CulturalTeaming: AI-Assisted Interactive Red-Teaming for Challenging LLMs' (Lack of) Multicultural Knowledge

0

Sign in to get full access
Overview
- This paper presents a novel method called "\methodemoji\method" for revealing the multicultural knowledge gaps of large language models (LLMs) through AI-assisted interactive red-teaming.
- The approach involves using AI agents to challenge LLMs on their understanding of diverse cultural contexts, with the goal of identifying areas where the models lack robust multicultural knowledge.
- The authors demonstrate the application of \methodemoji\method on several popular LLMs and discuss the implications for improving the cultural competence of these powerful AI systems.
Plain English Explanation
The research paper explores a new technique called "\methodemoji\method" that uses artificial intelligence (AI) to test the cultural knowledge of large language models (LLMs) - powerful AI systems that can generate human-like text. The key idea is to have AI "red teams" interact with the LLMs and challenge them on their understanding of diverse cultural contexts from around the world.
This interactive red-teaming approach is designed to reveal gaps or weaknesses in the LLMs' multicultural knowledge. For example, the AI red teams might ask the LLMs about cultural traditions, beliefs, or social norms from different countries and regions, and see how accurately the LLMs respond. By identifying areas where the LLMs struggle, the researchers hope to inform efforts to improve the cultural competence of these powerful AI systems.
The paper demonstrates applying \methodemoji\method to several popular LLMs and discusses the implications for enhancing the multicultural understanding of AI language models. This research aligns with broader efforts to make AI systems more inclusive, ethical, and beneficial to diverse communities, as highlighted in related works like Metal: Towards Multilingual Meta-Evaluation, Apprentices to Research Assistants: Advancing Research with Large Language Models, and Red-Teaming: A Game-Theoretic Framework for Red-Teaming.
Technical Explanation
The paper introduces a new methodology called "\methodemoji\method" that leverages AI-assisted interactive red-teaming to challenge the multicultural knowledge of large language models (LLMs). The core idea is to create AI "red teams" that engage the target LLMs in interactive dialogues, probing their understanding of diverse cultural contexts from around the world.
The \methodemoji\method framework involves several key components:
-
AI Red Team Agents: The researchers develop AI agents that are trained to take on the role of "red teamers" - adversaries who challenge the LLMs' cultural knowledge through interactive dialogues.
-
Cultural Knowledge Prompts: The red team agents are equipped with a curated set of prompts that cover a wide range of cultural topics, such as traditions, beliefs, social norms, and everyday practices from different regions and communities.
-
Interaction and Evaluation: The red team agents engage the target LLMs in interactive sessions, posing the cultural knowledge prompts and evaluating the LLMs' responses. Metrics like accuracy, coherence, and cultural sensitivity are used to assess the LLMs' performance.
-
Identification of Knowledge Gaps: By analyzing the LLMs' responses, the researchers are able to identify areas where the models demonstrate a lack of robust multicultural knowledge, revealing potential blindspots or biases.
The paper demonstrates the application of \methodemoji\method on several popular LLMs, including GPT-3, BERT, and T5. The results highlight significant gaps in the models' understanding of diverse cultural contexts, particularly for non-Western and underrepresented cultures. These findings underscore the importance of improving the cultural competence of LLMs, as also discussed in related works like Exploring Autonomous Agents through the Lens of Large Language Models and DialogBench: Evaluating Large Language Models as Human-like Dialogue Agents.
Critical Analysis
The \methodemoji\method approach presented in the paper offers a novel and promising way to challenge the multicultural knowledge of large language models (LLMs). By using AI-assisted interactive red-teaming, the researchers are able to uncover significant gaps in the LLMs' understanding of diverse cultural contexts, which is a crucial step towards improving the cultural competence of these powerful AI systems.
One potential limitation of the study is the scope of the cultural knowledge prompts used by the red team agents. While the authors state that the prompts cover a wide range of topics, it's possible that there are still areas of cultural knowledge that were not adequately represented. Expanding the prompt set to include an even more diverse and comprehensive set of cultural topics could help strengthen the findings.
Additionally, the paper does not delve deeply into the reasons behind the LLMs' struggles with certain cultural contexts. Further investigation into the underlying factors, such as biases in the training data or flaws in the models' architectures, could provide valuable insights for guiding future improvements.
Despite these minor caveats, the \methodemoji\method approach represents an important contribution to the field of AI safety and ethics. By highlighting the multicultural knowledge gaps of LLMs, this research encourages the development of more culturally-aware and inclusive AI systems that can better serve diverse communities, as discussed in the related work on Red-Teaming: A Game-Theoretic Framework for Red-Teaming.
Conclusion
The research paper presents a novel method called "\methodemoji\method" that uses AI-assisted interactive red-teaming to reveal the multicultural knowledge gaps of large language models (LLMs). By having AI "red team" agents challenge the LLMs on their understanding of diverse cultural contexts, the researchers were able to identify significant blindspots and biases in the models' knowledge.
The findings of this study underscore the importance of improving the cultural competence of powerful AI systems like LLMs, as they become increasingly integrated into various domains and interact with diverse communities. The \methodemoji\method approach offers a promising new tool for driving progress in this direction, complementing other efforts to make AI more inclusive, ethical, and beneficial to all.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CulturalTeaming: AI-Assisted Interactive Red-Teaming for Challenging LLMs' (Lack of) Multicultural Knowledge
Yu Ying Chiu, Liwei Jiang, Maria Antoniak, Chan Young Park, Shuyue Stella Li, Mehar Bhatia, Sahithya Ravi, Yulia Tsvetkov, Vered Shwartz, Yejin Choi
Frontier large language models (LLMs) are developed by researchers and practitioners with skewed cultural backgrounds and on datasets with skewed sources. However, LLMs' (lack of) multicultural knowledge cannot be effectively assessed with current methods for developing benchmarks. Existing multicultural evaluations primarily rely on expensive and restricted human annotations or potentially outdated internet resources. Thus, they struggle to capture the intricacy, dynamics, and diversity of cultural norms. LLM-generated benchmarks are promising, yet risk propagating the same biases they are meant to measure. To synergize the creativity and expert cultural knowledge of human annotators and the scalability and standardizability of LLM-based automation, we introduce CulturalTeaming, an interactive red-teaming system that leverages human-AI collaboration to build truly challenging evaluation dataset for assessing the multicultural knowledge of LLMs, while improving annotators' capabilities and experiences. Our study reveals that CulturalTeaming's various modes of AI assistance support annotators in creating cultural questions, that modern LLMs fail at, in a gamified manner. Importantly, the increased level of AI assistance (e.g., LLM-generated revision hints) empowers users to create more difficult questions with enhanced perceived creativity of themselves, shedding light on the promises of involving heavier AI assistance in modern evaluation dataset creation procedures. Through a series of 1-hour workshop sessions, we gather CULTURALBENCH-V0.1, a compact yet high-quality evaluation dataset with users' red-teaming attempts, that different families of modern LLMs perform with accuracy ranging from 37.7% to 72.2%, revealing a notable gap in LLMs' multicultural proficiency.
Read more4/11/2024
0
Beyond Metrics: Evaluating LLMs' Effectiveness in Culturally Nuanced, Low-Resource Real-World Scenarios
Millicent Ochieng, Varun Gumma, Sunayana Sitaram, Jindong Wang, Vishrav Chaudhary, Keshet Ronen, Kalika Bali, Jacki O'Neill
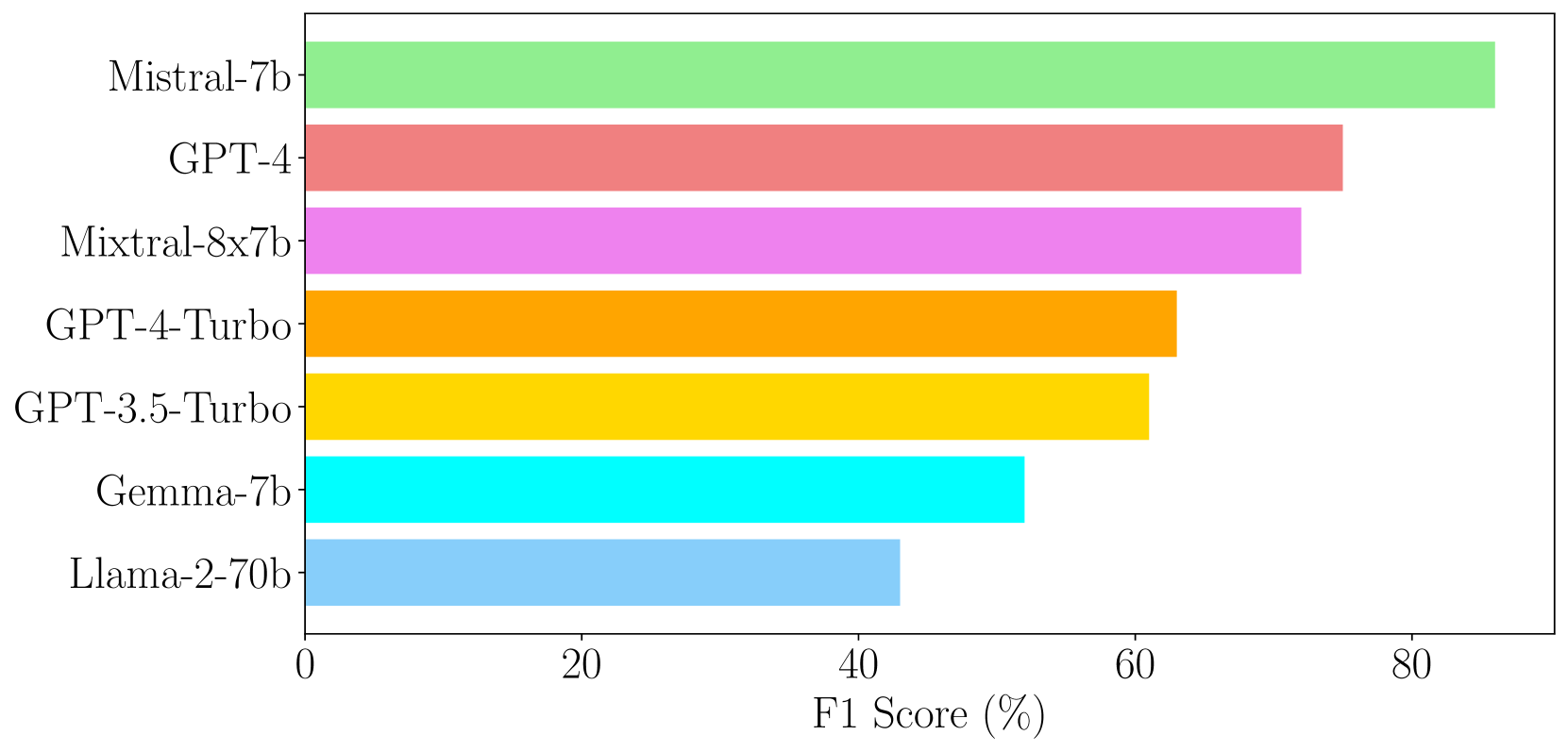
The deployment of Large Language Models (LLMs) in real-world applications presents both opportunities and challenges, particularly in multilingual and code-mixed communication settings. This research evaluates the performance of seven leading LLMs in sentiment analysis on a dataset derived from multilingual and code-mixed WhatsApp chats, including Swahili, English and Sheng. Our evaluation includes both quantitative analysis using metrics like F1 score and qualitative assessment of LLMs' explanations for their predictions. We find that, while Mistral-7b and Mixtral-8x7b achieved high F1 scores, they and other LLMs such as GPT-3.5-Turbo, Llama-2-70b, and Gemma-7b struggled with understanding linguistic and contextual nuances, as well as lack of transparency in their decision-making process as observed from their explanations. In contrast, GPT-4 and GPT-4-Turbo excelled in grasping diverse linguistic inputs and managing various contextual information, demonstrating high consistency with human alignment and transparency in their decision-making process. The LLMs however, encountered difficulties in incorporating cultural nuance especially in non-English settings with GPT-4s doing so inconsistently. The findings emphasize the necessity of continuous improvement of LLMs to effectively tackle the challenges of culturally nuanced, low-resource real-world settings and the need for developing evaluation benchmarks for capturing these issues.
Read more6/14/2024
⛏️
0
CSRT: Evaluation and Analysis of LLMs using Code-Switching Red-Teaming Dataset
Haneul Yoo, Yongjin Yang, Hwaran Lee
Recent studies in large language models (LLMs) shed light on their multilingual ability and safety, beyond conventional tasks in language modeling. Still, current benchmarks reveal their inability to comprehensively evaluate them and are excessively dependent on manual annotations. In this paper, we introduce code-switching red-teaming (CSRT), a simple yet effective red-teaming technique that simultaneously tests multilingual understanding and safety of LLMs. We release the CSRT dataset, which comprises 315 code-switching queries combining up to 10 languages and eliciting a wide range of undesirable behaviors. Through extensive experiments with ten state-of-the-art LLMs, we demonstrate that CSRT significantly outperforms existing multilingual red-teaming techniques, achieving 46.7% more attacks than existing methods in English. We analyze the harmful responses toward the CSRT dataset concerning various aspects under ablation studies with 16K samples, including but not limited to scaling laws, unsafe behavior categories, and input conditions for optimal data generation. Additionally, we validate the extensibility of CSRT, by generating code-switching attack prompts with monolingual data.
Read more6/26/2024

0
Holistic Automated Red Teaming for Large Language Models through Top-Down Test Case Generation and Multi-turn Interaction
Jinchuan Zhang, Yan Zhou, Yaxin Liu, Ziming Li, Songlin Hu
Automated red teaming is an effective method for identifying misaligned behaviors in large language models (LLMs). Existing approaches, however, often focus primarily on improving attack success rates while overlooking the need for comprehensive test case coverage. Additionally, most of these methods are limited to single-turn red teaming, failing to capture the multi-turn dynamics of real-world human-machine interactions. To overcome these limitations, we propose HARM (Holistic Automated Red teaMing), which scales up the diversity of test cases using a top-down approach based on an extensible, fine-grained risk taxonomy. Our method also leverages a novel fine-tuning strategy and reinforcement learning techniques to facilitate multi-turn adversarial probing in a human-like manner. Experimental results demonstrate that our framework enables a more systematic understanding of model vulnerabilities and offers more targeted guidance for the alignment process.
Read more9/26/2024