Combining Teacher-Student with Representation Learning: A Concurrent Teacher-Student Reinforcement Learning Paradigm for Legged Locomotion

0

Sign in to get full access
Overview
- Combines teacher-student and representation learning approaches for legged locomotion in reinforcement learning (RL)
- Introduces a "concurrent teacher-student" RL paradigm where a teacher agent guides a student agent during training
- Aims to accelerate learning, improve performance, and enable zero-shot transfer to new environments
Plain English Explanation
This research paper proposes a new way of training reinforcement learning (RL) agents for legged locomotion tasks, such as getting a robot to walk effectively. The key idea is to combine two existing approaches: "teacher-student" learning and "representation learning."
In the teacher-student approach, a more capable "teacher" agent provides guidance to help a less experienced "student" agent learn faster. The representation learning aspect involves the agent automatically discovering useful features or representations of the environment, rather than relying on manually engineered features.
The researchers introduce a "concurrent teacher-student" RL paradigm, where the teacher and student agents learn simultaneously, with the teacher continuously providing guidance to the student. This is designed to speed up the student's learning, improve its final performance, and enable it to successfully transfer its skills to new environments without additional training.
The goal is to develop RL agents that can control legged robots, like quadrupeds, to navigate complex real-world environments effectively. By combining the strengths of teacher-student learning and representation learning, the researchers hope to create agents that are more capable, efficient, and adaptable than those trained with conventional RL approaches.
Technical Explanation
The paper presents a "Concurrent Teacher-Student Reinforcement Learning" (CTS-RL) framework for legged locomotion tasks. In this framework, a teacher agent and a student agent learn concurrently, with the teacher providing guidance to the student throughout the training process.
The key components of the CTS-RL framework are:
- Teacher Agent: A more capable agent that has already learned effective locomotion skills, either through prior training or using expert knowledge.
- Student Agent: The less experienced agent that learns from the teacher's guidance, starting with random or limited knowledge.
- Concurrent Training: The teacher and student agents learn simultaneously, with the teacher continuously providing advice to the student.
- Representation Learning: Both the teacher and student agents learn useful representations of the environment, rather than relying on manually engineered features.
The researchers evaluate their CTS-RL approach on several challenging legged locomotion tasks, including locomotion generation on a rat-robot based on environmental changes, learning force control for legged manipulation, and learning risk-aware quadrupedal locomotion. The results show that their CTS-RL approach can accelerate learning, improve final performance, and enable zero-shot transfer to new environments, compared to conventional RL methods.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the CTS-RL framework, exploring its performance on a range of legged locomotion tasks. The authors also discuss some of the limitations and potential issues with their approach.
One potential concern is the reliance on a pre-trained teacher agent, which may not always be available or easy to obtain. The authors mention the possibility of using a large language model as a policy teacher to address this, but more research may be needed to fully understand the feasibility and effectiveness of this approach.
Additionally, the paper does not explore the potential for incorporating constraints or safety considerations into the CTS-RL framework, which could be an important consideration for real-world deployment of legged robots.
Overall, the CTS-RL approach appears to be a promising step forward in the field of legged locomotion using reinforcement learning. However, further research and experimentation will be necessary to fully understand the limitations and potential of this technique, as well as explore ways to make it more robust and widely applicable.
Conclusion
This paper introduces a novel "Concurrent Teacher-Student Reinforcement Learning" (CTS-RL) framework for legged locomotion tasks. By combining the strengths of teacher-student learning and representation learning, the CTS-RL approach can accelerate the training of RL agents, improve their final performance, and enable zero-shot transfer to new environments.
The evaluation of CTS-RL on a range of challenging legged locomotion tasks demonstrates its potential to advance the state of the art in this field. While the approach has some limitations, such as the need for a pre-trained teacher agent, the paper provides a solid foundation for further research and development in this area.
Overall, the CTS-RL framework represents an exciting step forward in the pursuit of more capable and adaptable reinforcement learning agents for controlling legged robots in complex real-world environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Combining Teacher-Student with Representation Learning: A Concurrent Teacher-Student Reinforcement Learning Paradigm for Legged Locomotion
Hongxi Wang, Haoxiang Luo, Wei Zhang, Hua Chen
Thanks to recent explosive developments of data-driven learning methodologies, reinforcement learning (RL) emerges as a promising solution to address the legged locomotion problem in robotics. In this paper, we propose CTS, a novel Concurrent Teacher-Student reinforcement learning architecture for legged locomotion over uneven terrains. Different from conventional teacher-student architecture that trains the teacher policy via RL first and then transfers the knowledge to the student policy through supervised learning, our proposed architecture trains teacher and student policy networks concurrently under the reinforcement learning paradigm. To this end, we develop a new training scheme based on a modified proximal policy gradient (PPO) method that exploits data samples collected from the interactions between both the teacher and the student policies with the environment. The effectiveness of the proposed architecture and the new training scheme is demonstrated through substantial quantitative simulation comparisons with the state-of-the-art approaches and extensive indoor and outdoor experiments with quadrupedal and point-foot bipedal robot platforms, showcasing robust and agile locomotion capability. Quantitative simulation comparisons show that our approach reduces the average velocity tracking error by up to 20% compared to the two-stage teacher-student, demonstrating significant superiority in addressing blind locomotion tasks. Videos are available at https://clearlab-sustech.github.io/concurrentTS.
Read more9/4/2024

0
PA-LOCO: Learning Perturbation-Adaptive Locomotion for Quadruped Robots
Zhiyuan Xiao, Xinyu Zhang, Xiang Zhou, Qingrui Zhang
Numerous locomotion controllers have been designed based on Reinforcement Learning (RL) to facilitate blind quadrupedal locomotion traversing challenging terrains. Nevertheless, locomotion control is still a challenging task for quadruped robots traversing diverse terrains amidst unforeseen disturbances. Recently, privileged learning has been employed to learn reliable and robust quadrupedal locomotion over various terrains based on a teacher-student architecture. However, its one-encoder structure is not adequate in addressing external force perturbations. The student policy would experience inevitable performance degradation due to the feature embedding discrepancy between the feature encoder of the teacher policy and the one of the student policy. Hence, this paper presents a privileged learning framework with multiple feature encoders and a residual policy network for robust and reliable quadruped locomotion subject to various external perturbations. The multi-encoder structure can decouple latent features from different privileged information, ultimately leading to enhanced performance of the learned policy in terms of robustness, stability, and reliability. The efficiency of the proposed feature encoding module is analyzed in depth using extensive simulation data. The introduction of the residual policy network helps mitigate the performance degradation experienced by the student policy that attempts to clone the behaviors of a teacher policy. The proposed framework is evaluated on a Unitree GO1 robot, showcasing its performance enhancement over the state-of-the-art privileged learning algorithm through extensive experiments conducted on diverse terrains. Ablation studies are conducted to illustrate the efficiency of the residual policy network.
Read more7/8/2024
🏅
0
Reinforcement Learning for Versatile, Dynamic, and Robust Bipedal Locomotion Control
Zhongyu Li, Xue Bin Peng, Pieter Abbeel, Sergey Levine, Glen Berseth, Koushil Sreenath
This paper presents a comprehensive study on using deep reinforcement learning (RL) to create dynamic locomotion controllers for bipedal robots. Going beyond focusing on a single locomotion skill, we develop a general control solution that can be used for a range of dynamic bipedal skills, from periodic walking and running to aperiodic jumping and standing. Our RL-based controller incorporates a novel dual-history architecture, utilizing both a long-term and short-term input/output (I/O) history of the robot. This control architecture, when trained through the proposed end-to-end RL approach, consistently outperforms other methods across a diverse range of skills in both simulation and the real world. The study also delves into the adaptivity and robustness introduced by the proposed RL system in developing locomotion controllers. We demonstrate that the proposed architecture can adapt to both time-invariant dynamics shifts and time-variant changes, such as contact events, by effectively using the robot's I/O history. Additionally, we identify task randomization as another key source of robustness, fostering better task generalization and compliance to disturbances. The resulting control policies can be successfully deployed on Cassie, a torque-controlled human-sized bipedal robot. This work pushes the limits of agility for bipedal robots through extensive real-world experiments. We demonstrate a diverse range of locomotion skills, including: robust standing, versatile walking, fast running with a demonstration of a 400-meter dash, and a diverse set of jumping skills, such as standing long jumps and high jumps.
Read more8/27/2024
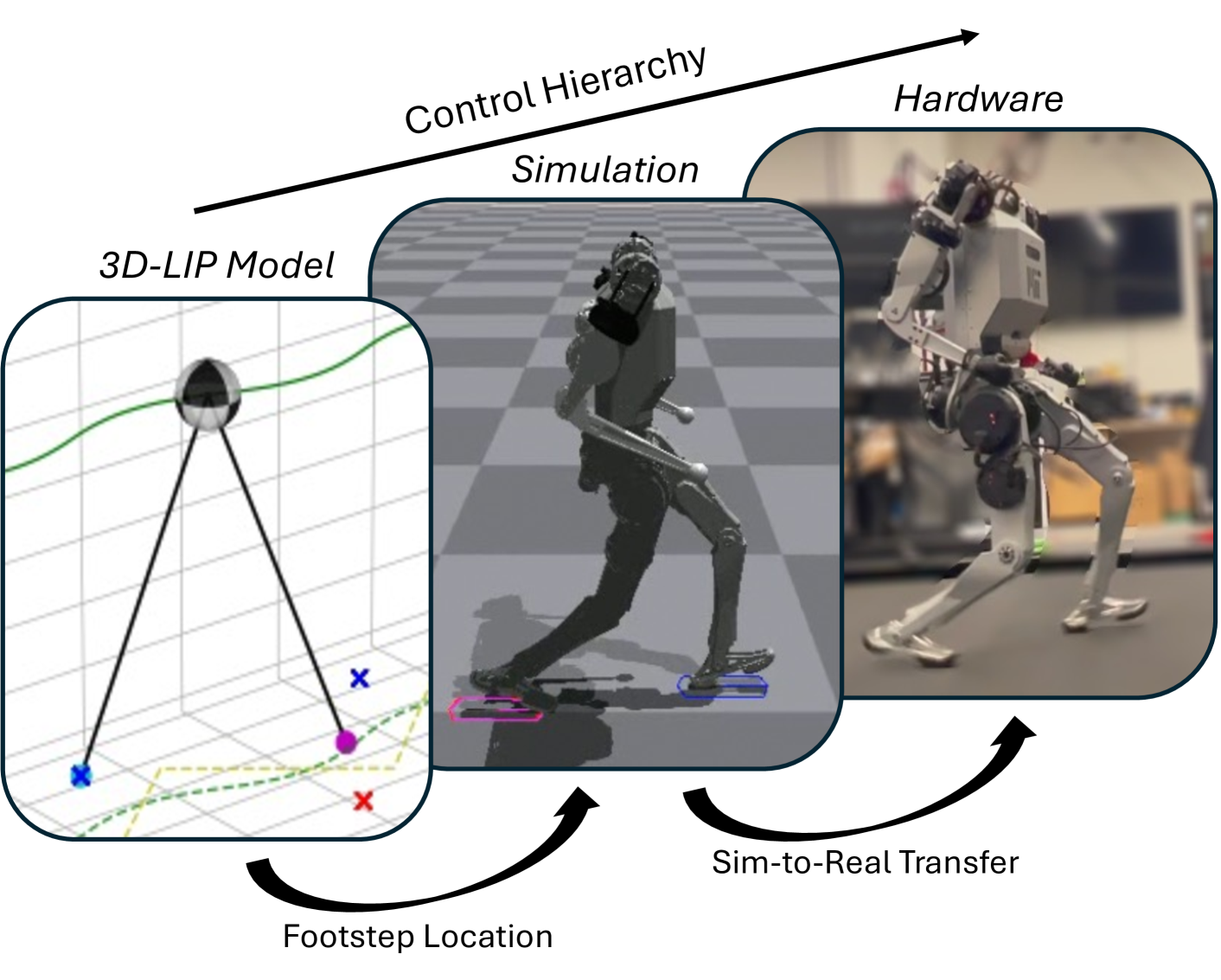
0
Integrating Model-Based Footstep Planning with Model-Free Reinforcement Learning for Dynamic Legged Locomotion
Ho Jae Lee, Seungwoo Hong, Sangbae Kim
In this work, we introduce a control framework that combines model-based footstep planning with Reinforcement Learning (RL), leveraging desired footstep patterns derived from the Linear Inverted Pendulum (LIP) dynamics. Utilizing the LIP model, our method forward predicts robot states and determines the desired foot placement given the velocity commands. We then train an RL policy to track the foot placements without following the full reference motions derived from the LIP model. This partial guidance from the physics model allows the RL policy to integrate the predictive capabilities of the physics-informed dynamics and the adaptability characteristics of the RL controller without overfitting the policy to the template model. Our approach is validated on the MIT Humanoid, demonstrating that our policy can achieve stable yet dynamic locomotion for walking and turning. We further validate the adaptability and generalizability of our policy by extending the locomotion task to unseen, uneven terrain. During the hardware deployment, we have achieved forward walking speeds of up to 1.5 m/s on a treadmill and have successfully performed dynamic locomotion maneuvers such as 90-degree and 180-degree turns.
Read more8/6/2024