When to Trust LLMs: Aligning Confidence with Response Quality

0
↗️
Sign in to get full access
Overview
- Large language models (LLMs) are powerful at natural language generation but can produce incorrect or nonsensical text
- This highlights the importance of determining when to trust LLMs, especially in safety-critical domains
- Existing methods that rely on verbalizing confidence often fail due to the lack of objective guidance on confidence
- The researchers propose a new approach called CONQORD to better align confidence levels with response accuracy
Plain English Explanation
Large language models (LLMs) are computer systems that can generate human-like text. They have become very good at tasks like writing stories, answering questions, and translating between languages. However, research has shown that LLMs can sometimes produce text that is incorrect or doesn't make sense.
This is a problem because we need to be able to trust LLMs, especially when they are being used for important tasks like medical diagnosis or financial planning. Existing methods for determining when to trust an LLM's response often fail because they rely on the model simply stating how confident it is, without any objective way to verify that confidence level.
To address this, the researchers developed a new approach called CONQORD. CONQORD uses a type of machine learning called reinforcement learning to train the LLM to align its confidence levels with the actual quality of its responses. This means the model will express higher confidence for responses that are more accurate and lower confidence for responses that are less accurate.
By aligning confidence with quality, CONQORD can help users of the LLM better understand when they can trust its outputs and when they should seek additional information or verification. This makes the LLM's responses more transparent and reliable, improving trust in the technology.
Technical Explanation
The researchers propose the CONfidence-Quality-ORDerpreserving alignment approach (CONQORD), which uses reinforcement learning with a dual-component reward function to better align an LLM's expressed confidence with the actual quality of its responses.
The key innovation is the "order-preserving" reward function, which incentivizes the model to verbalize greater confidence for responses of higher quality. This helps ensure the model's confidence levels are well-calibrated and reflect the true accuracy of its outputs.
Experiments show that CONQORD significantly improves the alignment between confidence levels and response accuracy, without making the model overly cautious. The aligned confidence provided by CONQORD can then be used to determine when to trust the LLM's outputs and when to retrieve additional external knowledge to supplement the response.
By ensuring confidence is well-aligned with quality, CONQORD makes the LLM's responses more transparent and reliable, improving the overall trustworthiness of the system. This addresses a key limitation of existing confidence calibration and rejection-based approaches, which often fail to provide objective guidance on when to trust the model.
Critical Analysis
The CONQORD approach represents an important step forward in improving the reliability and trustworthiness of large language models. By directly aligning confidence with response quality, it addresses a fundamental limitation of existing methods that rely on subjective confidence ratings.
However, the paper does not fully explore the potential limitations of this approach. For example, it is unclear how well CONQORD would generalize to more open-ended or creative language generation tasks, where the notion of "quality" may be more subjective. There is also the question of how robust the confidence-quality alignment would be to adversarial attacks or distributional shift in the input data.
Additionally, while the experiments demonstrate improved alignment, the paper does not provide a detailed analysis of the types of errors or mistakes the model is still making, even with the CONQORD approach. Further research into the remaining failure modes and potential mitigation strategies would be valuable.
Overall, the CONQORD method represents a promising step towards more reliable and trustworthy large language models. However, as with any new approach, continued critical analysis and empirical testing will be necessary to fully understand its limitations and potential areas for improvement.
Conclusion
The research paper presents a novel approach called CONQORD that aims to better align the confidence levels expressed by large language models with the actual quality and accuracy of their responses. By using reinforcement learning with a tailored reward function, CONQORD can incentivize the model to verbalize higher confidence for higher-quality outputs.
This alignment of confidence and quality is an important step towards making LLMs more transparent, reliable, and trustworthy, especially in safety-critical domains. The CONQORD approach represents a significant advancement over existing methods that rely on subjective confidence ratings, which often fail to provide objective guidance on when to trust an LLM's outputs.
While the research shows promising results, there are still open questions and potential limitations that warrant further investigation. Nonetheless, the CONQORD method is a valuable contribution to the ongoing efforts to develop more logically consistent and reliable language models that can be safely deployed in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
↗️
0
When to Trust LLMs: Aligning Confidence with Response Quality
Shuchang Tao, Liuyi Yao, Hanxing Ding, Yuexiang Xie, Qi Cao, Fei Sun, Jinyang Gao, Huawei Shen, Bolin Ding
Despite the success of large language models (LLMs) in natural language generation, much evidence shows that LLMs may produce incorrect or nonsensical text. This limitation highlights the importance of discerning when to trust LLMs, especially in safety-critical domains. Existing methods often express reliability by confidence level, however, their effectiveness is limited by the lack of objective guidance. To address this, we propose CONfidence-Quality-ORDer-preserving alignment approach (CONQORD), which leverages reinforcement learning guided by a tailored dual-component reward function. This function integrates quality reward and order-preserving alignment reward functions. Specifically, the order-preserving reward incentivizes the model to verbalize greater confidence for responses of higher quality to align the order of confidence and quality. Experiments demonstrate that CONQORD significantly improves the alignment performance between confidence and response accuracy, without causing over-cautious. Furthermore, the aligned confidence provided by CONQORD informs when to trust LLMs, and acts as a determinant for initiating the retrieval process of external knowledge. Aligning confidence with response quality ensures more transparent and reliable responses, providing better trustworthiness.
Read more6/11/2024

0
Confidence Under the Hood: An Investigation into the Confidence-Probability Alignment in Large Language Models
Abhishek Kumar, Robert Morabito, Sanzhar Umbet, Jad Kabbara, Ali Emami
As the use of Large Language Models (LLMs) becomes more widespread, understanding their self-evaluation of confidence in generated responses becomes increasingly important as it is integral to the reliability of the output of these models. We introduce the concept of Confidence-Probability Alignment, that connects an LLM's internal confidence, quantified by token probabilities, to the confidence conveyed in the model's response when explicitly asked about its certainty. Using various datasets and prompting techniques that encourage model introspection, we probe the alignment between models' internal and expressed confidence. These techniques encompass using structured evaluation scales to rate confidence, including answer options when prompting, and eliciting the model's confidence level for outputs it does not recognize as its own. Notably, among the models analyzed, OpenAI's GPT-4 showed the strongest confidence-probability alignment, with an average Spearman's $hat{rho}$ of 0.42, across a wide range of tasks. Our work contributes to the ongoing efforts to facilitate risk assessment in the application of LLMs and to further our understanding of model trustworthiness.
Read more6/18/2024
0
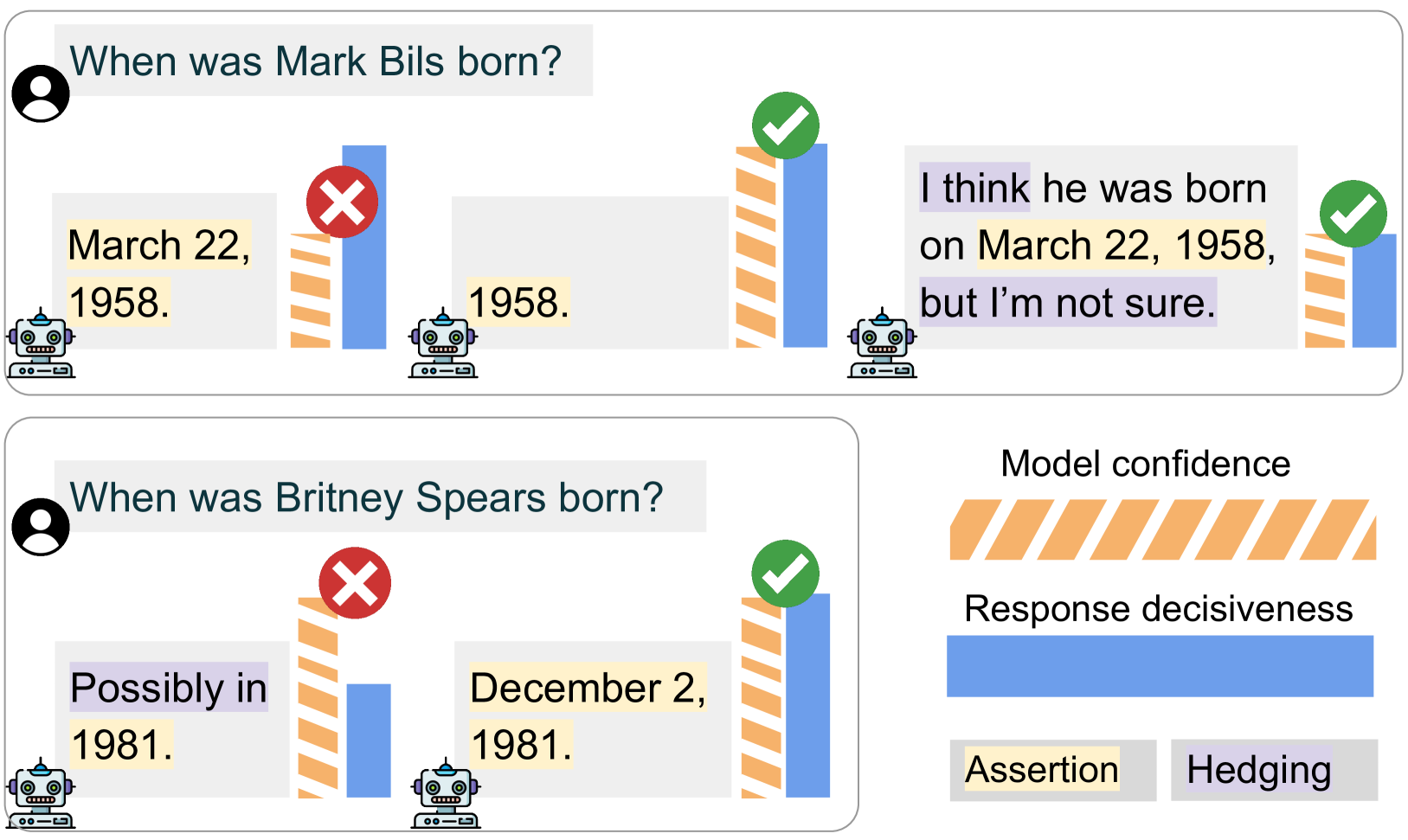
Can Large Language Models Faithfully Express Their Intrinsic Uncertainty in Words?
Gal Yona, Roee Aharoni, Mor Geva
We posit that large language models (LLMs) should be capable of expressing their intrinsic uncertainty in natural language. For example, if the LLM is equally likely to output two contradicting answers to the same question, then its generated response should reflect this uncertainty by hedging its answer (e.g., I'm not sure, but I think...). We formalize faithful response uncertainty based on the gap between the model's intrinsic confidence in the assertions it makes and the decisiveness by which they are conveyed. This example-level metric reliably indicates whether the model reflects its uncertainty, as it penalizes both excessive and insufficient hedging. We evaluate a variety of aligned LLMs at faithfully communicating uncertainty on several knowledge-intensive question answering tasks. Our results provide strong evidence that modern LLMs are poor at faithfully conveying their uncertainty, and that better alignment is necessary to improve their trustworthiness.
Read more9/27/2024

0
TrustScore: Reference-Free Evaluation of LLM Response Trustworthiness
Danna Zheng, Danyang Liu, Mirella Lapata, Jeff Z. Pan
Large Language Models (LLMs) have demonstrated impressive capabilities across various domains, prompting a surge in their practical applications. However, concerns have arisen regarding the trustworthiness of LLMs outputs, particularly in closed-book question-answering tasks, where non-experts may struggle to identify inaccuracies due to the absence of contextual or ground truth information. This paper introduces TrustScore, a framework based on the concept of Behavioral Consistency, which evaluates whether an LLMs response aligns with its intrinsic knowledge. Additionally, TrustScore can seamlessly integrate with fact-checking methods, which assesses alignment with external knowledge sources. The experimental results show that TrustScore achieves strong correlations with human judgments, surpassing existing reference-free metrics, and achieving results on par with reference-based metrics.
Read more5/8/2024