A Contextual Combinatorial Bandit Approach to Negotiation

0

Sign in to get full access
Overview
- This paper presents a novel approach to negotiation using a contextual combinatorial bandit framework.
- The proposed method allows an agent to learn optimal negotiation strategies based on the context of the negotiation, such as the opponent's preferences and the available negotiation items.
- The authors demonstrate the effectiveness of their approach through simulations and real-world negotiation experiments.
Plain English Explanation
In the world of negotiations, it can be challenging for an agent to determine the best strategy to use. The context of the negotiation, such as the preferences of the other party and the available items for negotiation, can have a significant impact on the optimal approach.
The researchers in this paper have developed a new technique that allows an agent to learn the best negotiation strategies based on the context of the situation. They use a contextual combinatorial bandit framework, which is a type of machine learning algorithm that can adaptively learn the optimal actions to take in a dynamic environment.
The key idea is that the agent can explore different negotiation strategies and learn which ones work best for different negotiation contexts. This allows the agent to tailor its approach to the specific situation, rather than relying on a one-size-fits-all strategy.
The researchers demonstrate the effectiveness of their approach through a series of simulations and real-world negotiation experiments. They show that their method outperforms other negotiation strategies in terms of the outcomes achieved.
This research has important implications for the field of negotiation, as it offers a way to improve the performance of negotiating agents in a wide range of contexts. By using a contextual combinatorial bandit approach, agents can learn to negotiate more effectively and achieve better outcomes for their stakeholders.
Technical Explanation
The authors propose a contextual combinatorial bandit approach to negotiation, where the agent adapts its negotiation strategy based on the current context of the negotiation.
The key components of the proposed framework are:
-
Negotiation Context: The agent's negotiation strategy is influenced by the current context, which includes the preferences of the opponent, the available negotiation items, and other relevant factors.
-
Combinatorial Action Space: The agent's negotiation strategy is represented as a combination of actions, such as proposing certain items or making specific offers.
-
Contextual Bandit Learning: The agent uses a contextual bandit algorithm to adaptively learn the optimal negotiation strategy based on the observed outcomes and the current negotiation context.
The authors evaluate their approach through both simulations and real-world negotiation experiments. In the simulations, they compare the performance of their method to other negotiation strategies, such as fixed-strategy approaches and negotiation models based on game theory.
In the real-world experiments, the authors implement their framework in a distributed multi-task learning setting, where multiple agents negotiate simultaneously and share their learned strategies.
The results demonstrate that the proposed contextual combinatorial bandit approach outperforms the baseline methods in terms of the negotiation outcomes achieved. The authors attribute this success to the ability of their method to adapt the negotiation strategy to the specific context of the negotiation.
Critical Analysis
The authors have presented a novel and promising approach to negotiation using a contextual combinatorial bandit framework. The use of a contextual bandit algorithm allows the agent to learn the optimal negotiation strategy based on the current context, which is a significant advancement over traditional fixed-strategy approaches.
However, the authors acknowledge several limitations of their study. First, the simulations and experiments were conducted in relatively simple negotiation scenarios, and it is unclear how the method would scale to more complex, real-world negotiations with multiple parties and a larger set of negotiation items.
Additionally, the authors do not address the potential ethical implications of using an automated negotiation agent in sensitive or high-stakes negotiations, such as those involving legal or financial contracts. There are concerns about the transparency and accountability of such systems, as well as the potential for them to be used to exploit or manipulate human negotiators.
Further research is needed to explore these issues and to better understand the practical applications and limitations of the contextual combinatorial bandit approach to negotiation. Specifically, evaluating the method in more realistic and complex negotiation scenarios, and investigating the ethical considerations of deploying such systems, would be valuable next steps.
Conclusion
This paper presents a novel approach to negotiation using a contextual combinatorial bandit framework. The proposed method allows an agent to adaptively learn the optimal negotiation strategy based on the current context of the negotiation, such as the preferences of the opponent and the available negotiation items.
The authors demonstrate the effectiveness of their approach through simulations and real-world negotiation experiments, showing that it outperforms other negotiation strategies in terms of the outcomes achieved. This research has important implications for the field of negotiation, as it offers a way to improve the performance of negotiating agents in a wide range of contexts.
However, the authors acknowledge several limitations of their study, and further research is needed to explore the practical applications and ethical considerations of deploying such systems in real-world negotiations. Overall, this paper represents an exciting advancement in the field of automated negotiation and opens up new avenues for future research and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Contextual Combinatorial Bandit Approach to Negotiation
Yexin Li, Zhancun Mu, Siyuan Qi
Learning effective negotiation strategies poses two key challenges: the exploration-exploitation dilemma and dealing with large action spaces. However, there is an absence of learning-based approaches that effectively address these challenges in negotiation. This paper introduces a comprehensive formulation to tackle various negotiation problems. Our approach leverages contextual combinatorial multi-armed bandits, with the bandits resolving the exploration-exploitation dilemma, and the combinatorial nature handles large action spaces. Building upon this formulation, we introduce NegUCB, a novel method that also handles common issues such as partial observations and complex reward functions in negotiation. NegUCB is contextual and tailored for full-bandit feedback without constraints on the reward functions. Under mild assumptions, it ensures a sub-linear regret upper bound. Experiments conducted on three negotiation tasks demonstrate the superiority of our approach.
Read more7/2/2024

0
Neural Dueling Bandits
Arun Verma, Zhongxiang Dai, Xiaoqiang Lin, Patrick Jaillet, Bryan Kian Hsiang Low
Contextual dueling bandit is used to model the bandit problems, where a learner's goal is to find the best arm for a given context using observed noisy preference feedback over the selected arms for the past contexts. However, existing algorithms assume the reward function is linear, which can be complex and non-linear in many real-life applications like online recommendations or ranking web search results. To overcome this challenge, we use a neural network to estimate the reward function using preference feedback for the previously selected arms. We propose upper confidence bound- and Thompson sampling-based algorithms with sub-linear regret guarantees that efficiently select arms in each round. We then extend our theoretical results to contextual bandit problems with binary feedback, which is in itself a non-trivial contribution. Experimental results on the problem instances derived from synthetic datasets corroborate our theoretical results.
Read more7/25/2024
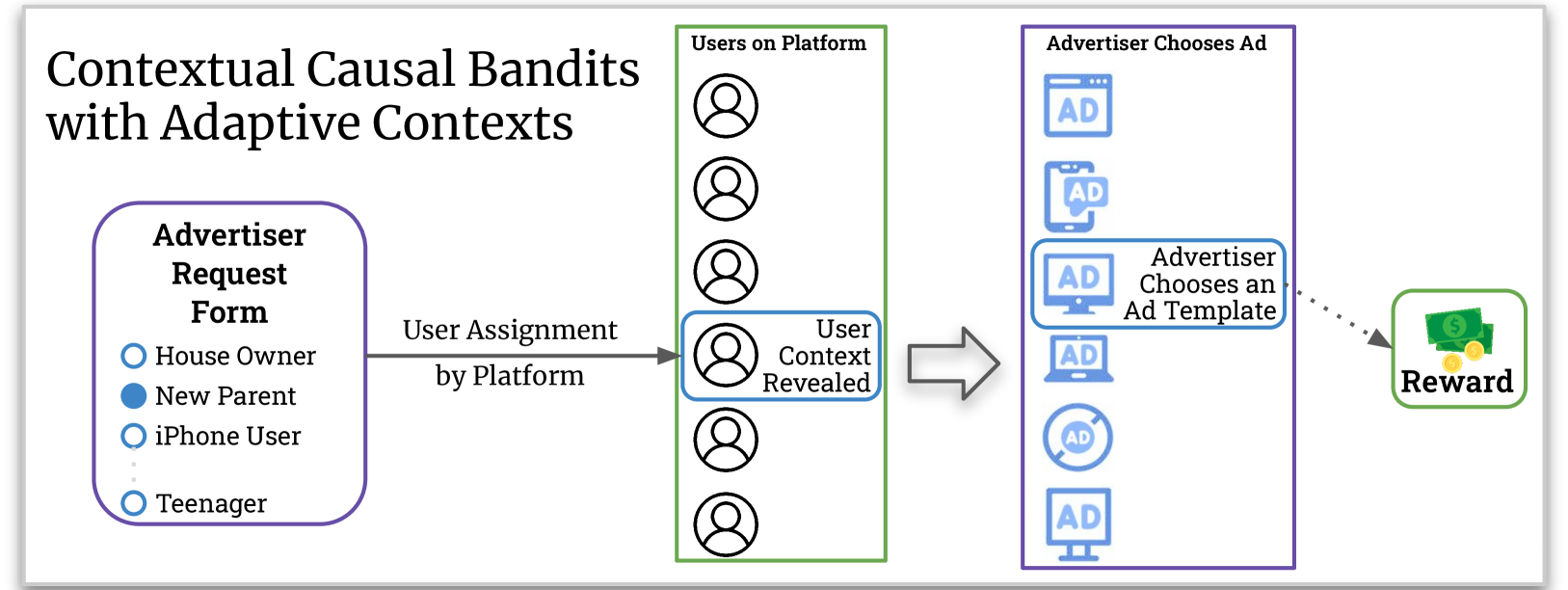
0
Causal Contextual Bandits with Adaptive Context
Rahul Madhavan, Aurghya Maiti, Gaurav Sinha, Siddharth Barman
We study a variant of causal contextual bandits where the context is chosen based on an initial intervention chosen by the learner. At the beginning of each round, the learner selects an initial action, depending on which a stochastic context is revealed by the environment. Following this, the learner then selects a final action and receives a reward. Given $T$ rounds of interactions with the environment, the objective of the learner is to learn a policy (of selecting the initial and the final action) with maximum expected reward. In this paper we study the specific situation where every action corresponds to intervening on a node in some known causal graph. We extend prior work from the deterministic context setting to obtain simple regret minimization guarantees. This is achieved through an instance-dependent causal parameter, $lambda$, which characterizes our upper bound. Furthermore, we prove that our simple regret is essentially tight for a large class of instances. A key feature of our work is that we use convex optimization to address the bandit exploration problem. We also conduct experiments to validate our theoretical results, and release our code at our project GitHub repository: https://github.com/adaptiveContextualCausalBandits/aCCB.
Read more6/4/2024

0
Linear Contextual Bandits with Hybrid Payoff: Revisited
Nirjhar Das, Gaurav Sinha
We study the Linear Contextual Bandit problem in the hybrid reward setting. In this setting every arm's reward model contains arm specific parameters in addition to parameters shared across the reward models of all the arms. We can reduce this setting to two closely related settings (a) Shared - no arm specific parameters, and (b) Disjoint - only arm specific parameters, enabling the application of two popular state of the art algorithms - $texttt{LinUCB}$ and $texttt{DisLinUCB}$ (Algorithm 1 in (Li et al. 2010)). When the arm features are stochastic and satisfy a popular diversity condition, we provide new regret analyses for both algorithms, significantly improving on the known regret guarantees of these algorithms. Our novel analysis critically exploits the hybrid reward structure and the diversity condition. Moreover, we introduce a new algorithm $texttt{HyLinUCB}$ that crucially modifies $texttt{LinUCB}$ (using a new exploration coefficient) to account for sparsity in the hybrid setting. Under the same diversity assumptions, we prove that $texttt{HyLinUCB}$ also incurs only $O(sqrt{T})$ regret for $T$ rounds. We perform extensive experiments on synthetic and real-world datasets demonstrating strong empirical performance of $texttt{HyLinUCB}$.For number of arm specific parameters much larger than the number of shared parameters, we observe that $texttt{DisLinUCB}$ incurs the lowest regret. In this case, regret of $texttt{HyLinUCB}$ is the second best and extremely competitive to $texttt{DisLinUCB}$. In all other situations, including our real-world dataset, $texttt{HyLinUCB}$ has significantly lower regret than $texttt{LinUCB}$, $texttt{DisLinUCB}$ and other SOTA baselines we considered. We also empirically observe that the regret of $texttt{HyLinUCB}$ grows much slower with the number of arms compared to baselines, making it suitable even for very large action spaces.
Read more9/5/2024