Axiomatic Causal Interventions for Reverse Engineering Relevance Computation in Neural Retrieval Models

0

Sign in to get full access
Overview
This research paper presents a novel approach to reverse engineering the relevance computation in neural retrieval models. The authors use axiomatic causal interventions to gain insights into how these models determine the relevance of a document to a given query. This is an important step towards improving the interpretability of neural ranking systems and making them more robust.
Plain English Explanation
The paper focuses on understanding how neural networks decide which documents are relevant to a user's search query. These neural ranking models are powerful, but they can be "black boxes" - it's not always clear how they arrive at their decisions. The researchers wanted to open up that black box and see what's going on inside.
They did this by using a technique called "axiomatic causal interventions." Essentially, they made carefully controlled changes to the input data and observed how the model's predictions changed. This allowed them to reverse engineer the model's relevance computation and uncover the underlying factors it uses to determine relevance.
For example, they might change a word in the query and see how that affects the model's ranking of the documents. Or they might remove certain features from the document text and observe the impact. By systematically testing these interventions, the researchers were able to gain valuable insights into the model's decision-making process.
This research is important because it can help make neural ranking systems more interpretable and trustworthy. If we understand how these models work, we can identify and fix any biases or flaws they might have. We can also use this knowledge to build better, more robust retrieval systems that are aligned with human notions of relevance.
Technical Explanation
The core of this paper is the use of axiomatic causal interventions to reverse engineer the relevance computation in neural retrieval models. The authors start by defining a set of information retrieval axioms, which are high-level principles that a "well-behaved" retrieval system should satisfy.
They then propose a causal intervention framework that allows them to systematically test whether a neural ranking model adheres to these axioms. The key idea is to make controlled changes to the input (e.g., the query or document text) and observe how the model's output (the relevance score) changes. By analyzing these causal relationships, they can uncover the underlying factors the model uses to determine relevance.
The authors apply this framework to several state-of-the-art neural retrieval models, including BERT-based models and RAR-B. Their findings reveal interesting insights about how these models compute relevance, such as the over-reliance on term frequency signals and the failure to capture certain semantic relationships.
The interventional analysis also enables the authors to develop CALMEX, a causal, model-agnostic explanation method that can provide insights into the model's decision-making process. This goes beyond traditional feature importance-based explanations, which can be misleading or incomplete.
Critical Analysis
The authors have made a significant contribution to the field of neural information retrieval by developing a principled framework for reverse engineering the relevance computation in these models. The use of axiomatic causal interventions is a novel and powerful approach that provides valuable insights into the inner workings of neural ranking systems.
However, the paper also acknowledges several limitations of this work. First, the interventions are limited to the input data and do not consider potential interactions between the model's internal components. Extending the framework to enable interventions on the model architecture or training process could provide even deeper insights.
Additionally, the paper focuses on a limited set of axioms and retrieval models. While the authors demonstrate the generalizability of their approach, it would be interesting to see how it applies to a wider range of axioms and models, including those that incorporate query-agnostic generative content or other advanced techniques.
Finally, the paper does not provide a comprehensive evaluation of the CALMEX explanation method compared to other state-of-the-art approaches. More thorough benchmarking and user studies would help establish the practical utility of this interpretability tool.
Conclusion
This research represents an important step towards understanding and improving the interpretability of neural retrieval models. By using axiomatic causal interventions, the authors have developed a principled framework for reverse engineering the relevance computation in these models, uncovering valuable insights that can inform the design of more robust and trustworthy information retrieval systems.
The findings from this work have the potential to significantly impact the field of neural information retrieval, paving the way for more transparent and accountable models that better align with human notions of relevance. As the use of AI systems continues to grow in high-stakes applications, this type of interpretability research will become increasingly crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Axiomatic Causal Interventions for Reverse Engineering Relevance Computation in Neural Retrieval Models
Catherine Chen, Jack Merullo, Carsten Eickhoff
Neural models have demonstrated remarkable performance across diverse ranking tasks. However, the processes and internal mechanisms along which they determine relevance are still largely unknown. Existing approaches for analyzing neural ranker behavior with respect to IR properties rely either on assessing overall model behavior or employing probing methods that may offer an incomplete understanding of causal mechanisms. To provide a more granular understanding of internal model decision-making processes, we propose the use of causal interventions to reverse engineer neural rankers, and demonstrate how mechanistic interpretability methods can be used to isolate components satisfying term-frequency axioms within a ranking model. We identify a group of attention heads that detect duplicate tokens in earlier layers of the model, then communicate with downstream heads to compute overall document relevance. More generally, we propose that this style of mechanistic analysis opens up avenues for reverse engineering the processes neural retrieval models use to compute relevance. This work aims to initiate granular interpretability efforts that will not only benefit retrieval model development and training, but ultimately ensure safer deployment of these models.
Read more5/7/2024
0
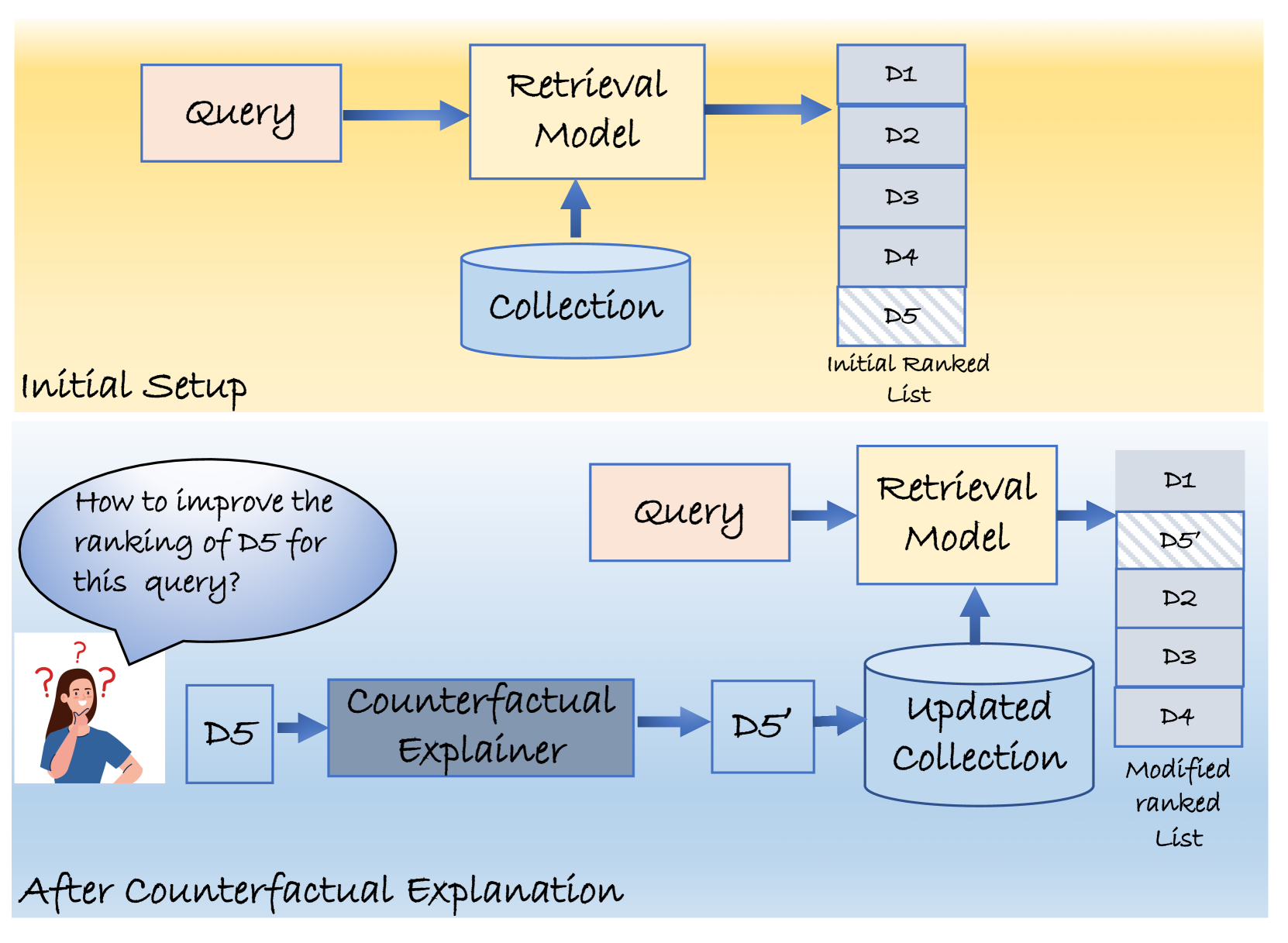
A Counterfactual Explanation Framework for Retrieval Models
Bhavik Chandna, Procheta Sen
Explainability has become a crucial concern in today's world, aiming to enhance transparency in machine learning and deep learning models. Information retrieval is no exception to this trend. In existing literature on explainability of information retrieval, the emphasis has predominantly been on illustrating the concept of relevance concerning a retrieval model. The questions addressed include why a document is relevant to a query, why one document exhibits higher relevance than another, or why a specific set of documents is deemed relevant for a query. However, limited attention has been given to understanding why a particular document is considered non-relevant to a query with respect to a retrieval model. In an effort to address this gap, our work focus on the question of what terms need to be added within a document to improve its ranking. This in turn answers the question of which words played a role in not being favored by a retrieval model for a particular query. We use an optimization framework to solve the above-mentioned research problem. % To the best of our knowledge, we mark the first attempt to tackle this specific counterfactual problem. Our experiments show the effectiveness of our proposed approach in predicting counterfactuals for both statistical (e.g. BM25) and deep-learning-based models (e.g. DRMM, DSSM, ColBERT).
Read more9/11/2024
0
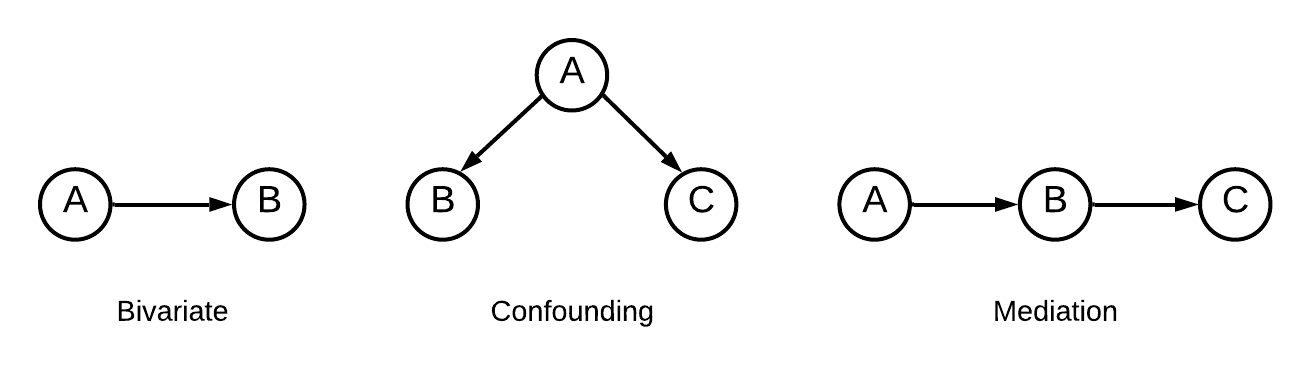
Evaluating Interventional Reasoning Capabilities of Large Language Models
Tejas Kasetty, Divyat Mahajan, Gintare Karolina Dziugaite, Alexandre Drouin, Dhanya Sridhar
Numerous decision-making tasks require estimating causal effects under interventions on different parts of a system. As practitioners consider using large language models (LLMs) to automate decisions, studying their causal reasoning capabilities becomes crucial. A recent line of work evaluates LLMs ability to retrieve commonsense causal facts, but these evaluations do not sufficiently assess how LLMs reason about interventions. Motivated by the role that interventions play in causal inference, in this paper, we conduct empirical analyses to evaluate whether LLMs can accurately update their knowledge of a data-generating process in response to an intervention. We create benchmarks that span diverse causal graphs (e.g., confounding, mediation) and variable types, and enable a study of intervention-based reasoning. These benchmarks allow us to isolate the ability of LLMs to accurately predict changes resulting from their ability to memorize facts or find other shortcuts. Our analysis on four LLMs highlights that while GPT- 4 models show promising accuracy at predicting the intervention effects, they remain sensitive to distracting factors in the prompts.
Read more4/9/2024
🤯
0
ReFIT: Relevance Feedback from a Reranker during Inference
Revanth Gangi Reddy, Pradeep Dasigi, Md Arafat Sultan, Arman Cohan, Avirup Sil, Heng Ji, Hannaneh Hajishirzi
Retrieve-and-rerank is a prevalent framework in neural information retrieval, wherein a bi-encoder network initially retrieves a pre-defined number of candidates (e.g., K=100), which are then reranked by a more powerful cross-encoder model. While the reranker often yields improved candidate scores compared to the retriever, its scope is confined to only the top K retrieved candidates. As a result, the reranker cannot improve retrieval performance in terms of Recall@K. In this work, we propose to leverage the reranker to improve recall by making it provide relevance feedback to the retriever at inference time. Specifically, given a test instance during inference, we distill the reranker's predictions for that instance into the retriever's query representation using a lightweight update mechanism. The aim of the distillation loss is to align the retriever's candidate scores more closely with those produced by the reranker. The algorithm then proceeds by executing a second retrieval step using the updated query vector. We empirically demonstrate that this method, applicable to various retrieve-and-rerank frameworks, substantially enhances retrieval recall across multiple domains, languages, and modalities.
Read more5/29/2024