In-Context Editing: Learning Knowledge from Self-Induced Distributions

0

Sign in to get full access
Overview
- This paper explores a novel approach called "In-Context Editing" (ICE) for large language models (LLMs) to learn knowledge from self-induced distributions.
- The key idea is to train LLMs to edit their own outputs, allowing them to learn new knowledge and skills through iterative self-improvement.
- The authors demonstrate the effectiveness of ICE on a variety of tasks, including knowledge probing, few-shot learning, and zero-shot learning.
Plain English Explanation
The paper describes a new way for large language models (LLMs) to learn and improve themselves. Traditionally, LLMs are trained on existing data, which limits their knowledge to what's available in the training set. The In-Context Editing: Learning Knowledge from Self-Induced Distributions approach allows the models to learn new information by editing their own outputs.
The process works like this: the LLM generates some text, then it's trained to edit that text to make it better. By repeatedly going through this cycle of generating and improving its own outputs, the model can gradually expand its knowledge and skills. This self-improvement process enables the LLM to learn things that weren't necessarily present in the original training data.
The researchers demonstrate that this In-Context Editing (ICE) approach is effective for a range of tasks, including answering questions that test the model's knowledge, learning new concepts from just a few examples, and even tackling completely new problems it hasn't been trained on before. This suggests that ICE could be a powerful way to create more capable and adaptable language models.
Technical Explanation
The In-Context Editing: Learning Knowledge from Self-Induced Distributions paper introduces a novel training paradigm called "In-Context Editing" (ICE) for large language models (LLMs). The key idea is to enable LLMs to learn new knowledge and skills by iteratively editing their own outputs.
Traditionally, LLMs are trained on existing datasets, which limits their knowledge to what's present in the training data. In contrast, the ICE approach allows the model to generate its own text, then learn to improve that text through an editing process. By repeatedly going through this cycle of generation and editing, the model can gradually expand its capabilities.
The authors formalize the ICE training process as a two-stage framework. First, the model generates an initial output based on some input context. Then, the model is trained to edit this output to make it better, using a combination of the original input and the model's own generated text as the training signal.
The researchers demonstrate the effectiveness of ICE on a variety of tasks, including knowledge probing, few-shot learning, and zero-shot learning. For example, they show that LLMs trained with ICE can answer a wider range of factual questions and learn new concepts from just a few examples, compared to standard training approaches.
The InstructEdit and NICE papers explore similar ideas of using instructions or quality estimation to guide the context learning process for LLMs, which can be seen as complementary to the ICE approach.
Critical Analysis
The In-Context Editing: Learning Knowledge from Self-Induced Distributions paper presents a promising approach for enhancing the capabilities of large language models. By enabling LLMs to learn from their own generated outputs, the ICE method can potentially address some of the limitations of traditional training on fixed datasets.
One notable aspect is the model's ability to learn new knowledge and skills that may not have been present in the original training data. This suggests that ICE could be a valuable tool for developing more adaptable and generally capable language models.
However, the paper also acknowledges several caveats and limitations. For example, the authors note that the ICE approach can be computationally expensive, as it requires the model to generate and edit its own outputs during training. Additionally, the paper does not explore the potential for the ICE process to introduce biases or errors into the model's knowledge base.
Further research would be needed to address these concerns and fully understand the implications of the ICE approach. The Adapting Large Multimodal Models to Distribution Shifts and Guiding Context Learning LLMs Through Quality Estimation papers explore related topics that could provide valuable insights.
Conclusion
The In-Context Editing: Learning Knowledge from Self-Induced Distributions paper presents an innovative approach called In-Context Editing (ICE) that enables large language models to learn new knowledge and skills by iteratively editing their own outputs.
By allowing LLMs to generate and improve their own text, the ICE method can potentially overcome the limitations of traditional training on fixed datasets. The researchers demonstrate the effectiveness of this approach on a variety of tasks, suggesting that ICE could be a powerful tool for developing more capable and adaptable language models.
While the paper acknowledges some caveats and areas for further research, the ICE concept represents an exciting advancement in the field of large language models. As the capabilities of these models continue to evolve, approaches like ICE will likely play an increasingly important role in pushing the boundaries of what is possible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
In-Context Editing: Learning Knowledge from Self-Induced Distributions
Siyuan Qi, Bangcheng Yang, Kailin Jiang, Xiaobo Wang, Jiaqi Li, Yifan Zhong, Yaodong Yang, Zilong Zheng
The existing fine-tuning paradigm for language models is brittle in knowledge editing scenarios, where the model must incorporate new information without extensive retraining. This brittleness often results in overfitting, reduced performance, and unnatural language generation. To address this, we propose Consistent In-Context Editing (ICE), a novel approach that leverages the model's in-context learning capability to tune toward a contextual distribution rather than a one-hot target. ICE introduces a straightforward optimization framework that includes both a target and a procedure, enhancing the robustness and effectiveness of gradient-based tuning methods. We provide analytical insights into ICE across four critical aspects of knowledge editing: accuracy, locality, generalization, and linguistic quality, showing its advantages. Experimental results across four datasets confirm the effectiveness of ICE and demonstrate its potential for continual editing, ensuring that updated information is incorporated while preserving the integrity of the model.
Read more6/18/2024

0
Decoding by Contrasting Knowledge: Enhancing LLMs' Confidence on Edited Facts
Baolong Bi, Shenghua Liu, Lingrui Mei, Yiwei Wang, Pengliang Ji, Xueqi Cheng
The knowledge within large language models (LLMs) may become outdated quickly. While in-context editing (ICE) is currently the most effective method for knowledge editing (KE), it is constrained by the black-box modeling of LLMs and thus lacks interpretability. Our work aims to elucidate the superior performance of ICE on the KE by analyzing the impacts of in-context new knowledge on token-wise distributions. We observe that despite a significant boost in logits of the new knowledge, the performance of is still hindered by stubborn knowledge. Stubborn knowledge refers to as facts that have gained excessive confidence during pretraining, making it hard to edit effectively. To address this issue and further enhance the performance of ICE, we propose a novel approach termed $textbf{De}$coding by $textbf{C}$ontrasting $textbf{K}$nowledge (DeCK). DeCK derives the distribution of the next token by contrasting the logits obtained from the newly edited knowledge guided by ICE with those from the unedited parametric knowledge. Our experiments consistently demonstrate that DeCK enhances the confidence of LLMs in edited facts. For instance, it improves the performance of LLaMA3-8B-instruct on MQuAKE by up to 219%, demonstrating its capability to strengthen ICE in the editing of stubborn knowledge. Our work paves the way to develop the both effective and accountable KE methods for LLMs. (The source code is available at: https://deck-llm.meirtz.com)
Read more5/22/2024
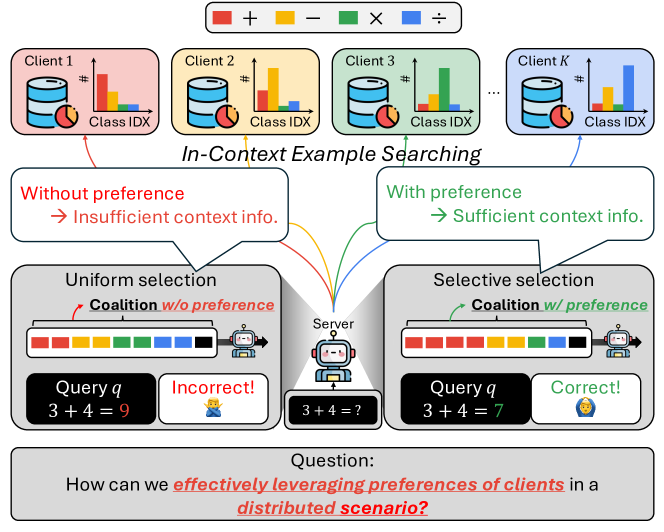
0
Distributed In-Context Learning under Non-IID Among Clients
Siqi Liang, Sumyeong Ahn, Jiayu Zhou
Advancements in large language models (LLMs) have shown their effectiveness in multiple complicated natural language reasoning tasks. A key challenge remains in adapting these models efficiently to new or unfamiliar tasks. In-context learning (ICL) provides a promising solution for few-shot adaptation by retrieving a set of data points relevant to a query, called in-context examples (ICE), from a training dataset and providing them during the inference as context. Most existing studies utilize a centralized training dataset, yet many real-world datasets may be distributed among multiple clients, and remote data retrieval can be associated with costs. Especially when the client data are non-identical independent distributions (non-IID), retrieving from clients a proper set of ICEs needed for a test query presents critical challenges. In this paper, we first show that in this challenging setting, test queries will have different preferences among clients because of non-IIDness, and equal contribution often leads to suboptimal performance. We then introduce a novel approach to tackle the distributed non-IID ICL problem when a data usage budget is present. The principle is that each client's proper contribution (budget) should be designed according to the preference of each query for that client. Our approach uses a data-driven manner to allocate a budget for each client, tailored to each test query. Through extensive empirical studies on diverse datasets, our framework demonstrates superior performance relative to competing baselines.
Read more8/2/2024
💬
3
InstructEdit: Instruction-based Knowledge Editing for Large Language Models
Ningyu Zhang, Bozhong Tian, Siyuan Cheng, Xiaozhuan Liang, Yi Hu, Kouying Xue, Yanjie Gou, Xi Chen, Huajun Chen
Knowledge editing for large language models can offer an efficient solution to alter a model's behavior without negatively impacting the overall performance. However, the current approaches encounter issues with limited generalizability across tasks, necessitating one distinct editor for each task, significantly hindering the broader applications. To address this, we take the first step to analyze the multi-task generalization issue in knowledge editing. Specifically, we develop an instruction-based editing technique, termed InstructEdit, which facilitates the editor's adaptation to various task performances simultaneously using simple instructions. With only one unified editor for each LLM, we empirically demonstrate that InstructEdit can improve the editor's control, leading to an average 14.86% increase in Reliability in multi-task editing setting. Furthermore, experiments involving holdout unseen task illustrate that InstructEdit consistently surpass previous strong baselines. To further investigate the underlying mechanisms of instruction-based knowledge editing, we analyze the principal components of the editing gradient directions, which unveils that instructions can help control optimization direction with stronger OOD generalization. Code and datasets are available in https://github.com/zjunlp/EasyEdit.
Read more4/30/2024