D3RoMa: Disparity Diffusion-based Depth Sensing for Material-Agnostic Robotic Manipulation

0

Sign in to get full access
Overview
- This paper presents D3RoMa, a novel depth sensing approach for robotic manipulation that is robust to material properties.
- D3RoMa uses a disparity diffusion model to estimate depth from stereo camera inputs, overcoming challenges with transparent or reflective objects.
- The proposed method is material-agnostic, meaning it can handle a wide range of surfaces without requiring specialized sensors or calibration.
- Experiments show that D3RoMa outperforms traditional stereo vision and learning-based depth estimation for robotic grasping and manipulation tasks.
Plain English Explanation
Robots often use cameras to perceive the world around them and guide their actions. However, traditional stereo vision can struggle with certain materials like glass or shiny surfaces that don't reflect light in a simple way.
D3RoMa solves this problem by using a "disparity diffusion" technique. This means it analyzes the differences between the left and right camera images to estimate the depth of objects, without relying on specific material properties. The key insight is that the way light "diffuses" or spreads out can provide depth cues, even for transparent or reflective things.
Compared to other depth estimation approaches, D3RoMa has the advantage of being material-agnostic. This makes it a more versatile tool for robotics applications like grasping and manipulation, where the robot needs to accurately perceive its surroundings regardless of the object materials.
Technical Explanation
The core of D3RoMa is a disparity diffusion model that estimates depth from stereo camera inputs. This model takes the left and right camera images, calculates the differences (disparities) between them, and then iteratively "diffuses" these disparities to produce a dense depth map.
The key innovation is that the diffusion process is designed to be robust to non-Lambertian surfaces like transparent or reflective objects. Traditional stereo vision relies on assumptions about how light reflects off surfaces, but D3RoMa can handle a wider range of materials without requiring specialized sensors or calibration.
The authors evaluated D3RoMa on a variety of robotic manipulation tasks, including grasping and placing objects. Compared to baseline methods, D3RoMa demonstrated superior depth estimation accuracy and enabled more successful robotic interactions, even with challenging materials.
Critical Analysis
The authors acknowledge that D3RoMa has some limitations. For example, it may struggle with highly specular surfaces where the disparity information is very sparse. The iterative nature of the diffusion process also means it has higher computational requirements compared to some learning-based depth estimation approaches.
Additionally, the paper does not provide extensive benchmarking against state-of-the-art monocular depth estimation methods, which have also shown promising results for material-agnostic depth sensing. Further research could explore hybrid approaches that combine disparity diffusion with other depth cues.
Overall, D3RoMa represents a valuable contribution to the field of robotic perception, offering a material-agnostic depth sensing solution that can enhance the capabilities of robotic manipulation systems. The continued development of robust, generalizable depth estimation techniques will be crucial for enabling more sophisticated and versatile robot interactions in the real world.
Conclusion
In summary, the D3RoMa paper presents a novel depth sensing approach that uses a disparity diffusion model to estimate depth from stereo cameras, while being robust to a wide range of surface materials. This material-agnostic capability makes D3RoMa a promising tool for robotic manipulation tasks, where accurate 3D perception is essential.
The key technical innovation is the diffusion-based depth estimation process that can handle non-Lambertian surfaces, overcoming the limitations of traditional stereo vision. Experimental results demonstrate the advantages of D3RoMa over baseline methods, opening up new possibilities for more advanced and versatile robotic systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
D3RoMa: Disparity Diffusion-based Depth Sensing for Material-Agnostic Robotic Manipulation
Songlin Wei, Haoran Geng, Jiayi Chen, Congyue Deng, Wenbo Cui, Chengyang Zhao, Xiaomeng Fang, Leonidas Guibas, He Wang
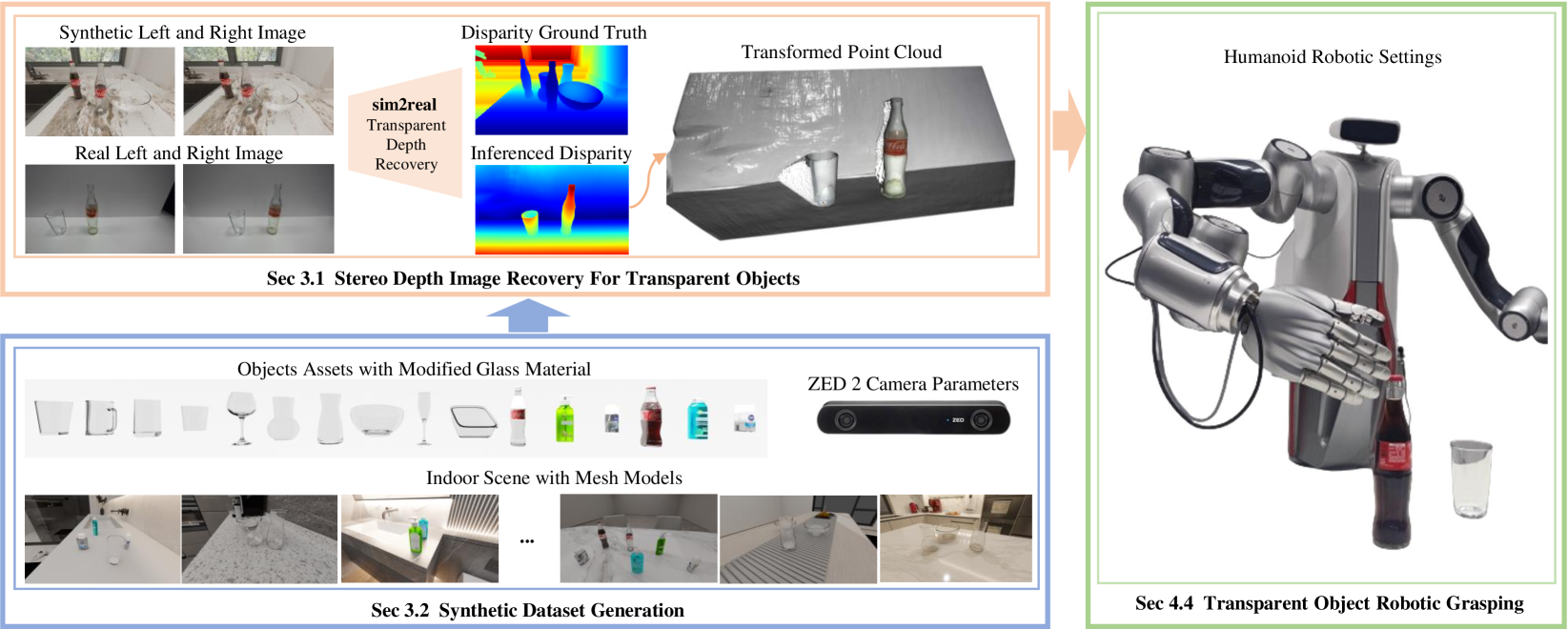
Depth sensing is an important problem for 3D vision-based robotics. Yet, a real-world active stereo or ToF depth camera often produces noisy and incomplete depth which bottlenecks robot performances. In this work, we propose D3RoMa, a learning-based depth estimation framework on stereo image pairs that predicts clean and accurate depth in diverse indoor scenes, even in the most challenging scenarios with translucent or specular surfaces where classical depth sensing completely fails. Key to our method is that we unify depth estimation and restoration into an image-to-image translation problem by predicting the disparity map with a denoising diffusion probabilistic model. At inference time, we further incorporated a left-right consistency constraint as classifier guidance to the diffusion process. Our framework combines recently advanced learning-based approaches and geometric constraints from traditional stereo vision. For model training, we create a large scene-level synthetic dataset with diverse transparent and specular objects to compensate for existing tabletop datasets. The trained model can be directly applied to real-world in-the-wild scenes and achieve state-of-the-art performance in multiple public depth estimation benchmarks. Further experiments in real environments show that accurate depth prediction significantly improves robotic manipulation in various scenarios.
Read more9/26/2024
0
ClearDepth: Enhanced Stereo Perception of Transparent Objects for Robotic Manipulation
Kaixin Bai, Huajian Zeng, Lei Zhang, Yiwen Liu, Hongli Xu, Zhaopeng Chen, Jianwei Zhang
Transparent object depth perception poses a challenge in everyday life and logistics, primarily due to the inability of standard 3D sensors to accurately capture depth on transparent or reflective surfaces. This limitation significantly affects depth map and point cloud-reliant applications, especially in robotic manipulation. We developed a vision transformer-based algorithm for stereo depth recovery of transparent objects. This approach is complemented by an innovative feature post-fusion module, which enhances the accuracy of depth recovery by structural features in images. To address the high costs associated with dataset collection for stereo camera-based perception of transparent objects, our method incorporates a parameter-aligned, domain-adaptive, and physically realistic Sim2Real simulation for efficient data generation, accelerated by AI algorithm. Our experimental results demonstrate the model's exceptional Sim2Real generalizability in real-world scenarios, enabling precise depth mapping of transparent objects to assist in robotic manipulation. Project details are available at https://sites.google.com/view/cleardepth/ .
Read more9/16/2024

0
Diffusion Models for Monocular Depth Estimation: Overcoming Challenging Conditions
Fabio Tosi, Pierluigi Zama Ramirez, Matteo Poggi
We present a novel approach designed to address the complexities posed by challenging, out-of-distribution data in the single-image depth estimation task. Starting with images that facilitate depth prediction due to the absence of unfavorable factors, we systematically generate new, user-defined scenes with a comprehensive set of challenges and associated depth information. This is achieved by leveraging cutting-edge text-to-image diffusion models with depth-aware control, known for synthesizing high-quality image content from textual prompts while preserving the coherence of 3D structure between generated and source imagery. Subsequent fine-tuning of any monocular depth network is carried out through a self-distillation protocol that takes into account images generated using our strategy and its own depth predictions on simple, unchallenging scenes. Experiments on benchmarks tailored for our purposes demonstrate the effectiveness and versatility of our proposal.
Read more7/24/2024

0
Digging into contrastive learning for robust depth estimation with diffusion models
Jiyuan Wang, Chunyu Lin, Lang Nie, Kang Liao, Shuwei Shao, Yao Zhao
Recently, diffusion-based depth estimation methods have drawn widespread attention due to their elegant denoising patterns and promising performance. However, they are typically unreliable under adverse conditions prevalent in real-world scenarios, such as rainy, snowy, etc. In this paper, we propose a novel robust depth estimation method called D4RD, featuring a custom contrastive learning mode tailored for diffusion models to mitigate performance degradation in complex environments. Concretely, we integrate the strength of knowledge distillation into contrastive learning, building the `trinity' contrastive scheme. This scheme utilizes the sampled noise of the forward diffusion process as a natural reference, guiding the predicted noise in diverse scenes toward a more stable and precise optimum. Moreover, we extend noise-level trinity to encompass more generic feature and image levels, establishing a multi-level contrast to distribute the burden of robust perception across the overall network. Before addressing complex scenarios, we enhance the stability of the baseline diffusion model with three straightforward yet effective improvements, which facilitate convergence and remove depth outliers. Extensive experiments demonstrate that D4RD surpasses existing state-of-the-art solutions on synthetic corruption datasets and real-world weather conditions. Source code and data are available at url{https://github.com/wangjiyuan9/D4RD}.
Read more9/24/2024