks. In addition, we present a variant, called BBC-F, of an existing method (the Bootstrap Bias Correction, or BBC) that maintains the statistical properties of the BBC but is more computationally efficient. The results support that BBC-F and BBC dominate the other methods in all metrics measured.
Read more6/13/2024
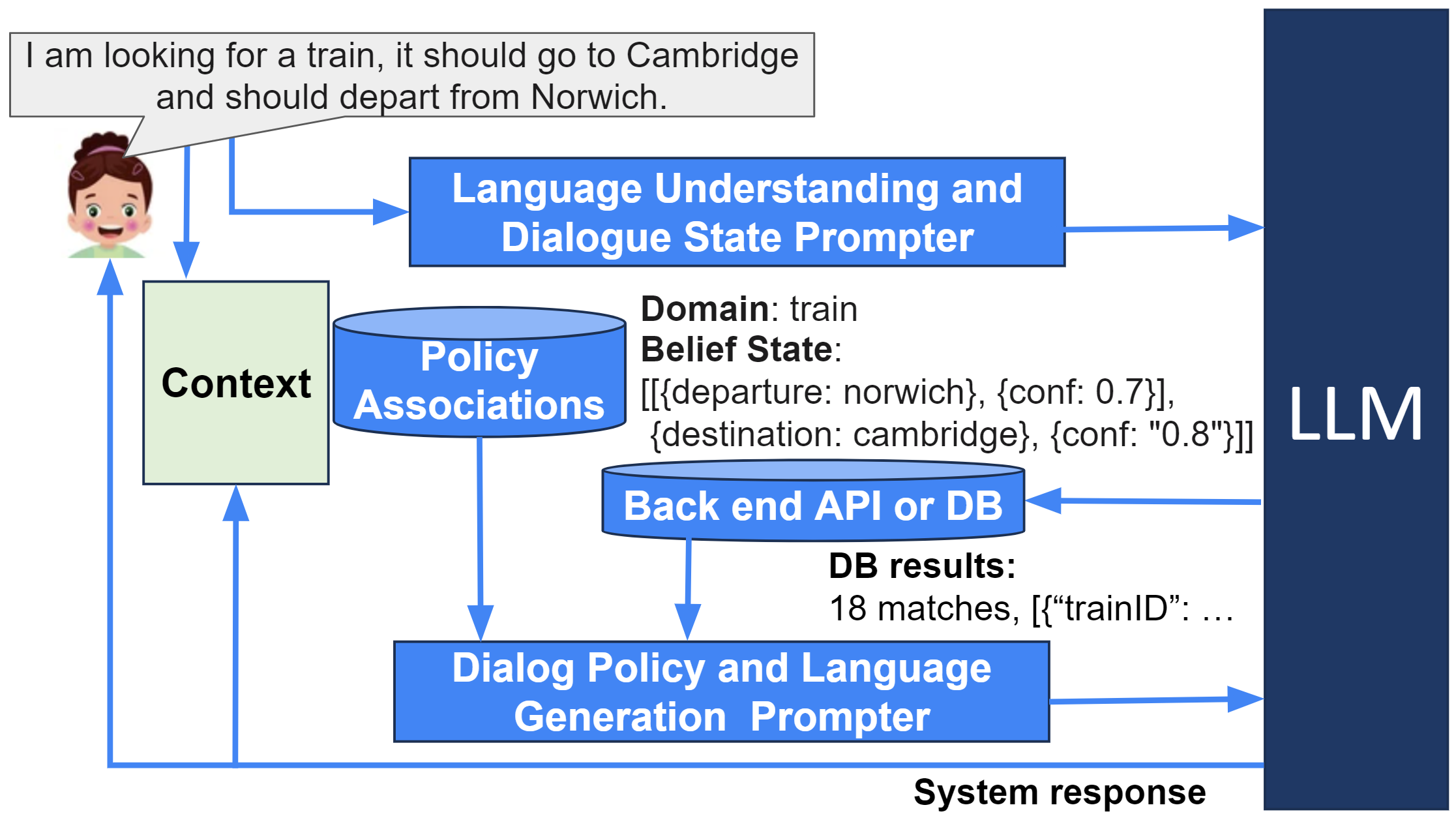
0
Confidence Estimation for LLM-Based Dialogue State Tracking
Yi-Jyun Sun, Suvodip Dey, Dilek Hakkani-Tur, Gokhan Tur
Estimation of a model's confidence on its outputs is critical for Conversational AI systems based on large language models (LLMs), especially for reducing hallucination and preventing over-reliance. In this work, we provide an exhaustive exploration of methods, including approaches proposed for open- and closed-weight LLMs, aimed at quantifying and leveraging model uncertainty to improve the reliability of LLM-generated responses, specifically focusing on dialogue state tracking (DST) in task-oriented dialogue systems (TODS). Regardless of the model type, well-calibrated confidence scores are essential to handle uncertainties, thereby improving model performance. We evaluate four methods for estimating confidence scores based on softmax, raw token scores, verbalized confidences, and a combination of these methods, using the area under the curve (AUC) metric to assess calibration, with higher AUC indicating better calibration. We also enhance these with a self-probing mechanism, proposed for closed models. Furthermore, we assess these methods using an open-weight model fine-tuned for the task of DST, achieving superior joint goal accuracy (JGA). Our findings also suggest that fine-tuning open-weight LLMs can result in enhanced AUC performance, indicating better confidence score calibration.
Read more9/17/2024
👨🏫
0
Surrogate uncertainty estimation for your time series forecasting black-box: learn when to trust
Leonid Erlygin, Vladimir Zholobov, Valeriia Baklanova, Evgeny Sokolovskiy, Alexey Zaytsev
Machine learning models play a vital role in time series forecasting. These models, however, often overlook an important element: point uncertainty estimates. Incorporating these estimates is crucial for effective risk management, informed model selection, and decision-making.To address this issue, our research introduces a method for uncertainty estimation. We employ a surrogate Gaussian process regression model. It enhances any base regression model with reasonable uncertainty estimates. This approach stands out for its computational efficiency. It only necessitates training one supplementary surrogate and avoids any data-specific assumptions. Furthermore, this method for work requires only the presence of the base model as a black box and its respective training data. The effectiveness of our approach is supported by experimental results. Using various time-series forecasting data, we found that our surrogate model-based technique delivers significantly more accurate confidence intervals. These techniques outperform both bootstrap-based and built-in methods in a medium-data regime. This superiority holds across a range of base model types, including a linear regression, ARIMA, gradient boosting and a neural network.
Read more9/11/2024