A Counterfactual Explanation Framework for Retrieval Models

0
Sign in to get full access
Overview
- This paper presents a counterfactual explanation framework for retrieval models.
- The framework aims to provide users with insights into why a retrieval model made a particular decision.
- The authors demonstrate the framework on two retrieval tasks: ad-hoc retrieval and query-based question answering.
Plain English Explanation
The paper introduces a new way to understand how retrieval models work. Retrieval models are AI systems that search through large amounts of information to find the most relevant content for a user's query.
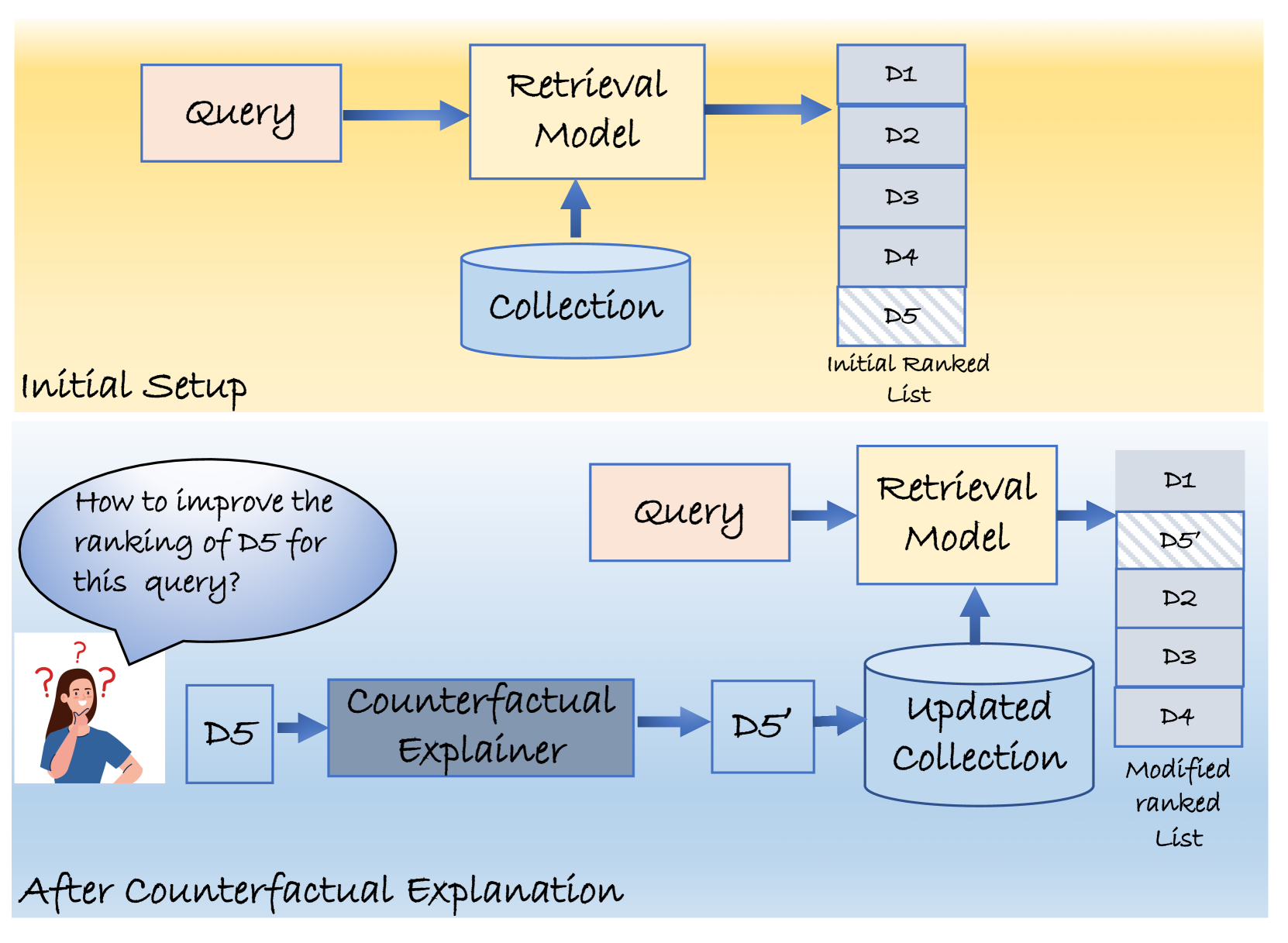
The key idea is to use counterfactual reasoning to explain the model's decisions. Counterfactual reasoning means imagining how the outcome would change if something about the input was different.
For example, if a retrieval model ranked a document highly, the counterfactual explanation would show how the ranking would change if certain words in the query or document were modified. This provides users with insights into what factors the model is focusing on to make its decisions.
The authors demonstrate this framework on two common retrieval tasks: ad-hoc retrieval (finding relevant documents for a general query) and query-based question answering (finding answers to specific questions).
By understanding the reasons behind a retrieval model's choices, users can better assess the model's reliability and potentially improve its robustness to biases or mistakes.
Technical Explanation
The paper presents a counterfactual explanation framework for retrieval models. The key idea is to generate counterfactual versions of the input query or document, and then observe how the model's output changes in response.
For ad-hoc retrieval, the framework generates counterfactual queries by replacing, adding, or removing words from the original query. It then measures how the ranking of retrieved documents changes compared to the original query.
For query-based question answering, the framework generates counterfactual versions of the question or relevant passage, and observes how the model's answer changes. This provides insights into which parts of the input the model is focusing on to generate its answer.
The authors evaluate their framework on two retrieval datasets: MS MARCO for ad-hoc retrieval and QuARC for query-based question answering. They show that the counterfactual explanations can effectively identify the important aspects of the input that drive the model's decisions.
Critical Analysis
The paper makes a compelling case for the value of counterfactual explanations in understanding retrieval models. By highlighting the specific factors that influence a model's outputs, the framework can help users better assess the model's reliability and potential biases.
However, the authors acknowledge some limitations of their approach. The counterfactual examples are generated using simple heuristics, which may not fully capture the nuances of natural language. Additionally, the framework does not address the underlying black-box nature of many retrieval models, which can still limit the interpretability of their decisions.
Further research could explore more sophisticated counterfactual generation techniques, as well as ways to integrate the explanations more seamlessly into the user experience of retrieval systems. Evaluating the framework's effectiveness in real-world applications would also be an important next step.
Conclusion
This paper introduces a novel counterfactual explanation framework for retrieval models. By generating and analyzing counterfactual versions of the input, the framework provides users with insights into the key factors driving a model's decisions.
The authors demonstrate the framework's effectiveness on two retrieval tasks, showing its potential to enhance the transparency and reliability of these AI systems. As retrieval models become increasingly prevalent in our daily lives, tools like this that promote user understanding and trust will be crucial for their responsible development and deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Counterfactual Explanation Framework for Retrieval Models
Bhavik Chandna, Procheta Sen
Explainability has become a crucial concern in today's world, aiming to enhance transparency in machine learning and deep learning models. Information retrieval is no exception to this trend. In existing literature on explainability of information retrieval, the emphasis has predominantly been on illustrating the concept of relevance concerning a retrieval model. The questions addressed include why a document is relevant to a query, why one document exhibits higher relevance than another, or why a specific set of documents is deemed relevant for a query. However, limited attention has been given to understanding why a particular document is considered non-relevant to a query with respect to a retrieval model. In an effort to address this gap, our work focus on the question of what terms need to be added within a document to improve its ranking. This in turn answers the question of which words played a role in not being favored by a retrieval model for a particular query. We use an optimization framework to solve the above-mentioned research problem. % To the best of our knowledge, we mark the first attempt to tackle this specific counterfactual problem. Our experiments show the effectiveness of our proposed approach in predicting counterfactuals for both statistical (e.g. BM25) and deep-learning-based models (e.g. DRMM, DSSM, ColBERT).
Read more9/11/2024
⛏️
0
Counterfactual Editing for Search Result Explanation
Zhichao Xu, Hemank Lamba, Qingyao Ai, Joel Tetreault, Alex Jaimes
Search Result Explanation (SeRE) aims to improve search sessions' effectiveness and efficiency by helping users interpret documents' relevance. Existing works mostly focus on factual explanation, i.e. to find/generate supporting evidence about documents' relevance to search queries. However, research in cognitive sciences has shown that human explanations are contrastive i.e. people explain an observed event using some counterfactual events; such explanations reduce cognitive load and provide actionable insights. Though already proven effective in machine learning and NLP communities, there lacks a strict formulation on how counterfactual explanations should be defined and structured, in the context of web search. In this paper, we first discuss the possible formulation of counterfactual explanations in the IR context. Next, we formulate a suite of desiderata for counterfactual explanation in SeRE task and corresponding automatic metrics. With this desiderata, we propose a method named textbf{C}ountertextbf{F}actual textbf{E}diting for Search Research textbf{E}xplanation (textbf{CFE2}). CFE2 provides pairwise counterfactual explanations for document pairs within a search engine result page. Our experiments on five public search datasets demonstrate that CFE2 can significantly outperform baselines in both automatic metrics and human evaluations.
Read more7/2/2024
🔍
0
Why So Gullible? Enhancing the Robustness of Retrieval-Augmented Models against Counterfactual Noise
Giwon Hong, Jeonghwan Kim, Junmo Kang, Sung-Hyon Myaeng, Joyce Jiyoung Whang
Most existing retrieval-augmented language models (LMs) assume a naive dichotomy within a retrieved document set: query-relevance and irrelevance. Our work investigates a more challenging scenario in which even the relevant documents may contain misleading or incorrect information, causing conflict among the retrieved documents and thereby negatively influencing model decisions as noise. We observe that existing LMs are highly brittle to the presence of conflicting information in both the fine-tuning and in-context few-shot learning scenarios. We propose approaches for handling knowledge conflicts among retrieved documents by explicitly fine-tuning a discriminator or prompting GPT-3.5 to elicit its discriminative capability. Our empirical results on open-domain QA show that these approaches significantly enhance model robustness. We also provide our findings on incorporating the fine-tuned discriminator's decision into the in-context learning process, proposing a way to exploit the benefits of two disparate learning schemes. Alongside our findings, we provide MacNoise, a machine-generated, conflict-induced dataset to further encourage research in this direction.
Read more6/11/2024

0
Axiomatic Causal Interventions for Reverse Engineering Relevance Computation in Neural Retrieval Models
Catherine Chen, Jack Merullo, Carsten Eickhoff
Neural models have demonstrated remarkable performance across diverse ranking tasks. However, the processes and internal mechanisms along which they determine relevance are still largely unknown. Existing approaches for analyzing neural ranker behavior with respect to IR properties rely either on assessing overall model behavior or employing probing methods that may offer an incomplete understanding of causal mechanisms. To provide a more granular understanding of internal model decision-making processes, we propose the use of causal interventions to reverse engineer neural rankers, and demonstrate how mechanistic interpretability methods can be used to isolate components satisfying term-frequency axioms within a ranking model. We identify a group of attention heads that detect duplicate tokens in earlier layers of the model, then communicate with downstream heads to compute overall document relevance. More generally, we propose that this style of mechanistic analysis opens up avenues for reverse engineering the processes neural retrieval models use to compute relevance. This work aims to initiate granular interpretability efforts that will not only benefit retrieval model development and training, but ultimately ensure safer deployment of these models.
Read more5/7/2024