A Critical Review of Causal Reasoning Benchmarks for Large Language Models

0

Sign in to get full access
Overview
- This paper provides a critical review of existing causal reasoning benchmarks for large language models (LLMs).
- The authors analyze several prominent benchmarks and datasets, highlighting their strengths, limitations, and the challenges they pose for evaluating the causal reasoning capabilities of LLMs.
- The paper aims to guide the development of more robust and comprehensive causal reasoning benchmarks that can better assess the progress and limitations of LLMs in this domain.
Plain English Explanation
This paper takes a close look at the tests and datasets that researchers have developed to measure how well large language models, like GPT-3 or ChatGPT, can understand and reason about cause and effect relationships. Causal reasoning is an important skill, as it allows models to understand why things happen, not just what happens.
The authors review several of the leading "causal reasoning benchmarks" that have been created, examining their strengths and weaknesses. They point out that while these benchmarks provide valuable insights, they often have limitations that make it difficult to fully assess the causal reasoning capabilities of large language models.
For example, some benchmarks may focus too narrowly on specific types of causal relationships, or they may not capture the nuances of how humans reason about causes and effects. The authors argue that developing more comprehensive and realistic causal reasoning benchmarks is crucial for driving progress in this area of AI.
By highlighting the current limitations of causal reasoning benchmarks, the paper aims to guide researchers and developers towards creating better tools for evaluating and improving the causal reasoning abilities of large language models. This could lead to models that have a deeper understanding of the world and can make more informed, rational decisions.
Technical Explanation
The paper reviews several prominent benchmarks and datasets used to evaluate the causal reasoning capabilities of large language models, including CausalBench, Is Knowledge All Large Language Models Needed?, Evaluating Interventional Reasoning Capabilities of Large Language Models, Causal Evaluation of Language Models, and Cause and Effect: Can Large Language Models Truly Understand Causality?.
The authors analyze the strengths and limitations of these benchmarks, discussing how they capture different aspects of causal reasoning, such as interventional reasoning, counterfactual reasoning, and causal structure learning. They highlight the challenges posed by factors like dataset biases, the use of synthetic data, and the difficulty of evaluating higher-order causal reasoning.
The paper also delves into the architectural and training considerations that may impact the causal reasoning capabilities of large language models, such as the role of world knowledge, causal inductive biases, and the limitations of purely text-based training.
Critical Analysis
The paper provides a thoughtful and nuanced critique of existing causal reasoning benchmarks, acknowledging their value while also highlighting their limitations. The authors rightly point out that the current benchmarks often fail to capture the full complexity of human causal reasoning, which involves factors like contextual understanding, commonsense reasoning, and the ability to learn and reason about causal structures.
One potential area for further research is the integration of causal reasoning with other cognitive abilities, such as common sense reasoning, planning, and decision-making. The authors suggest that developing benchmarks that better reflect the holistic nature of human causal reasoning could lead to more robust and capable language models.
Additionally, the paper could have delved deeper into the potential biases and blind spots introduced by the training data and methods used to build large language models. The authors acknowledge this as a concern, but more exploration of how these factors may impact causal reasoning could have strengthened the critique.
Overall, this paper provides a valuable and thought-provoking analysis of the current state of causal reasoning benchmarks for large language models. It serves as an important guide for researchers and developers working to advance the field of causal reasoning in AI.
Conclusion
This paper presents a critical review of the existing causal reasoning benchmarks for large language models, highlighting their strengths, limitations, and the key challenges they pose for evaluating the causal reasoning capabilities of these models.
The authors' analysis underscores the need for more comprehensive and realistic causal reasoning benchmarks that can better capture the nuances of human causal reasoning. By addressing the shortcomings of current benchmarks, this paper aims to guide the development of more robust and informative tools for assessing the progress and limitations of large language models in the domain of causal reasoning.
Improving causal reasoning capabilities is essential for building AI systems that can truly understand the world, make informed decisions, and engage in meaningful problem-solving. The insights provided in this paper can help drive the field of causal reasoning in AI forward, ultimately leading to more capable and trustworthy language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Critical Review of Causal Reasoning Benchmarks for Large Language Models
Linying Yang, Vik Shirvaikar, Oscar Clivio, Fabian Falck
Numerous benchmarks aim to evaluate the capabilities of Large Language Models (LLMs) for causal inference and reasoning. However, many of them can likely be solved through the retrieval of domain knowledge, questioning whether they achieve their purpose. In this review, we present a comprehensive overview of LLM benchmarks for causality. We highlight how recent benchmarks move towards a more thorough definition of causal reasoning by incorporating interventional or counterfactual reasoning. We derive a set of criteria that a useful benchmark or set of benchmarks should aim to satisfy. We hope this work will pave the way towards a general framework for the assessment of causal understanding in LLMs and the design of novel benchmarks.
Read more7/12/2024

0
CausalBench: A Comprehensive Benchmark for Causal Learning Capability of Large Language Models
Yu Zhou, Xingyu Wu, Beicheng Huang, Jibin Wu, Liang Feng, Kay Chen Tan
Causality reveals fundamental principles behind data distributions in real-world scenarios, and the capability of large language models (LLMs) to understand causality directly impacts their efficacy across explaining outputs, adapting to new evidence, and generating counterfactuals. With the proliferation of LLMs, the evaluation of this capacity is increasingly garnering attention. However, the absence of a comprehensive benchmark has rendered existing evaluation studies being straightforward, undiversified, and homogeneous. To address these challenges, this paper proposes a comprehensive benchmark, namely CausalBench, to evaluate the causality understanding capabilities of LLMs. Originating from the causal research community, CausalBench encompasses three causal learning-related tasks, which facilitate a convenient comparison of LLMs' performance with classic causal learning algorithms. Meanwhile, causal networks of varying scales and densities are integrated in CausalBench, to explore the upper limits of LLMs' capabilities across task scenarios of varying difficulty. Notably, background knowledge and structured data are also incorporated into CausalBench to thoroughly unlock the underlying potential of LLMs for long-text comprehension and prior information utilization. Based on CausalBench, this paper evaluates nineteen leading LLMs and unveils insightful conclusions in diverse aspects. Firstly, we present the strengths and weaknesses of LLMs and quantitatively explore the upper limits of their capabilities across various scenarios. Meanwhile, we further discern the adaptability and abilities of LLMs to specific structural networks and complex chain of thought structures. Moreover, this paper quantitatively presents the differences across diverse information sources and uncovers the gap between LLMs' capabilities in causal understanding within textual contexts and numerical domains.
Read more4/10/2024
0
Is Knowledge All Large Language Models Needed for Causal Reasoning?
Hengrui Cai, Shengjie Liu, Rui Song
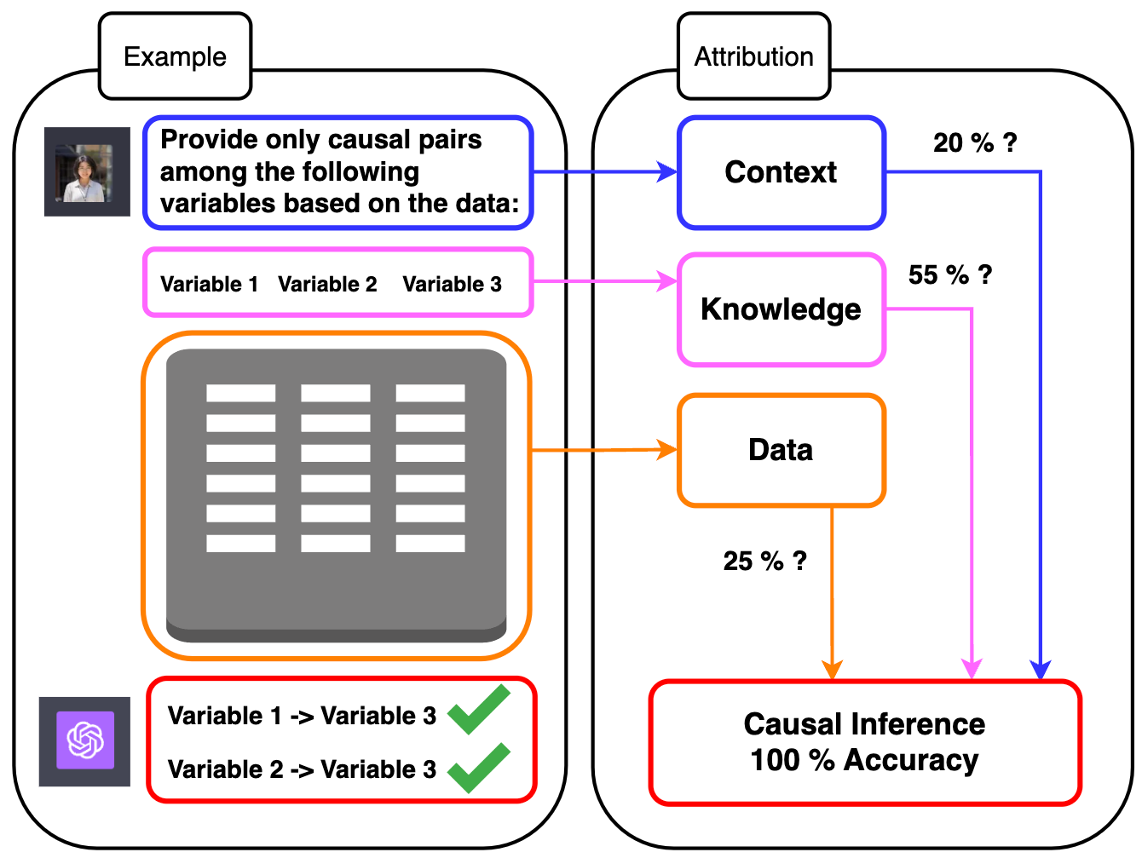
This paper explores the causal reasoning of large language models (LLMs) to enhance their interpretability and reliability in advancing artificial intelligence. Despite the proficiency of LLMs in a range of tasks, their potential for understanding causality requires further exploration. We propose a novel causal attribution model that utilizes ``do-operators for constructing counterfactual scenarios, allowing us to systematically quantify the influence of input numerical data and LLMs' pre-existing knowledge on their causal reasoning processes. Our newly developed experimental setup assesses LLMs' reliance on contextual information and inherent knowledge across various domains. Our evaluation reveals that LLMs' causal reasoning ability mainly depends on the context and domain-specific knowledge provided. In the absence of such knowledge, LLMs can still maintain a degree of causal reasoning using the available numerical data, albeit with limitations in the calculations. This motivates the proposed fine-tuned LLM for pairwise causal discovery, effectively leveraging both knowledge and numerical information.
Read more6/6/2024
0
Evaluating Interventional Reasoning Capabilities of Large Language Models
Tejas Kasetty, Divyat Mahajan, Gintare Karolina Dziugaite, Alexandre Drouin, Dhanya Sridhar
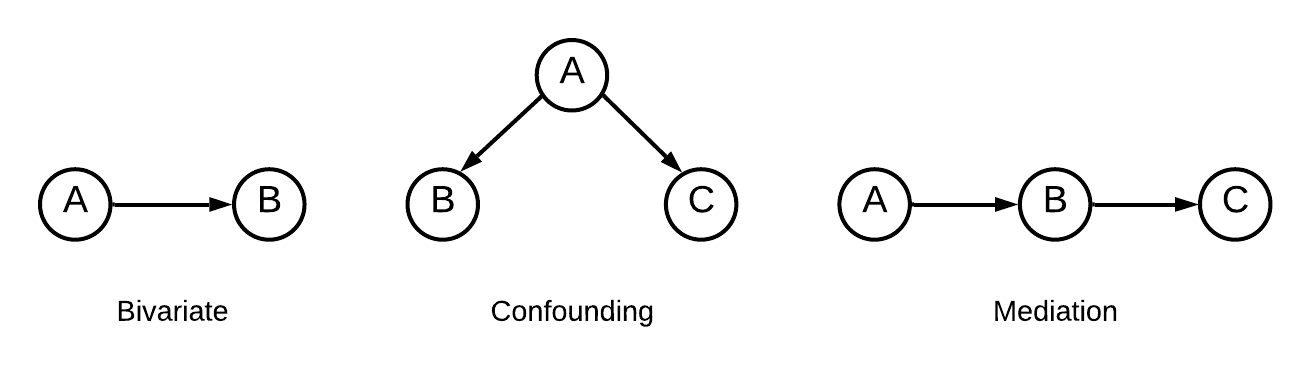
Numerous decision-making tasks require estimating causal effects under interventions on different parts of a system. As practitioners consider using large language models (LLMs) to automate decisions, studying their causal reasoning capabilities becomes crucial. A recent line of work evaluates LLMs ability to retrieve commonsense causal facts, but these evaluations do not sufficiently assess how LLMs reason about interventions. Motivated by the role that interventions play in causal inference, in this paper, we conduct empirical analyses to evaluate whether LLMs can accurately update their knowledge of a data-generating process in response to an intervention. We create benchmarks that span diverse causal graphs (e.g., confounding, mediation) and variable types, and enable a study of intervention-based reasoning. These benchmarks allow us to isolate the ability of LLMs to accurately predict changes resulting from their ability to memorize facts or find other shortcuts. Our analysis on four LLMs highlights that while GPT- 4 models show promising accuracy at predicting the intervention effects, they remain sensitive to distracting factors in the prompts.
Read more4/9/2024