Decoding by Contrasting Knowledge: Enhancing LLMs' Confidence on Edited Facts

0

Sign in to get full access
Overview
- This paper proposes a new approach called "Decoding by Contrasting Knowledge" to enhance the confidence of large language models (LLMs) on edited facts.
- The key idea is to leverage the knowledge captured in the LLM to detect and correct inconsistencies in the model's output when presented with edited facts.
- The authors demonstrate the effectiveness of their approach on the MLaKE benchmark, which evaluates the ability of LLMs to handle factual edits.
Plain English Explanation
The paper addresses an important challenge with large language models (LLMs) - their tendency to generate outputs that may conflict with facts that have been edited or changed. This can be problematic when LLMs are used in applications where accurate information is critical, such as news reporting or medical diagnosis.
The researchers' proposed solution, "Decoding by Contrasting Knowledge," works by tapping into the knowledge already captured within the LLM. When presented with an edited fact, the model compares its own understanding of the information to the edited version. By identifying and resolving these inconsistencies, the model can improve its confidence in the corrected facts.
This approach was tested on the MLaKE benchmark, which specifically evaluates an LLM's ability to handle factual edits. The results demonstrate that the "Decoding by Contrasting Knowledge" method can effectively enhance the model's performance in this challenging scenario.
Technical Explanation
The paper introduces a new technique called "Decoding by Contrasting Knowledge" to improve the confidence of large language models (LLMs) when dealing with edited facts. The key idea is to leverage the knowledge captured within the LLM to detect and correct inconsistencies between the model's understanding and the edited information.
The authors first describe the MLaKE benchmark, which provides a standardized way to evaluate an LLM's ability to handle factual edits. This benchmark presents the model with a statement and an edited version of that statement, and the model is tasked with detecting and correcting the edits.
The "Decoding by Contrasting Knowledge" approach works by having the LLM generate two outputs: one based on the original statement and one based on the edited statement. The model then compares these two outputs to identify any inconsistencies. By resolving these inconsistencies, the model can increase its confidence in the corrected facts.
The authors evaluate their approach on the MLaKE benchmark using several state-of-the-art LLMs, including GPT-3 and Megatron-LM. The results demonstrate that the "Decoding by Contrasting Knowledge" method significantly improves the models' performance in detecting and correcting edited facts, outperforming other techniques such as fine-tuning on edited data.
Critical Analysis
The paper presents a novel and promising approach to enhance the reliability of large language models in the face of edited facts. By leveraging the models' own knowledge, the "Decoding by Contrasting Knowledge" method offers a way to detect and correct inconsistencies, which is a valuable capability for real-world applications where factual accuracy is critical.
One potential limitation of the approach is that it relies on the LLM's existing knowledge being accurate and comprehensive enough to identify and resolve the inconsistencies. If the model's knowledge is incomplete or biased, it may struggle to effectively detect and correct the edited facts. Additionally, the method may not be as effective for more complex or nuanced edits that require a deeper understanding of the context and semantics.
Further research could explore ways to combine this knowledge-contrasting approach with other techniques, such as knowledge editing or bias mitigation, to create a more robust and comprehensive solution for enhancing the reliability of LLMs. Additionally, studies on the limitations and pitfalls of knowledge editing could provide valuable insights for refining the "Decoding by Contrasting Knowledge" method.
Conclusion
This paper presents a novel approach called "Decoding by Contrasting Knowledge" that leverages the internal knowledge of large language models to enhance their confidence in handling edited facts. The method has been demonstrated to be effective on the MLaKE benchmark, which specifically evaluates an LLM's ability to detect and correct factual edits.
The "Decoding by Contrasting Knowledge" technique offers a promising way to improve the reliability and trustworthiness of LLMs, particularly in applications where accurate information is crucial. By tapping into the models' own understanding of the world, this approach represents an important step towards enhancing the contextual understanding of large language models and achieving more reliable latent knowledge estimation - critical goals for the continued development and deployment of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Decoding by Contrasting Knowledge: Enhancing LLMs' Confidence on Edited Facts
Baolong Bi, Shenghua Liu, Lingrui Mei, Yiwei Wang, Pengliang Ji, Xueqi Cheng
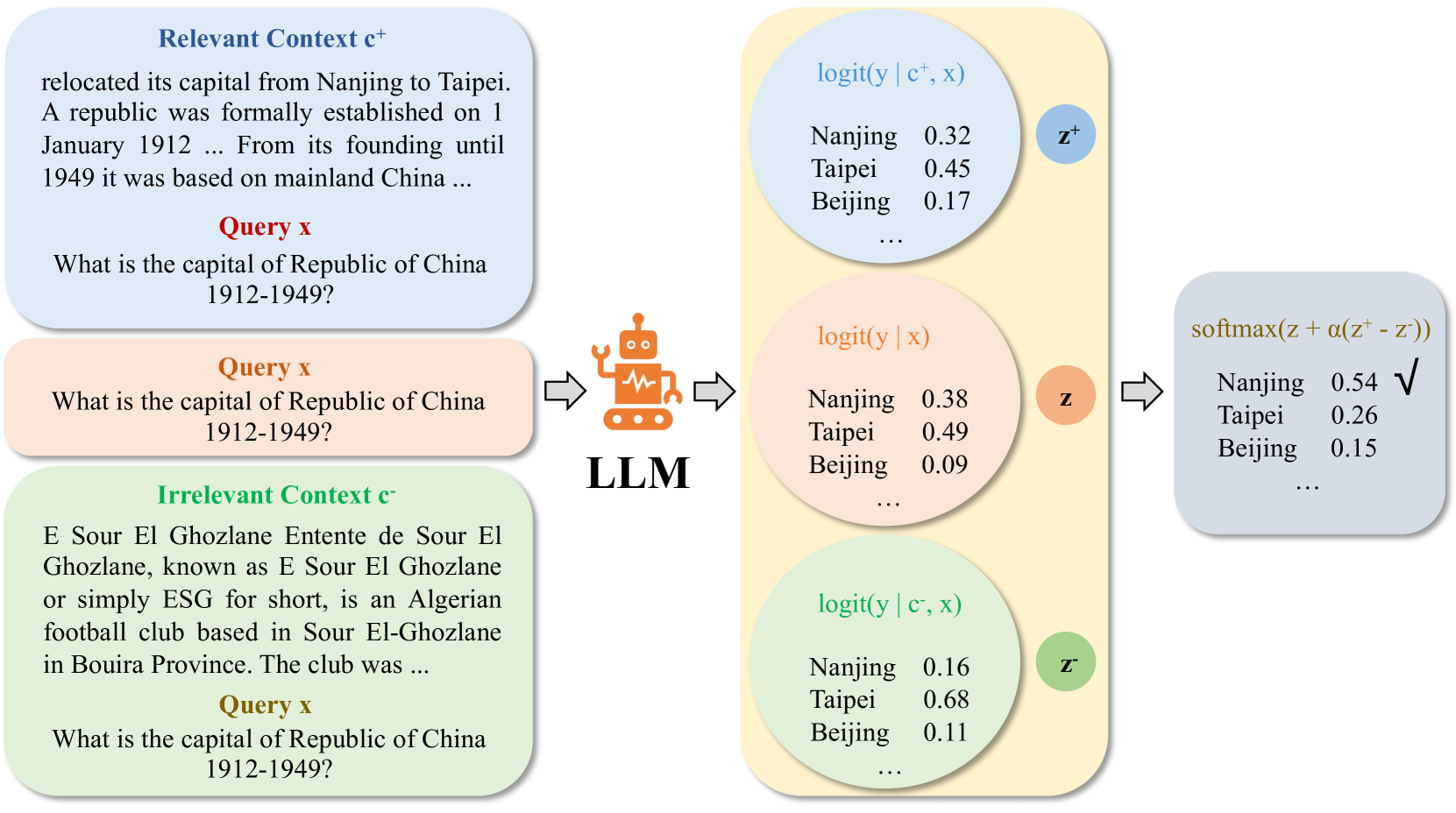
The knowledge within large language models (LLMs) may become outdated quickly. While in-context editing (ICE) is currently the most effective method for knowledge editing (KE), it is constrained by the black-box modeling of LLMs and thus lacks interpretability. Our work aims to elucidate the superior performance of ICE on the KE by analyzing the impacts of in-context new knowledge on token-wise distributions. We observe that despite a significant boost in logits of the new knowledge, the performance of is still hindered by stubborn knowledge. Stubborn knowledge refers to as facts that have gained excessive confidence during pretraining, making it hard to edit effectively. To address this issue and further enhance the performance of ICE, we propose a novel approach termed $textbf{De}$coding by $textbf{C}$ontrasting $textbf{K}$nowledge (DeCK). DeCK derives the distribution of the next token by contrasting the logits obtained from the newly edited knowledge guided by ICE with those from the unedited parametric knowledge. Our experiments consistently demonstrate that DeCK enhances the confidence of LLMs in edited facts. For instance, it improves the performance of LLaMA3-8B-instruct on MQuAKE by up to 219%, demonstrating its capability to strengthen ICE in the editing of stubborn knowledge. Our work paves the way to develop the both effective and accountable KE methods for LLMs. (The source code is available at: https://deck-llm.meirtz.com)
Read more5/22/2024
0
Enhancing Contextual Understanding in Large Language Models through Contrastive Decoding
Zheng Zhao, Emilio Monti, Jens Lehmann, Haytham Assem
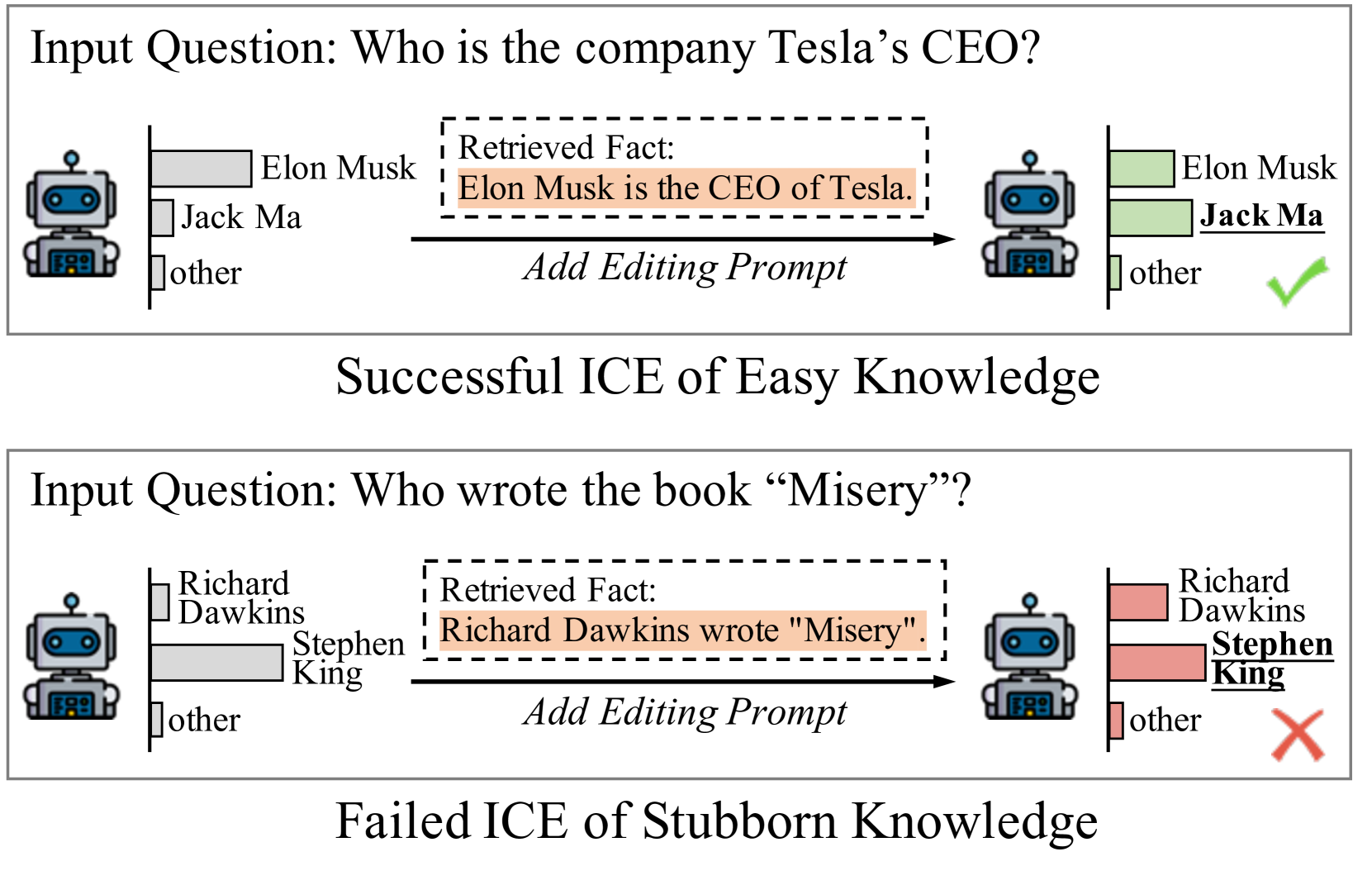
Large language models (LLMs) tend to inadequately integrate input context during text generation, relying excessively on encoded prior knowledge in model parameters, potentially resulting in generated text with factual inconsistencies or contextually unfaithful content. LLMs utilize two primary knowledge sources: 1) prior (parametric) knowledge from pretraining, and 2) contextual (non-parametric) knowledge from input prompts. The study addresses the open question of how LLMs effectively balance these knowledge sources during the generation process, specifically in the context of open-domain question answering. To address this issue, we introduce a novel approach integrating contrastive decoding with adversarial irrelevant passages as negative samples to enhance robust context grounding during generation. Notably, our method operates at inference time without requiring further training. We conduct comprehensive experiments to demonstrate its applicability and effectiveness, providing empirical evidence showcasing its superiority over existing methodologies. Our code is publicly available at: https://github.com/amazon-science/ContextualUnderstanding-ContrastiveDecoding.
Read more5/7/2024
0
Adaptive Token Biaser: Knowledge Editing via Biasing Key Entities
Baolong Bi, Shenghua Liu, Yiwei Wang, Lingrui Mei, Hongcheng Gao, Yilong Xu, Xueqi Cheng
The parametric knowledge memorized by large language models (LLMs) becomes outdated quickly. In-context editing (ICE) is currently the most effective method for updating the knowledge of LLMs. Recent advancements involve enhancing ICE by modifying the decoding strategy, obviating the need for altering internal model structures or adjusting external prompts. However, this enhancement operates across the entire sequence generation, encompassing a plethora of non-critical tokens. In this work, we introduce $textbf{A}$daptive $textbf{T}$oken $textbf{Bias}$er ($textbf{ATBias}$), a new decoding technique designed to enhance ICE. It focuses on the tokens that are mostly related to knowledge during decoding, biasing their logits by matching key entities related to new and parametric knowledge. Experimental results show that ATBias significantly enhances ICE performance, achieving up to a 32.3% improvement over state-of-the-art ICE methods while incurring only half the latency. ATBias not only improves the knowledge editing capabilities of ICE but can also be widely applied to LLMs with negligible cost.
Read more6/19/2024

0
In-Context Editing: Learning Knowledge from Self-Induced Distributions
Siyuan Qi, Bangcheng Yang, Kailin Jiang, Xiaobo Wang, Jiaqi Li, Yifan Zhong, Yaodong Yang, Zilong Zheng
The existing fine-tuning paradigm for language models is brittle in knowledge editing scenarios, where the model must incorporate new information without extensive retraining. This brittleness often results in overfitting, reduced performance, and unnatural language generation. To address this, we propose Consistent In-Context Editing (ICE), a novel approach that leverages the model's in-context learning capability to tune toward a contextual distribution rather than a one-hot target. ICE introduces a straightforward optimization framework that includes both a target and a procedure, enhancing the robustness and effectiveness of gradient-based tuning methods. We provide analytical insights into ICE across four critical aspects of knowledge editing: accuracy, locality, generalization, and linguistic quality, showing its advantages. Experimental results across four datasets confirm the effectiveness of ICE and demonstrate its potential for continual editing, ensuring that updated information is incorporated while preserving the integrity of the model.
Read more6/18/2024