CuTS: Customizable Tabular Synthetic Data Generation

0
Sign in to get full access
Overview
- This paper presents a new approach for generating synthetic tabular data that can be programmatically controlled and customized.
- The method allows users to specify the desired statistical properties and distributions of the generated data, enabling the creation of diverse and representative datasets.
- The authors demonstrate the effectiveness of their approach through extensive experiments and comparisons to existing data synthesis techniques.
Plain English Explanation
The paper introduces a novel way to create artificial datasets that can be tailored to specific needs. Often, researchers and organizations require realistic-looking data to test their algorithms or models, but obtaining such data can be challenging due to privacy concerns or lack of access.
The proposed method allows users to define the statistical characteristics they want the generated data to have, such as the range of values, correlations between columns, or the frequency of certain patterns. The system then automatically produces a synthetic dataset that matches these specifications. This gives users much more control and flexibility compared to existing data synthesis algorithms, which may not be able to capture all the desired properties of the data.
The researchers demonstrate the effectiveness of their approach through extensive testing, showing that the generated data can faithfully reproduce the key statistical features of real-world datasets while also maintaining differential privacy to protect sensitive information. This advance could be particularly useful for organizations that need to work with sensitive data but want to generate representative synthetic versions for various purposes.
Technical Explanation
The core of the proposed approach is a generative model that can learn the underlying distribution of the input data and then sample new instances that match the desired statistical properties. The authors use a mixture of Gaussian distributions to model the data, with each column represented by a separate Gaussian component.
To control the generated data, the user specifies target statistics for each column, such as the mean, standard deviation, and skewness. The generative model is then optimized to produce samples that minimize the difference between the target statistics and the actual statistics of the generated data.
The authors evaluate their method on several real-world datasets, comparing the synthetic data to the original data in terms of statistical similarity as well as performance on downstream machine learning tasks. The results show that the generated data closely matches the key characteristics of the original data while also providing strong differential privacy guarantees.
Critical Analysis
The paper presents a well-designed and comprehensive evaluation of the proposed data generation approach. The authors carefully consider various statistical metrics and downstream applications to assess the quality and utility of the synthetic data.
One potential limitation is that the method may struggle to capture complex, nonlinear relationships or interactions between columns in the data. The Gaussian mixture model may not be expressive enough to model all types of data distributions and dependencies. Exploring alternative generative models, such as generative adversarial networks or variational autoencoders, could be an area for future research.
Additionally, the paper does not provide much insight into the computational complexity or training time of the proposed approach, which could be important considerations for practical applications involving large-scale datasets. Investigating the scalability of the method would be a valuable addition to the analysis.
Overall, the research presents a promising direction for controllable and privacy-preserving data generation, with the potential to significantly benefit organizations working with sensitive data. The authors have made a valuable contribution to the field of tabular data synthesis.
Conclusion
The paper introduces a novel approach for generating synthetic tabular data that can be programmatically controlled and customized. By allowing users to specify the desired statistical properties of the generated data, the method enables the creation of diverse and representative datasets that can be used for a variety of applications, including machine learning model development, algorithm testing, and data analysis.
The authors demonstrate the effectiveness of their approach through extensive experiments and comparisons to existing data synthesis techniques. The results show that the generated data closely matches the key characteristics of real-world datasets while also providing strong differential privacy guarantees to protect sensitive information.
This work represents an important advancement in the field of tabular data synthesis, with the potential to significantly benefit organizations and researchers who require realistic-looking data but face challenges in obtaining or using real data due to privacy concerns or other limitations. The proposed method offers a powerful and flexible solution for generating synthetic data that can be tailored to specific needs, opening up new possibilities for data-driven research and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CuTS: Customizable Tabular Synthetic Data Generation
Mark Vero, Mislav Balunovi'c, Martin Vechev
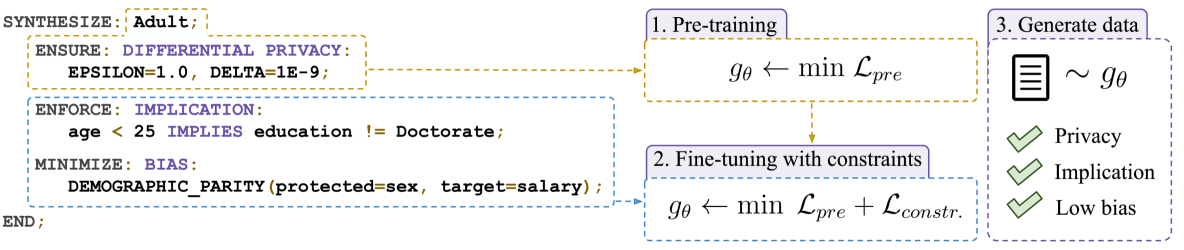
Privacy, data quality, and data sharing concerns pose a key limitation for tabular data applications. While generating synthetic data resembling the original distribution addresses some of these issues, most applications would benefit from additional customization on the generated data. However, existing synthetic data approaches are limited to particular constraints, e.g., differential privacy (DP) or fairness. In this work, we introduce CuTS, the first customizable synthetic tabular data generation framework. Customization in CuTS is achieved via declarative statistical and logical expressions, supporting a wide range of requirements (e.g., DP or fairness, among others). To ensure high synthetic data quality in the presence of custom specifications, CuTS is pre-trained on the original dataset and fine-tuned on a differentiable loss automatically derived from the provided specifications using novel relaxations. We evaluate CuTS over four datasets and on numerous custom specifications, outperforming state-of-the-art specialized approaches on several tasks while being more general. In particular, at the same fairness level, we achieve 2.3% higher downstream accuracy than the state-of-the-art in fair synthetic data generation on the Adult dataset.
Read more6/4/2024
0
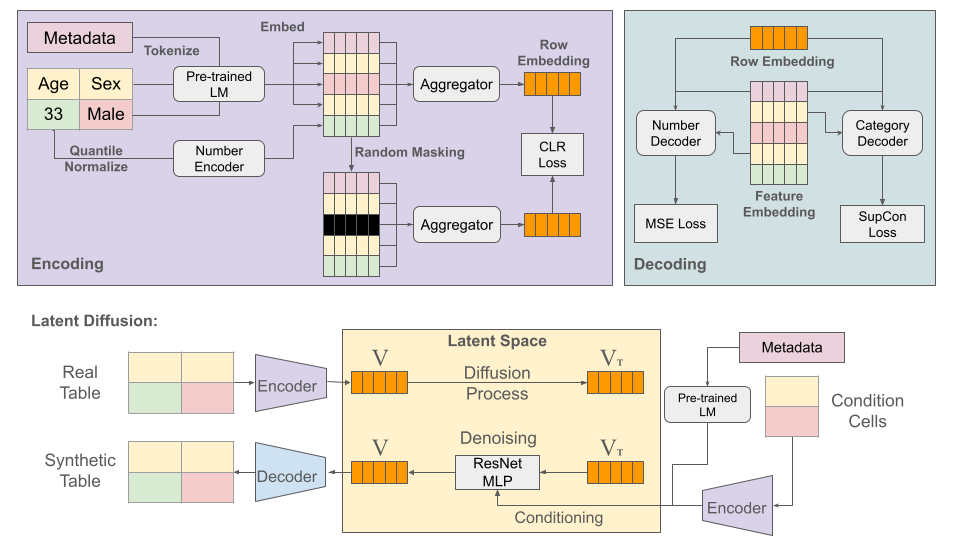
CTSyn: A Foundational Model for Cross Tabular Data Generation
Xiaofeng Lin, Chenheng Xu, Matthew Yang, Guang Cheng
Generative Foundation Models (GFMs) have produced synthetic data with remarkable quality in modalities such as images and text. However, applying GFMs to tabular data poses significant challenges due to the inherent heterogeneity of table features. Existing cross-table learning frameworks are hindered by the absence of both a generative model backbone and a decoding mechanism for heterogeneous feature values. To overcome these limitations, we introduce the Cross-Table Synthesizer (CTSyn), a diffusion-based foundational model tailored for tabular data generation. CTSyn introduces three major components: an aggregator that consolidates heterogeneous tables into a unified latent space; a conditional latent diffusion model for sampling from this space; and type-specific decoders that reconstruct values of varied data types from sampled latent vectors. Extensive testing on real-world datasets reveals that CTSyn not only significantly outperforms existing table synthesizers in utility and diversity, but also uniquely enhances performances of downstream machine learning beyond what is achievable with real data, thus establishing a new paradigm for synthetic data generation.
Read more6/10/2024
0
Differentially Private Synthetic High-dimensional Tabular Stream
Girish Kumar, Thomas Strohmer, Roman Vershynin
While differentially private synthetic data generation has been explored extensively in the literature, how to update this data in the future if the underlying private data changes is much less understood. We propose an algorithmic framework for streaming data that generates multiple synthetic datasets over time, tracking changes in the underlying private data. Our algorithm satisfies differential privacy for the entire input stream (continual differential privacy) and can be used for high-dimensional tabular data. Furthermore, we show the utility of our method via experiments on real-world datasets. The proposed algorithm builds upon a popular select, measure, fit, and iterate paradigm (used by offline synthetic data generation algorithms) and private counters for streams.
Read more9/4/2024
👨🏫
0
A supervised generative optimization approach for tabular data
Shinpei Nakamura-Sakai, Fadi Hamad, Saheed Obitayo, Vamsi K. Potluru
Synthetic data generation has emerged as a crucial topic for financial institutions, driven by multiple factors, such as privacy protection and data augmentation. Many algorithms have been proposed for synthetic data generation but reaching the consensus on which method we should use for the specific data sets and use cases remains challenging. Moreover, the majority of existing approaches are ``unsupervised'' in the sense that they do not take into account the downstream task. To address these issues, this work presents a novel synthetic data generation framework. The framework integrates a supervised component tailored to the specific downstream task and employs a meta-learning approach to learn the optimal mixture distribution of existing synthetic distributions.
Read more5/13/2024