CRAFT: Extracting and Tuning Cultural Instructions from the Wild
2405.03138
0
0
🤿
Abstract
Large language models (LLMs) have rapidly evolved as the foundation of various natural language processing (NLP) applications. Despite their wide use cases, their understanding of culturally-related concepts and reasoning remains limited. Meantime, there is a significant need to enhance these models' cultural reasoning capabilities, especially concerning underrepresented regions. This paper introduces a novel pipeline for extracting high-quality, culturally-related instruction tuning datasets from vast unstructured corpora. We utilize a self-instruction generation pipeline to identify cultural concepts and trigger instruction. By integrating with a general-purpose instruction tuning dataset, our model demonstrates enhanced capabilities in recognizing and understanding regional cultural nuances, thereby enhancing its reasoning capabilities. We conduct experiments across three regions: Singapore, the Philippines, and the United States, achieving performance improvement of up to 6%. Our research opens new avenues for extracting cultural instruction tuning sets directly from unstructured data, setting a precedent for future innovations in the field.
Create account to get full access
Overview
- Large language models (LLMs) are widely used in natural language processing (NLP) applications, but their understanding of culturally-related concepts and reasoning remains limited.
- There is a significant need to enhance these models' cultural reasoning capabilities, especially concerning underrepresented regions.
- This paper introduces a novel pipeline for extracting high-quality, culturally-related instruction tuning datasets from vast unstructured corpora.
Plain English Explanation
Large language models have become the foundation for many natural language processing applications, such as chatbots, language translation, and text generation. However, these models often struggle to fully understand and reason about cultural concepts, especially those from underrepresented regions around the world.
To address this limitation, the researchers in this paper developed a new method for extracting high-quality datasets that capture cultural information. They used a self-instruction generation pipeline to identify cultural concepts and generate relevant instructions that can be used to "train" language models to better understand cultural nuances.
By integrating this culturally-focused dataset with a general-purpose instruction tuning dataset, the researchers were able to enhance the language model's ability to recognize and reason about cultural differences across three regions: Singapore, the Philippines, and the United States. The model demonstrated performance improvements of up to 6% in these areas.
This research opens up new possibilities for extracting cultural knowledge directly from unstructured data, which could lead to future innovations in building more culturally-aware and responsive language models.
Technical Explanation
The researchers developed a pipeline to extract high-quality, culturally-related instruction tuning datasets from vast unstructured corpora. They utilized a self-instruction generation pipeline to identify cultural concepts and trigger relevant instructions, which were then integrated with a general-purpose instruction tuning dataset.
By combining this culturally-focused dataset with a broader instruction tuning dataset, the researchers were able to enhance the language model's capabilities in recognizing and understanding regional cultural nuances, thereby improving its reasoning abilities.
The researchers conducted experiments across three regions: Singapore, the Philippines, and the United States. They observed performance improvements of up to 6% in the model's ability to understand and reason about cultural concepts from these diverse regions.
This research builds on previous work in language modeling and cultural perception, setting a precedent for future innovations in extracting cultural knowledge directly from unstructured data and integrating it into language models.
Critical Analysis
The researchers acknowledge that while their pipeline demonstrates promising results, there are still limitations to the model's cultural understanding. The dataset extraction process may not capture the full breadth and depth of cultural concepts, and the model's reasoning capabilities may still be constrained by the biases and limitations of the underlying language model.
Furthermore, the experiments were conducted on a relatively small set of regions, and it remains to be seen how well the approach would scale to a more diverse set of cultural contexts. Additional research may be needed to address these limitations and further enhance the cultural reasoning capabilities of large language models.
It is also important to consider the potential ethical implications of building culturally-aware language models, such as the risk of perpetuating or amplifying existing biases and stereotypes. The researchers do not address these concerns in depth, and further exploration of the societal impacts of this technology would be valuable.
Conclusion
This research introduces a novel pipeline for extracting high-quality, culturally-related instruction tuning datasets from unstructured corpora. By integrating these datasets with a general-purpose instruction tuning dataset, the researchers were able to enhance the cultural reasoning capabilities of large language models, demonstrating performance improvements of up to 6% across three regions.
This work opens new avenues for extracting cultural knowledge directly from data and integrating it into language models, potentially leading to more culturally-aware and responsive natural language processing applications. However, further research is needed to address the limitations and ethical considerations of this approach, ensuring that these advancements benefit society as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Optimizing Psychological Counseling with Instruction-Tuned Large Language Models
Wenjie Li, Tianyu Sun, Kun Qian, Wenhong Wang
0
0
The advent of large language models (LLMs) has significantly advanced various fields, including natural language processing and automated dialogue systems. This paper explores the application of LLMs in psychological counseling, addressing the increasing demand for mental health services. We present a method for instruction tuning LLMs with specialized prompts to enhance their performance in providing empathetic, relevant, and supportive responses. Our approach involves developing a comprehensive dataset of counseling-specific prompts, refining them through feedback from professional counselors, and conducting rigorous evaluations using both automatic metrics and human assessments. The results demonstrate that our instruction-tuned model outperforms several baseline LLMs, highlighting its potential as a scalable and accessible tool for mental health support.
6/21/2024
💬
BioInstruct: Instruction Tuning of Large Language Models for Biomedical Natural Language Processing
Hieu Tran, Zhichao Yang, Zonghai Yao, Hong Yu
0
0
To enhance the performance of large language models (LLMs) in biomedical natural language processing (BioNLP) by introducing a domain-specific instruction dataset and examining its impact when combined with multi-task learning principles. We created the BioInstruct, comprising 25,005 instructions to instruction-tune LLMs(LLaMA 1 & 2, 7B & 13B version). The instructions were created by prompting the GPT-4 language model with three-seed samples randomly drawn from an 80 human curated instructions. We employed Low-Rank Adaptation(LoRA) for parameter-efficient fine-tuning. We then evaluated these instruction-tuned LLMs on several BioNLP tasks, which can be grouped into three major categories: question answering(QA), information extraction(IE), and text generation(GEN). We also examined whether categories(e.g., QA, IE, and generation) of instructions impact model performance. Comparing with LLMs without instruction-tuned, our instruction-tuned LLMs demonstrated marked performance gains: 17.3% in QA, 5.7% in IE, and 96% in Generation tasks. Our 7B-parameter instruction-tuned LLaMA 1 model was competitive or even surpassed other LLMs in the biomedical domain that were also fine-tuned from LLaMA 1 with vast domain-specific data or a variety of tasks. Our results also show that the performance gain is significantly higher when instruction fine-tuning is conducted with closely related tasks. Our findings align with the observations of multi-task learning, suggesting the synergies between two tasks. The BioInstruct dataset serves as a valuable resource and instruction tuned LLMs lead to the best performing BioNLP applications.
6/10/2024

Contrastive Instruction Tuning
Tianyi Lorena Yan, Fei Wang, James Y. Huang, Wenxuan Zhou, Fan Yin, Aram Galstyan, Wenpeng Yin, Muhao Chen
0
0
Instruction tuning has been used as a promising approach to improve the performance of large language models (LLMs) on unseen tasks. However, current LLMs exhibit limited robustness to unseen instructions, generating inconsistent outputs when the same instruction is phrased with slightly varied forms or language styles. This behavior indicates LLMs' lack of robustness to textual variations and generalizability to unseen instructions, potentially leading to trustworthiness issues. Accordingly, we propose Contrastive Instruction Tuning, which maximizes the similarity between the hidden representations of semantically equivalent instruction-instance pairs while minimizing the similarity between semantically different ones. To facilitate this approach, we augment the existing FLAN collection by paraphrasing task instructions. Experiments on the PromptBench benchmark show that CoIN consistently improves LLMs' robustness to unseen instructions with variations across character, word, sentence, and semantic levels by an average of +2.5% in accuracy. Code is available at https://github.com/luka-group/CoIN.
6/7/2024
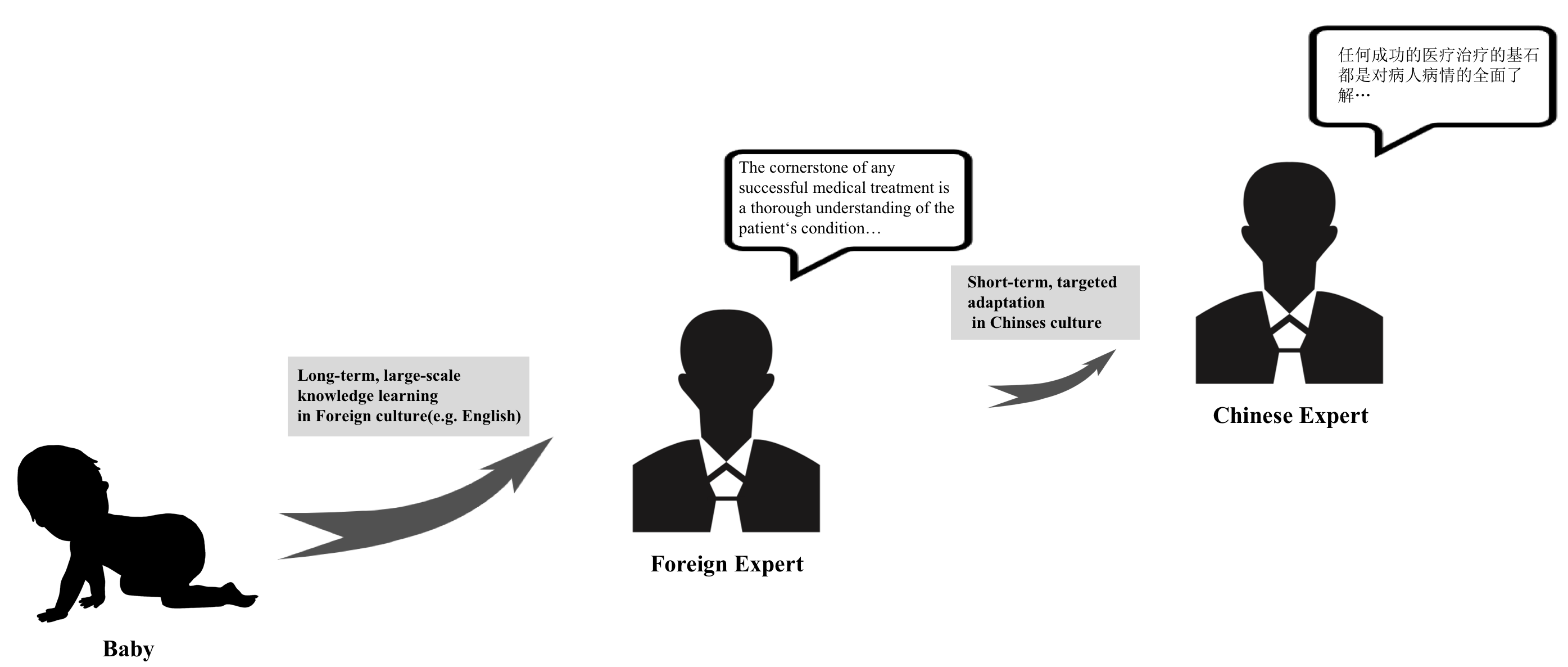
Methodology of Adapting Large English Language Models for Specific Cultural Contexts
Wenjing Zhang, Siqi Xiao, Xuejiao Lei, Ning Wang, Huazheng Zhang, Meijuan An, Bikun Yang, Zhaoxiang Liu, Kai Wang, Shiguo Lian
0
0
The rapid growth of large language models(LLMs) has emerged as a prominent trend in the field of artificial intelligence. However, current state-of-the-art LLMs are predominantly based on English. They encounter limitations when directly applied to tasks in specific cultural domains, due to deficiencies in domain-specific knowledge and misunderstandings caused by differences in cultural values. To address this challenge, our paper proposes a rapid adaptation method for large models in specific cultural contexts, which leverages instruction-tuning based on specific cultural knowledge and safety values data. Taking Chinese as the specific cultural context and utilizing the LLaMA3-8B as the experimental English LLM, the evaluation results demonstrate that the adapted LLM significantly enhances its capabilities in domain-specific knowledge and adaptability to safety values, while maintaining its original expertise advantages.
6/28/2024