CRAG -- Comprehensive RAG Benchmark

0

Sign in to get full access
Overview
- This paper introduces the Comprehensive RAG Benchmark (CRAG), a new benchmark for evaluating Retrieval-Augmented Generation (RAG) models.
- RAG models combine language models with information retrieval to generate more accurate and informative text.
- CRAG is designed to assess the performance of RAG models on a diverse set of tasks, including open-ended generation, question answering, and knowledge-intensive language understanding.
Plain English Explanation
The CRAG - Comprehensive RAG Benchmark paper presents a new way to evaluate a type of AI model called a Retrieval-Augmented Generation (RAG) model. RAG models work by combining a language model, which can generate human-like text, with an information retrieval system, which can find relevant information from a database. This allows the model to generate more accurate and informative text by pulling in relevant knowledge from the database.
The CRAG benchmark is designed to thoroughly test how well these RAG models perform on a variety of tasks, including open-ended text generation, question answering, and understanding complex language that requires knowledge. By having a comprehensive set of tests, researchers can better understand the strengths and weaknesses of different RAG models and how they can be improved.
Technical Explanation
The CRAG - Comprehensive RAG Benchmark paper introduces a new benchmark for evaluating Retrieval-Augmented Generation (RAG) models. RAG models, described in the DuetRAG: Collaborative Retrieval-Augmented Generation paper, combine a language model with an information retrieval system to generate more accurate and informative text.
The CRAG benchmark includes a diverse set of tasks to assess RAG model performance, such as open-ended generation, question answering, and knowledge-intensive language understanding. These tasks are designed to test different aspects of RAG model capabilities, going beyond the standard language modeling evaluation. The paper also describes the dataset curation process and provides baseline results for several state-of-the-art RAG models.
Critical Analysis
The CRAG - Comprehensive RAG Benchmark paper makes a valuable contribution to the field of Retrieval-Augmented Generation by providing a comprehensive evaluation framework. The diverse set of tasks included in the benchmark aligns with the Evaluation of Retrieval-Augmented Generation: Survey and Perspective paper, which calls for more thorough testing of RAG models.
However, the paper does not address some potential limitations of the CRAG benchmark. For example, the dataset may not fully capture the real-world complexity and diversity of knowledge-intensive tasks that RAG models may encounter. Additionally, the benchmark does not explore the KG-RAG: Bridging the Gap Between Knowledge and Creativity in terms of evaluating the model's ability to generate novel and creative content by combining retrieved information in novel ways.
Further research could investigate ways to expand the CRAG benchmark, such as including more challenging or domain-specific tasks, or exploring the connection between retrieval quality and generation performance, as discussed in the Blended-RAG: Improving RAG Retriever-Augmented Generation paper.
Conclusion
The CRAG - Comprehensive RAG Benchmark paper introduces a valuable tool for evaluating Retrieval-Augmented Generation (RAG) models. By providing a diverse set of tasks, CRAG allows researchers to better understand the strengths and limitations of different RAG models, which is crucial for advancing the field of knowledge-intensive text generation. While the benchmark has room for further refinement, it represents an important step towards more comprehensive and meaningful evaluation of these powerful AI models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CRAG -- Comprehensive RAG Benchmark
Xiao Yang, Kai Sun, Hao Xin, Yushi Sun, Nikita Bhalla, Xiangsen Chen, Sajal Choudhary, Rongze Daniel Gui, Ziran Will Jiang, Ziyu Jiang, Lingkun Kong, Brian Moran, Jiaqi Wang, Yifan Ethan Xu, An Yan, Chenyu Yang, Eting Yuan, Hanwen Zha, Nan Tang, Lei Chen, Nicolas Scheffer, Yue Liu, Nirav Shah, Rakesh Wanga, Anuj Kumar, Wen-tau Yih, Xin Luna Dong
Retrieval-Augmented Generation (RAG) has recently emerged as a promising solution to alleviate Large Language Model (LLM)'s deficiency in lack of knowledge. Existing RAG datasets, however, do not adequately represent the diverse and dynamic nature of real-world Question Answering (QA) tasks. To bridge this gap, we introduce the Comprehensive RAG Benchmark (CRAG), a factual question answering benchmark of 4,409 question-answer pairs and mock APIs to simulate web and Knowledge Graph (KG) search. CRAG is designed to encapsulate a diverse array of questions across five domains and eight question categories, reflecting varied entity popularity from popular to long-tail, and temporal dynamisms ranging from years to seconds. Our evaluation on this benchmark highlights the gap to fully trustworthy QA. Whereas most advanced LLMs achieve <=34% accuracy on CRAG, adding RAG in a straightforward manner improves the accuracy only to 44%. State-of-the-art industry RAG solutions only answer 63% questions without any hallucination. CRAG also reveals much lower accuracy in answering questions regarding facts with higher dynamism, lower popularity, or higher complexity, suggesting future research directions. The CRAG benchmark laid the groundwork for a KDD Cup 2024 challenge, attracting thousands of participants and submissions within the first 50 days of the competition. We commit to maintaining CRAG to serve research communities in advancing RAG solutions and general QA solutions.
Read more6/10/2024
🛸
0
CRUD-RAG: A Comprehensive Chinese Benchmark for Retrieval-Augmented Generation of Large Language Models
Yuanjie Lyu, Zhiyu Li, Simin Niu, Feiyu Xiong, Bo Tang, Wenjin Wang, Hao Wu, Huanyong Liu, Tong Xu, Enhong Chen
Retrieval-Augmented Generation (RAG) is a technique that enhances the capabilities of large language models (LLMs) by incorporating external knowledge sources. This method addresses common LLM limitations, including outdated information and the tendency to produce inaccurate hallucinated content. However, the evaluation of RAG systems is challenging, as existing benchmarks are limited in scope and diversity. Most of the current benchmarks predominantly assess question-answering applications, overlooking the broader spectrum of situations where RAG could prove advantageous. Moreover, they only evaluate the performance of the LLM component of the RAG pipeline in the experiments, and neglect the influence of the retrieval component and the external knowledge database. To address these issues, this paper constructs a large-scale and more comprehensive benchmark, and evaluates all the components of RAG systems in various RAG application scenarios. Specifically, we have categorized the range of RAG applications into four distinct types-Create, Read, Update, and Delete (CRUD), each representing a unique use case. Create refers to scenarios requiring the generation of original, varied content. Read involves responding to intricate questions in knowledge-intensive situations. Update focuses on revising and rectifying inaccuracies or inconsistencies in pre-existing texts. Delete pertains to the task of summarizing extensive texts into more concise forms. For each of these CRUD categories, we have developed comprehensive datasets to evaluate the performance of RAG systems. We also analyze the effects of various components of the RAG system, such as the retriever, the context length, the knowledge base construction, and the LLM. Finally, we provide useful insights for optimizing the RAG technology for different scenarios.
Read more7/16/2024

0
A Hybrid RAG System with Comprehensive Enhancement on Complex Reasoning
Ye Yuan, Chengwu Liu, Jingyang Yuan, Gongbo Sun, Siqi Li, Ming Zhang
Retrieval-augmented generation (RAG) is a framework enabling large language models (LLMs) to enhance their accuracy and reduce hallucinations by integrating external knowledge bases. In this paper, we introduce a hybrid RAG system enhanced through a comprehensive suite of optimizations that significantly improve retrieval quality, augment reasoning capabilities, and refine numerical computation ability. We refined the text chunks and tables in web pages, added attribute predictors to reduce hallucinations, conducted LLM Knowledge Extractor and Knowledge Graph Extractor, and finally built a reasoning strategy with all the references. We evaluated our system on the CRAG dataset through the Meta CRAG KDD Cup 2024 Competition. Both the local and online evaluations demonstrate that our system significantly enhances complex reasoning capabilities. In local evaluations, we have significantly improved accuracy and reduced error rates compared to the baseline model, achieving a notable increase in scores. In the meanwhile, we have attained outstanding results in online assessments, demonstrating the performance and generalization capabilities of the proposed system. The source code for our system is released in url{https://gitlab.aicrowd.com/shizueyy/crag-new}.
Read more9/4/2024
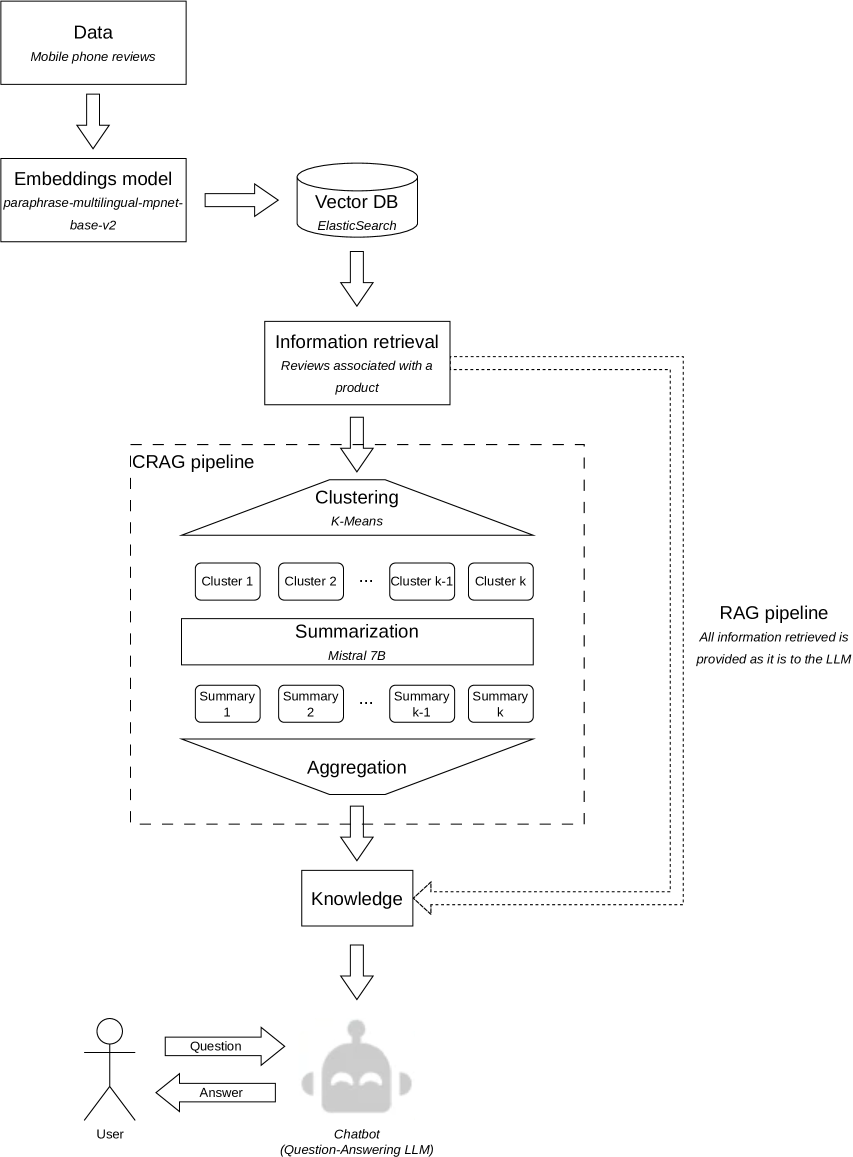
0
Clustered Retrieved Augmented Generation (CRAG)
Simon Akesson, Frances A. Santos
Providing external knowledge to Large Language Models (LLMs) is a key point for using these models in real-world applications for several reasons, such as incorporating up-to-date content in a real-time manner, providing access to domain-specific knowledge, and contributing to hallucination prevention. The vector database-based Retrieval Augmented Generation (RAG) approach has been widely adopted to this end. Thus, any part of external knowledge can be retrieved and provided to some LLM as the input context. Despite RAG approach's success, it still might be unfeasible for some applications, because the context retrieved can demand a longer context window than the size supported by LLM. Even when the context retrieved fits into the context window size, the number of tokens might be expressive and, consequently, impact costs and processing time, becoming impractical for most applications. To address these, we propose CRAG, a novel approach able to effectively reduce the number of prompting tokens without degrading the quality of the response generated compared to a solution using RAG. Through our experiments, we show that CRAG can reduce the number of tokens by at least 46%, achieving more than 90% in some cases, compared to RAG. Moreover, the number of tokens with CRAG does not increase considerably when the number of reviews analyzed is higher, unlike RAG, where the number of tokens is almost 9x higher when there are 75 reviews compared to 4 reviews.
Read more6/4/2024