Cross-Lingual Multi-Hop Knowledge Editing -- Benchmarks, Analysis and a Simple Contrastive Learning based Approach

0

Sign in to get full access
Overview
- Introduces a new benchmark for cross-lingual multi-hop knowledge editing and a simple contrastive learning approach to tackle this task.
- Explores the challenges of editing the knowledge of large language models across multiple languages.
- Presents the MLake benchmark, a multilingual dataset for evaluating knowledge editing capabilities.
- Proposes a contrastive learning method as a simple yet effective approach for cross-lingual knowledge editing.
Plain English Explanation
This research paper tackles the challenge of editing the knowledge of large language models, such as those used in chatbots and virtual assistants, across multiple languages. The key idea is to develop techniques that can modify or update the knowledge stored in these models, allowing them to correct factual errors, update outdated information, or expand their understanding on various topics.
The researchers first created a new benchmark called MLake, which is a dataset designed to evaluate a model's ability to perform cross-lingual multi-hop knowledge editing. This means the model needs to understand the original knowledge, identify the parts that need to be changed, and then update the information in a way that is consistent across different languages.
To address this challenge, the researchers proposed a simple yet effective approach based on contrastive learning. This method trains the language model to learn how to edit its own knowledge by comparing the original and edited versions of the same information. The goal is to help the model develop an intuitive understanding of what kind of changes are appropriate and how to apply them consistently across languages.
By developing better techniques for cross-lingual knowledge editing, the researchers aim to improve the overall quality and usefulness of large language models, making them more reliable and adaptable for a wide range of real-world applications.
Technical Explanation
The paper introduces a new benchmark called MLake, which is designed to evaluate the cross-lingual multi-hop knowledge editing capabilities of large language models. The benchmark consists of a dataset with examples of knowledge that needs to be edited, along with the desired edited versions in multiple languages.
To tackle this task, the researchers propose a simple contrastive learning approach. The key idea is to train the language model to learn how to edit its own knowledge by comparing the original and edited versions of the same information. This is done by creating contrastive pairs of the original and edited text, and then training the model to recognize the differences between them.
The researchers evaluate their approach on the MLake benchmark, as well as on additional datasets for event-level knowledge editing and easy-to-use knowledge editing. The results show that their contrastive learning method outperforms other baselines, demonstrating its effectiveness in cross-lingual knowledge editing.
Critical Analysis
The paper presents a promising approach for cross-lingual knowledge editing, which is an important challenge in the development of large language models. However, the researchers acknowledge that their contrastive learning method is a simple and preliminary solution, and there is still room for improvement.
One potential limitation is that the MLake benchmark may not capture the full complexity of real-world knowledge editing scenarios, which can involve more nuanced changes and contextual understanding. Additionally, the researchers did not explore the scalability of their approach to larger and more diverse knowledge bases, which is an important consideration for practical applications.
Furthermore, the paper does not address the potential ethical implications of knowledge editing, such as the risk of introducing biases or the need for transparency and accountability in the editing process. These are important considerations that should be considered in future research.
Conclusion
This paper introduces a new benchmark and a simple contrastive learning approach for cross-lingual multi-hop knowledge editing in large language models. The proposed method demonstrates promising results, but the researchers acknowledge that it is a preliminary solution and that further research is needed to address the complexities and challenges of this task.
By advancing the field of knowledge editing, this work has the potential to improve the overall quality and usefulness of large language models, making them more reliable and adaptable for a wide range of applications. However, it is crucial that future research also considers the ethical implications and ensures that these techniques are developed and deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cross-Lingual Multi-Hop Knowledge Editing -- Benchmarks, Analysis and a Simple Contrastive Learning based Approach
Aditi Khandelwal, Harman Singh, Hengrui Gu, Tianlong Chen, Kaixiong Zhou
Large language models are often expected to constantly adapt to new sources of knowledge and knowledge editing techniques aim to efficiently patch the outdated model knowledge, with minimal modification. Most prior works focus on monolingual knowledge editing in English, even though new information can emerge in any language from any part of the world. We propose the Cross-Lingual Multi-Hop Knowledge Editing paradigm, for measuring and analyzing the performance of various SoTA knowledge editing techniques in a cross-lingual setup. Specifically, we create a parallel cross-lingual benchmark, CROLIN-MQUAKE for measuring the knowledge editing capabilities. Our extensive analysis over various knowledge editing techniques uncover significant gaps in performance between the cross-lingual and English-centric setting. Following this, we propose a significantly improved system for cross-lingual multi-hop knowledge editing, CLEVER-CKE. CLEVER-CKE is based on a retrieve, verify and generate knowledge editing framework, where a retriever is formulated to recall edited facts and support an LLM to adhere to knowledge edits. We develop language-aware and hard-negative based contrastive objectives for improving the cross-lingual and fine-grained fact retrieval and verification process used in this framework. Extensive experiments on three LLMs, eight languages, and two datasets show CLEVER-CKE's significant gains of up to 30% over prior methods.
Read more7/16/2024
💬
0
Cross-Lingual Knowledge Editing in Large Language Models
Jiaan Wang, Yunlong Liang, Zengkui Sun, Yuxuan Cao, Jiarong Xu, Fandong Meng
Knowledge editing aims to change language models' performance on several special cases (i.e., editing scope) by infusing the corresponding expected knowledge into them. With the recent advancements in large language models (LLMs), knowledge editing has been shown as a promising technique to adapt LLMs to new knowledge without retraining from scratch. However, most of the previous studies neglect the multi-lingual nature of some main-stream LLMs (e.g., LLaMA, ChatGPT and GPT-4), and typically focus on monolingual scenarios, where LLMs are edited and evaluated in the same language. As a result, it is still unknown the effect of source language editing on a different target language. In this paper, we aim to figure out this cross-lingual effect in knowledge editing. Specifically, we first collect a large-scale cross-lingual synthetic dataset by translating ZsRE from English to Chinese. Then, we conduct English editing on various knowledge editing methods covering different paradigms, and evaluate their performance in Chinese, and vice versa. To give deeper analyses of the cross-lingual effect, the evaluation includes four aspects, i.e., reliability, generality, locality and portability. Furthermore, we analyze the inconsistent behaviors of the edited models and discuss their specific challenges. Data and codes are available at https://github.com/krystalan/Bi_ZsRE
Read more5/31/2024
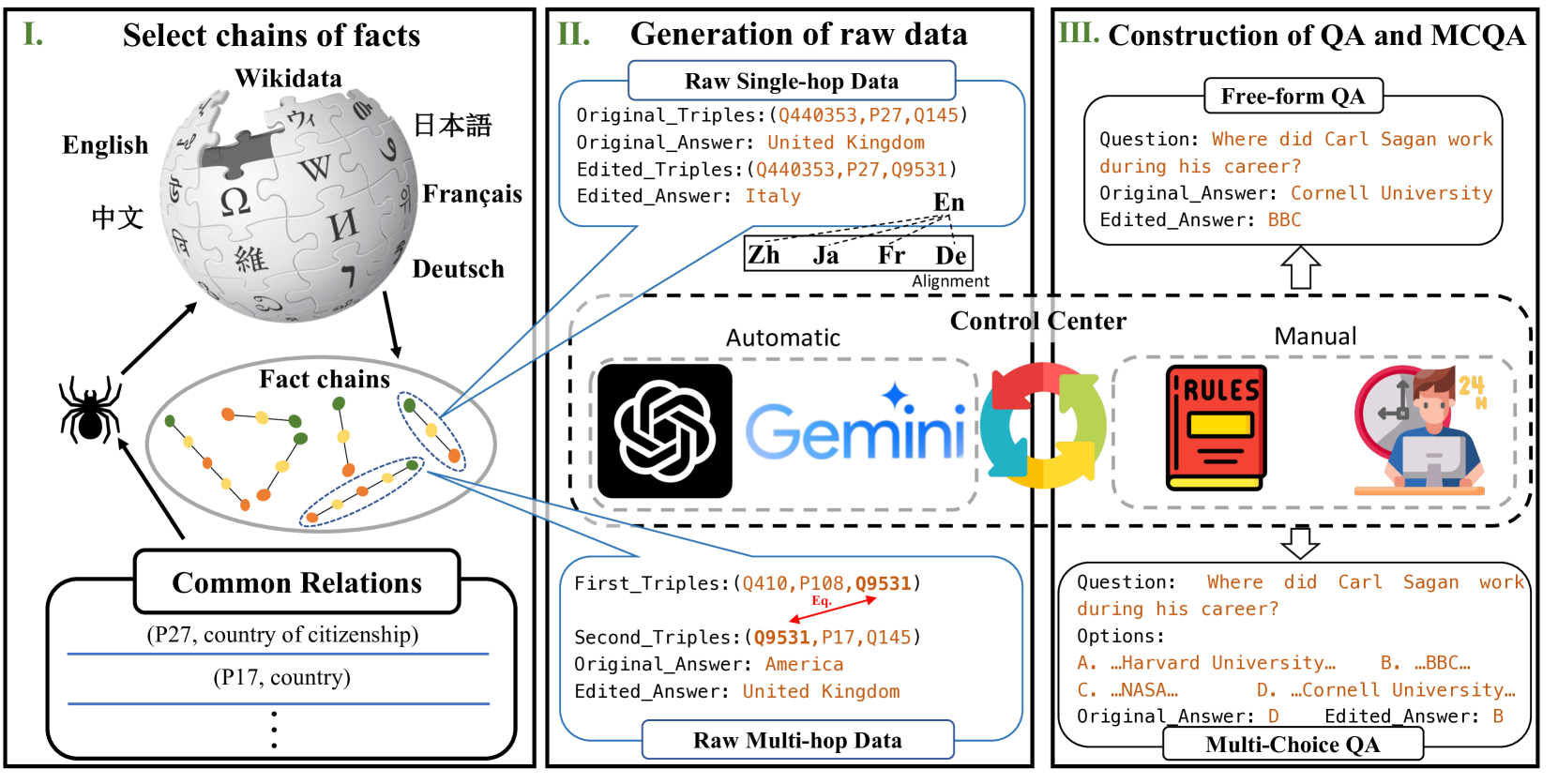
0
MLaKE: Multilingual Knowledge Editing Benchmark for Large Language Models
Zihao Wei, Jingcheng Deng, Liang Pang, Hanxing Ding, Huawei Shen, Xueqi Cheng
The extensive utilization of large language models (LLMs) underscores the crucial necessity for precise and contemporary knowledge embedded within their intrinsic parameters. Existing research on knowledge editing primarily concentrates on monolingual scenarios, neglecting the complexities presented by multilingual contexts and multi-hop reasoning. To address these challenges, our study introduces MLaKE (Multilingual Language Knowledge Editing), a novel benchmark comprising 4072 multi-hop and 5360 single-hop questions designed to evaluate the adaptability of knowledge editing methods across five languages: English, Chinese, Japanese, French, and German. MLaKE aggregates fact chains from Wikipedia across languages and utilizes LLMs to generate questions in both free-form and multiple-choice. We evaluate the multilingual knowledge editing generalization capabilities of existing methods on MLaKE. Existing knowledge editing methods demonstrate higher success rates in English samples compared to other languages. However, their generalization capabilities are limited in multi-language experiments. Notably, existing knowledge editing methods often show relatively high generalization for languages within the same language family compared to languages from different language families. These results underscore the imperative need for advancements in multilingual knowledge editing and we hope MLaKE can serve as a valuable resource for benchmarking and solution development.
Read more4/9/2024
💬
0
MQuAKE: Assessing Knowledge Editing in Language Models via Multi-Hop Questions
Zexuan Zhong, Zhengxuan Wu, Christopher D. Manning, Christopher Potts, Danqi Chen
The information stored in large language models (LLMs) falls out of date quickly, and retraining from scratch is often not an option. This has recently given rise to a range of techniques for injecting new facts through updating model weights. Current evaluation paradigms are extremely limited, mainly validating the recall of edited facts, but changing one fact should cause rippling changes to the model's related beliefs. If we edit the UK Prime Minister to now be Rishi Sunak, then we should get a different answer to Who is married to the British Prime Minister? In this work, we present a benchmark, MQuAKE (Multi-hop Question Answering for Knowledge Editing), comprising multi-hop questions that assess whether edited models correctly answer questions where the answer should change as an entailed consequence of edited facts. While we find that current knowledge-editing approaches can recall edited facts accurately, they fail catastrophically on the constructed multi-hop questions. We thus propose a simple memory-based approach, MeLLo, which stores all edited facts externally while prompting the language model iteratively to generate answers that are consistent with the edited facts. While MQuAKE remains challenging, we show that MeLLo scales well with LLMs (e.g., OpenAI GPT-3.5-turbo) and outperforms previous model editors by a large margin.
Read more9/10/2024