Navigating Tabular Data Synthesis Research: Understanding User Needs and Tool Capabilities
2405.20959
0
0
Abstract
In an era of rapidly advancing data-driven applications, there is a growing demand for data in both research and practice. Synthetic data have emerged as an alternative when no real data is available (e.g., due to privacy regulations). Synthesizing tabular data presents unique and complex challenges, especially handling (i) missing values, (ii) dataset imbalance, (iii) diverse column types, and (iv) complex data distributions, as well as preserving (i) column correlations, (ii) temporal dependencies, and (iii) integrity constraints (e.g., functional dependencies) present in the original dataset. While substantial progress has been made recently in the context of generational models, there is no one-size-fits-all solution for tabular data today, and choosing the right tool for a given task is therefore no trivial task. In this paper, we survey the state of the art in Tabular Data Synthesis (TDS), examine the needs of users by defining a set of functional and non-functional requirements, and compile the challenges associated with meeting those needs. In addition, we evaluate the reported performance of 36 popular research TDS tools about these requirements and develop a decision guide to help users find suitable TDS tools for their applications. The resulting decision guide also identifies significant research gaps.
Create account to get full access
Overview
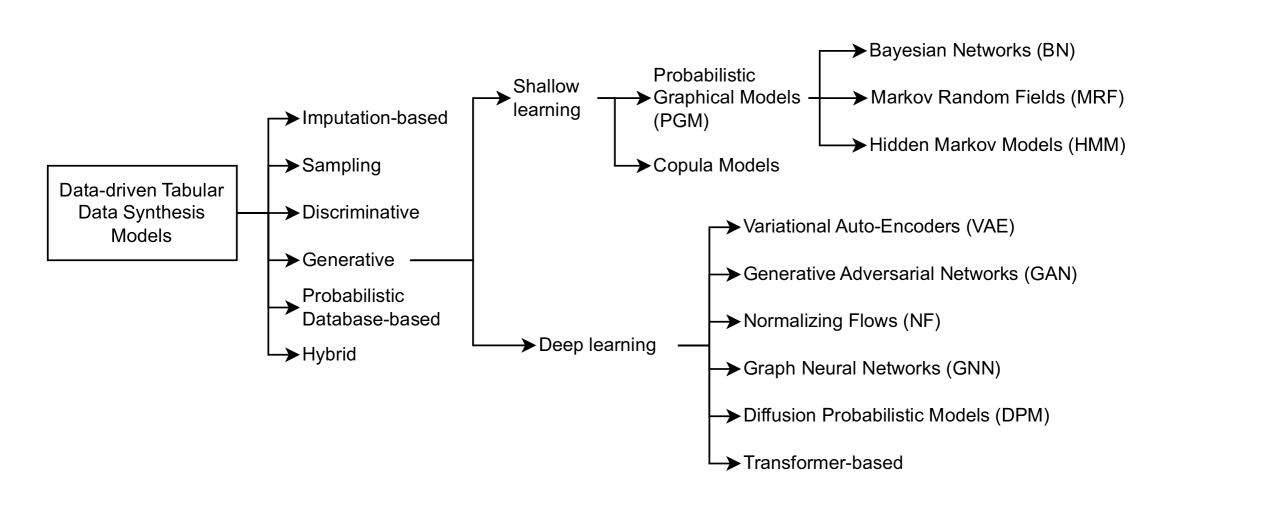
- The paper discusses the current state of research on tabular data synthesis, which involves generating realistic-looking synthetic data that preserves the statistical properties of the original dataset.
- It covers the various purposes of tabular data synthesis, such as protecting privacy, augmenting small datasets, and benchmarking machine learning models.
- The paper also reviews the related work in this field, including diffusion-based models and structured evaluation approaches.
Plain English Explanation
Tabular data, such as spreadsheets or database tables, often contain sensitive information that cannot be shared directly. Researchers have developed techniques to generate synthetic versions of this data that look similar but don't reveal the original information. This process is called tabular data synthesis.
The main goals of tabular data synthesis are to protect people's privacy, create larger datasets for training machine learning models, and test the performance of those models. By generating realistic-looking synthetic data, researchers can share information without compromising confidentiality.
The paper reviews the latest advancements in this field, including methods that can handle different data types (e.g., numerical, categorical) and preserve the statistical properties of the original data. It also discusses ways to evaluate the quality of the synthetic data, ensuring it is a faithful representation of the real-world information.
Technical Explanation
The paper provides a comprehensive overview of the current state of research on tabular data synthesis. It explores the various purposes of tabular data synthesis, including privacy protection, dataset augmentation, and model benchmarking.
The related work section covers a range of approaches, such as supervised generative optimization for generating synthetic data, score-based models for handling mixed data types, and diffusion-based models for ensuring balanced synthetic data. The paper also highlights the importance of structured evaluation to assess the quality and utility of the generated synthetic data.
Critical Analysis
The paper provides a comprehensive overview of the current state of tabular data synthesis research, but it also acknowledges several limitations and areas for further exploration. For example, the authors note that many existing methods focus on specific data types or assume independence between features, which may not always be the case in real-world datasets.
Additionally, the paper highlights the need for more robust evaluation frameworks to assess the quality and utility of synthetic data, as the current approaches may not capture all the nuances of the original data. The authors also suggest that future research should explore the impact of synthetic data on downstream machine learning tasks, as the fidelity of the synthetic data can have significant implications for model performance and reliability.
Conclusion
Overall, the paper provides a valuable contribution to the field of tabular data synthesis by synthesizing the current research and identifying key challenges and opportunities for future work. As the demand for data-driven decision-making continues to grow, the ability to generate high-quality synthetic data while preserving privacy and other important properties will become increasingly crucial. The insights and recommendations presented in this paper can help guide researchers and practitioners in developing more robust and reliable tabular data synthesis methods.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Systematic Assessment of Tabular Data Synthesis Algorithms
Yuntao Du, Ninghui Li
0
0
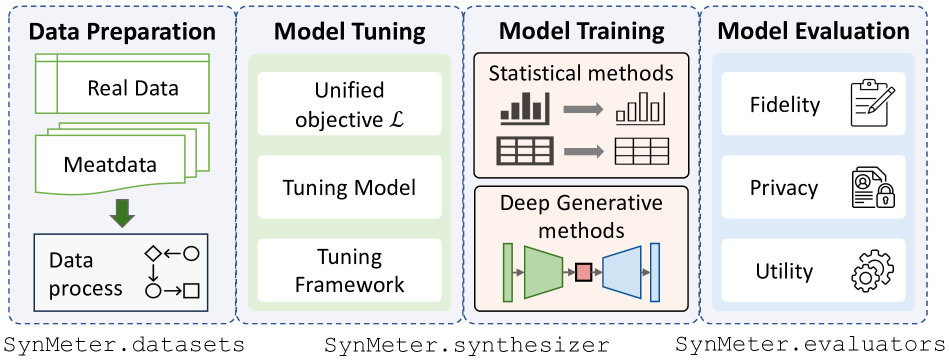
Data synthesis has been advocated as an important approach for utilizing data while protecting data privacy. A large number of tabular data synthesis algorithms (which we call synthesizers) have been proposed. Some synthesizers satisfy Differential Privacy, while others aim to provide privacy in a heuristic fashion. A comprehensive understanding of the strengths and weaknesses of these synthesizers remains elusive due to drawbacks in evaluation metrics and missing head-to-head comparisons of newly developed synthesizers that take advantage of diffusion models and large language models with state-of-the-art marginal-based synthesizers. In this paper, we present a systematic evaluation framework for assessing tabular data synthesis algorithms. Specifically, we examine and critique existing evaluation metrics, and introduce a set of new metrics in terms of fidelity, privacy, and utility to address their limitations. Based on the proposed metrics, we also devise a unified objective for tuning, which can consistently improve the quality of synthetic data for all methods. We conducted extensive evaluations of 8 different types of synthesizers on 12 real-world datasets and identified some interesting findings, which offer new directions for privacy-preserving data synthesis.
4/16/2024
👨🏫
A supervised generative optimization approach for tabular data
Shinpei Nakamura-Sakai, Fadi Hamad, Saheed Obitayo, Vamsi K. Potluru
0
0
Synthetic data generation has emerged as a crucial topic for financial institutions, driven by multiple factors, such as privacy protection and data augmentation. Many algorithms have been proposed for synthetic data generation but reaching the consensus on which method we should use for the specific data sets and use cases remains challenging. Moreover, the majority of existing approaches are ``unsupervised'' in the sense that they do not take into account the downstream task. To address these issues, this work presents a novel synthetic data generation framework. The framework integrates a supervised component tailored to the specific downstream task and employs a meta-learning approach to learn the optimal mixture distribution of existing synthetic distributions.
5/13/2024
Mixed-Type Tabular Data Synthesis with Score-based Diffusion in Latent Space
Hengrui Zhang, Jiani Zhang, Balasubramaniam Srinivasan, Zhengyuan Shen, Xiao Qin, Christos Faloutsos, Huzefa Rangwala, George Karypis
0
0
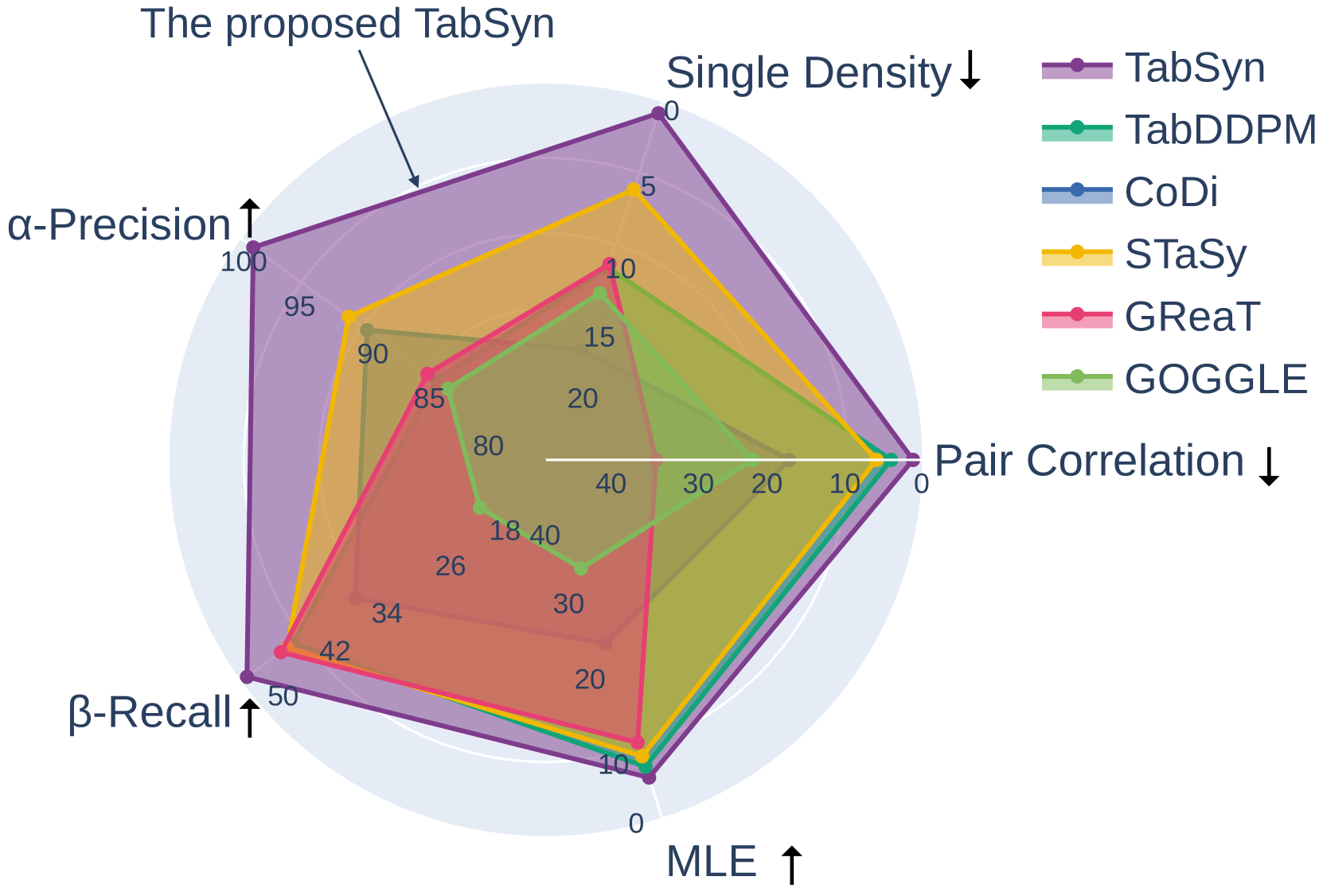
Recent advances in tabular data generation have greatly enhanced synthetic data quality. However, extending diffusion models to tabular data is challenging due to the intricately varied distributions and a blend of data types of tabular data. This paper introduces Tabsyn, a methodology that synthesizes tabular data by leveraging a diffusion model within a variational autoencoder (VAE) crafted latent space. The key advantages of the proposed Tabsyn include (1) Generality: the ability to handle a broad spectrum of data types by converting them into a single unified space and explicitly capture inter-column relations; (2) Quality: optimizing the distribution of latent embeddings to enhance the subsequent training of diffusion models, which helps generate high-quality synthetic data, (3) Speed: much fewer number of reverse steps and faster synthesis speed than existing diffusion-based methods. Extensive experiments on six datasets with five metrics demonstrate that Tabsyn outperforms existing methods. Specifically, it reduces the error rates by 86% and 67% for column-wise distribution and pair-wise column correlation estimations compared with the most competitive baselines.
5/14/2024
CTSyn: A Foundational Model for Cross Tabular Data Generation
Xiaofeng Lin, Chenheng Xu, Matthew Yang, Guang Cheng
0
0
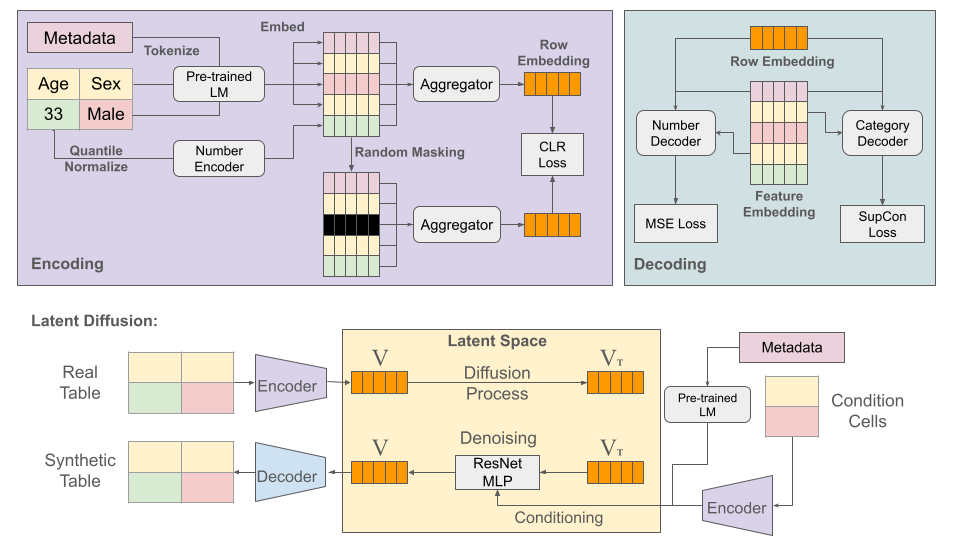
Generative Foundation Models (GFMs) have produced synthetic data with remarkable quality in modalities such as images and text. However, applying GFMs to tabular data poses significant challenges due to the inherent heterogeneity of table features. Existing cross-table learning frameworks are hindered by the absence of both a generative model backbone and a decoding mechanism for heterogeneous feature values. To overcome these limitations, we introduce the Cross-Table Synthesizer (CTSyn), a diffusion-based foundational model tailored for tabular data generation. CTSyn introduces three major components: an aggregator that consolidates heterogeneous tables into a unified latent space; a conditional latent diffusion model for sampling from this space; and type-specific decoders that reconstruct values of varied data types from sampled latent vectors. Extensive testing on real-world datasets reveals that CTSyn not only significantly outperforms existing table synthesizers in utility and diversity, but also uniquely enhances performances of downstream machine learning beyond what is achievable with real data, thus establishing a new paradigm for synthetic data generation.
6/10/2024