Contrastive UCB: Provably Efficient Contrastive Self-Supervised Learning in Online Reinforcement Learning
2207.14800
0
0
🏅
Abstract
In view of its power in extracting feature representation, contrastive self-supervised learning has been successfully integrated into the practice of (deep) reinforcement learning (RL), leading to efficient policy learning in various applications. Despite its tremendous empirical successes, the understanding of contrastive learning for RL remains elusive. To narrow such a gap, we study how RL can be empowered by contrastive learning in a class of Markov decision processes (MDPs) and Markov games (MGs) with low-rank transitions. For both models, we propose to extract the correct feature representations of the low-rank model by minimizing a contrastive loss. Moreover, under the online setting, we propose novel upper confidence bound (UCB)-type algorithms that incorporate such a contrastive loss with online RL algorithms for MDPs or MGs. We further theoretically prove that our algorithm recovers the true representations and simultaneously achieves sample efficiency in learning the optimal policy and Nash equilibrium in MDPs and MGs. We also provide empirical studies to demonstrate the efficacy of the UCB-based contrastive learning method for RL. To the best of our knowledge, we provide the first provably efficient online RL algorithm that incorporates contrastive learning for representation learning. Our codes are available at https://github.com/Baichenjia/Contrastive-UCB.
Create account to get full access
Overview
- The paper examines how reinforcement learning (RL) can be improved by incorporating contrastive self-supervised learning, a powerful technique for extracting useful feature representations from data.
- The researchers propose new algorithms that combine contrastive learning with upper confidence bound (UCB)-based RL methods for Markov decision processes (MDPs) and Markov games (MGs) with low-rank transitions.
- They show that these algorithms can efficiently learn the true representations of the low-rank models and simultaneously achieve sample-efficient learning of optimal policies and Nash equilibria.
- The work provides the first provably efficient online RL algorithm that integrates contrastive learning for representation learning.
Plain English Explanation
Reinforcement learning is a powerful AI technique where an agent learns to make good decisions by interacting with an environment and receiving rewards or penalties. However, to make the best decisions, the agent needs to extract meaningful features from the data it observes. Contrastive self-supervised learning is a method that can help with this by learning useful feature representations without needing labeled data.
The researchers in this paper wanted to understand how contrastive learning can be combined with reinforcement learning to improve the agent's decision-making. They focused on a specific type of environment called Markov decision processes (MDPs) and Markov games (MGs), where the underlying model has a low-rank structure.
The key idea is to use contrastive learning to extract the correct low-rank feature representations from the data. The researchers then developed new algorithms that integrate this contrastive loss with upper confidence bound (UCB)-based RL methods. UCB algorithms help the agent explore the environment efficiently to learn the optimal policy or Nash equilibrium.
The researchers proved that their algorithms can recover the true low-rank representations and achieve sample-efficient learning of the optimal policies and Nash equilibria. This is an important result, as it provides the first provably efficient online RL algorithm that combines contrastive learning and reinforcement learning.
Technical Explanation
The paper proposes novel algorithms that integrate contrastive self-supervised learning with upper confidence bound (UCB)-based reinforcement learning (RL) methods for Markov decision processes (MDPs) and Markov games (MGs) with low-rank transitions.
The key idea is to use contrastive learning to extract the correct low-rank feature representations from the data. Contrastive learning is a powerful technique for learning useful feature representations without labeled data, by encouraging the model to distinguish between related and unrelated samples.
The researchers develop two main algorithms:
-
For MDPs with low-rank transitions, they propose a contrastive UCB (C-UCB) algorithm that combines a contrastive loss with the standard UCB method for learning the optimal policy.
-
For Markov games with low-rank transitions, they propose a contrastive Nash-UCB (CN-UCB) algorithm that uses contrastive learning to learn the Nash equilibrium.
Theoretically, the researchers prove that these algorithms can recover the true low-rank representations of the environment and simultaneously achieve sample-efficient learning of the optimal policy or Nash equilibrium. This is an important result, as it provides the first provably efficient online RL algorithm that integrates contrastive learning for representation learning.
The researchers also conduct empirical studies to demonstrate the effectiveness of their UCB-based contrastive learning methods for RL tasks. The results show that the proposed algorithms outperform standard RL baselines, validating the benefits of incorporating contrastive learning into RL.
Critical Analysis
The paper makes a significant contribution by providing a principled way to combine contrastive self-supervised learning with reinforcement learning for efficient policy learning in low-rank Markov decision processes and Markov games.
One potential limitation is that the theoretical analysis assumes the transitions in the MDP or MG have a low-rank structure, which may not always hold in real-world environments. Further research could explore relaxing this assumption or extending the methods to more general settings.
Additionally, the paper focuses on the sample efficiency of the proposed algorithms in terms of learning the true representations and optimal policies/Nash equilibria. While this is an important metric, other factors such as computational efficiency and scalability to large-scale problems could also be considered in future work.
It would also be valuable to see more extensive empirical evaluations, including comparisons to a wider range of RL baselines and contrastive learning methods beyond the UCB-based approaches presented in the paper.
Overall, this paper makes a significant contribution to the understanding of how contrastive learning can be leveraged to improve the performance of reinforcement learning algorithms, particularly in low-rank Markov decision processes and games. The theoretical guarantees and empirical results provide a solid foundation for future research in this direction.
Conclusion
This paper presents a novel approach to integrating contrastive self-supervised learning with reinforcement learning for efficient policy learning in Markov decision processes and Markov games with low-rank transitions. The researchers develop two UCB-based algorithms that can recover the true low-rank representations of the environment and simultaneously achieve sample-efficient learning of optimal policies and Nash equilibria.
The work provides the first provably efficient online RL algorithm that incorporates contrastive learning for representation learning, demonstrating the significant potential of combining these two powerful AI techniques. While the current results are limited to low-rank environments, the insights from this research could inspire further advancements in using contrastive learning to enhance the performance and sample efficiency of reinforcement learning systems more broadly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
❗
Combining Reconstruction and Contrastive Methods for Multimodal Representations in RL
Philipp Becker, Sebastian Mossburger, Fabian Otto, Gerhard Neumann
0
0
Learning self-supervised representations using reconstruction or contrastive losses improves performance and sample complexity of image-based and multimodal reinforcement learning (RL). Here, different self-supervised loss functions have distinct advantages and limitations depending on the information density of the underlying sensor modality. Reconstruction provides strong learning signals but is susceptible to distractions and spurious information. While contrastive approaches can ignore those, they may fail to capture all relevant details and can lead to representation collapse. For multimodal RL, this suggests that different modalities should be treated differently based on the amount of distractions in the signal. We propose Contrastive Reconstructive Aggregated representation Learning (CoRAL), a unified framework enabling us to choose the most appropriate self-supervised loss for each sensor modality and allowing the representation to better focus on relevant aspects. We evaluate CoRAL's benefits on a wide range of tasks with images containing distractions or occlusions, a new locomotion suite, and a challenging manipulation suite with visually realistic distractions. Our results show that learning a multimodal representation by combining contrastive and reconstruction-based losses can significantly improve performance and solve tasks that are out of reach for more naive representation learning approaches and other recent baselines.
6/27/2024
👨🏫
Mixed Supervised Graph Contrastive Learning for Recommendation
Weizhi Zhang, Liangwei Yang, Zihe Song, Henry Peng Zou, Ke Xu, Yuanjie Zhu, Philip S. Yu
0
0
Recommender systems (RecSys) play a vital role in online platforms, offering users personalized suggestions amidst vast information. Graph contrastive learning aims to learn from high-order collaborative filtering signals with unsupervised augmentation on the user-item bipartite graph, which predominantly relies on the multi-task learning framework involving both the pair-wise recommendation loss and the contrastive loss. This decoupled design can cause inconsistent optimization direction from different losses, which leads to longer convergence time and even sub-optimal performance. Besides, the self-supervised contrastive loss falls short in alleviating the data sparsity issue in RecSys as it learns to differentiate users/items from different views without providing extra supervised collaborative filtering signals during augmentations. In this paper, we propose Mixed Supervised Graph Contrastive Learning for Recommendation (MixSGCL) to address these concerns. MixSGCL originally integrates the training of recommendation and unsupervised contrastive losses into a supervised contrastive learning loss to align the two tasks within one optimization direction. To cope with the data sparsity issue, instead unsupervised augmentation, we further propose node-wise and edge-wise mixup to mine more direct supervised collaborative filtering signals based on existing user-item interactions. Extensive experiments on three real-world datasets demonstrate that MixSGCL surpasses state-of-the-art methods, achieving top performance on both accuracy and efficiency. It validates the effectiveness of MixSGCL with our coupled design on supervised graph contrastive learning.
4/29/2024
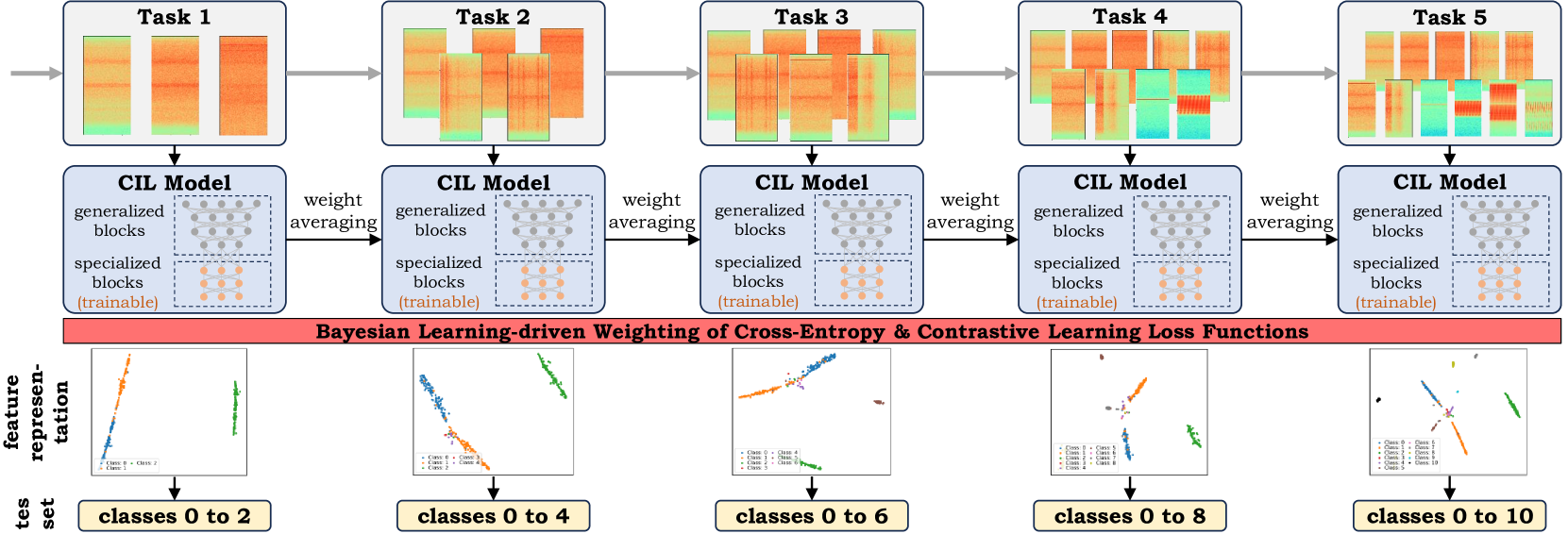
Bayesian Learning-driven Prototypical Contrastive Loss for Class-Incremental Learning
Nisha L. Raichur, Lucas Heublein, Tobias Feigl, Alexander Rugamer, Christopher Mutschler, Felix Ott
0
0
The primary objective of methods in continual learning is to learn tasks in a sequential manner over time from a stream of data, while mitigating the detrimental phenomenon of catastrophic forgetting. In this paper, we focus on learning an optimal representation between previous class prototypes and newly encountered ones. We propose a prototypical network with a Bayesian learning-driven contrastive loss (BLCL) tailored specifically for class-incremental learning scenarios. Therefore, we introduce a contrastive loss that incorporates new classes into the latent representation by reducing the intra-class distance and increasing the inter-class distance. Our approach dynamically adapts the balance between the cross-entropy and contrastive loss functions with a Bayesian learning technique. Empirical evaluations conducted on both the CIFAR-10 dataset for image classification and images of a GNSS-based dataset for interference classification validate the efficacy of our method, showcasing its superiority over existing state-of-the-art approaches.
5/21/2024
🏅
M2CURL: Sample-Efficient Multimodal Reinforcement Learning via Self-Supervised Representation Learning for Robotic Manipulation
Fotios Lygerakis, Vedant Dave, Elmar Rueckert
0
0
One of the most critical aspects of multimodal Reinforcement Learning (RL) is the effective integration of different observation modalities. Having robust and accurate representations derived from these modalities is key to enhancing the robustness and sample efficiency of RL algorithms. However, learning representations in RL settings for visuotactile data poses significant challenges, particularly due to the high dimensionality of the data and the complexity involved in correlating visual and tactile inputs with the dynamic environment and task objectives. To address these challenges, we propose Multimodal Contrastive Unsupervised Reinforcement Learning (M2CURL). Our approach employs a novel multimodal self-supervised learning technique that learns efficient representations and contributes to faster convergence of RL algorithms. Our method is agnostic to the RL algorithm, thus enabling its integration with any available RL algorithm. We evaluate M2CURL on the Tactile Gym 2 simulator and we show that it significantly enhances the learning efficiency in different manipulation tasks. This is evidenced by faster convergence rates and higher cumulative rewards per episode, compared to standard RL algorithms without our representation learning approach.
6/21/2024