Digging into contrastive learning for robust depth estimation with diffusion models

0

Sign in to get full access
Overview
- This paper explores the use of contrastive learning techniques to improve the robustness of depth estimation models based on diffusion models.
- The researchers investigate how to leverage contrastive learning to make depth estimation models more resilient to various types of corruptions and perturbations.
- The paper presents a novel contrastive learning framework for depth estimation that incorporates diffusion models, with the goal of producing high-quality depth maps that are robust to real-world challenges.
Plain English Explanation
Depth estimation is the process of determining the distance between objects in an image and the camera. This information is crucial for many computer vision tasks, such as autonomous driving, 3D reconstruction, and image editing. However, current depth estimation models can struggle with real-world challenges, such as changes in lighting, weather conditions, or the presence of obstructions.
To address this, the researchers in this paper explore the use of contrastive learning, a technique that teaches models to distinguish between similar and dissimilar inputs. By incorporating contrastive learning into a diffusion-based depth estimation model, the researchers aim to make the model more robust and able to produce accurate depth maps even in the face of various distortions or corruptions.
Diffusion models are a type of generative model that work by gradually adding noise to an image and then learning to reverse the process to generate new images. The researchers hypothesize that by integrating contrastive learning into this diffusion-based framework, the depth estimation model will be better equipped to handle the challenges of the real world.
Technical Explanation
The paper presents a novel contrastive learning framework for depth estimation that leverages diffusion models. The key components of the proposed approach include:
-
Contrastive Learning Module: The researchers introduce a contrastive learning module that is integrated into the depth estimation model. This module learns to distinguish between clean depth maps and their corrupted counterparts, helping the model become more robust to various types of distortions.
-
Diffusion-based Depth Estimation: The depth estimation model is built upon a diffusion-based architecture, which allows the model to learn a generative process for producing depth maps. The diffusion process helps the model learn a more comprehensive representation of depth, which can then be leveraged for improved robustness.
-
Multi-scale Depth Estimation: The proposed framework performs depth estimation at multiple scales, combining information from different levels of detail to produce a high-quality, robust depth map.
The researchers conduct extensive experiments to evaluate the performance of their contrastive learning-based depth estimation approach. They assess the model's ability to produce accurate depth maps in the presence of various types of corruptions, such as noise, blur, and occlusions. The results demonstrate that the proposed method outperforms several state-of-the-art depth estimation models in terms of robustness and overall depth estimation quality.
Critical Analysis
The researchers acknowledge several limitations and areas for further exploration in their work:
- The paper focuses primarily on evaluating the model's robustness to synthetic corruptions, and it would be valuable to assess its performance on real-world, naturally occurring distortions as well.
- The proposed framework is computationally more expensive than some existing depth estimation approaches, which may limit its practical applicability in certain scenarios.
- The researchers suggest that incorporating additional self-supervised learning techniques, such as self-supervised task-adaptive fine-tuning, could further improve the model's robustness and generalization capabilities.
Overall, the paper presents a compelling approach to enhancing the robustness of depth estimation models through the integration of contrastive learning and diffusion-based techniques. However, further research is needed to fully understand the limitations and potential real-world implications of this work.
Conclusion
This paper introduces a novel contrastive learning framework for depth estimation that leverages diffusion models. By combining these two powerful techniques, the researchers have developed a depth estimation model that is more robust to various types of corruptions and perturbations, a crucial capability for many real-world computer vision applications.
The proposed approach demonstrates impressive performance improvements over existing depth estimation methods, highlighting the potential benefits of integrating contrastive learning into diffusion-based architectures. As the field of depth estimation continues to evolve, this work serves as an important step towards building more reliable and versatile depth estimation models that can operate effectively in the face of the challenges encountered in real-world environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Digging into contrastive learning for robust depth estimation with diffusion models
Jiyuan Wang, Chunyu Lin, Lang Nie, Kang Liao, Shuwei Shao, Yao Zhao
Recently, diffusion-based depth estimation methods have drawn widespread attention due to their elegant denoising patterns and promising performance. However, they are typically unreliable under adverse conditions prevalent in real-world scenarios, such as rainy, snowy, etc. In this paper, we propose a novel robust depth estimation method called D4RD, featuring a custom contrastive learning mode tailored for diffusion models to mitigate performance degradation in complex environments. Concretely, we integrate the strength of knowledge distillation into contrastive learning, building the `trinity' contrastive scheme. This scheme utilizes the sampled noise of the forward diffusion process as a natural reference, guiding the predicted noise in diverse scenes toward a more stable and precise optimum. Moreover, we extend noise-level trinity to encompass more generic feature and image levels, establishing a multi-level contrast to distribute the burden of robust perception across the overall network. Before addressing complex scenarios, we enhance the stability of the baseline diffusion model with three straightforward yet effective improvements, which facilitate convergence and remove depth outliers. Extensive experiments demonstrate that D4RD surpasses existing state-of-the-art solutions on synthetic corruption datasets and real-world weather conditions. Source code and data are available at url{https://github.com/wangjiyuan9/D4RD}.
Read more9/24/2024

0
Diffusion Models for Monocular Depth Estimation: Overcoming Challenging Conditions
Fabio Tosi, Pierluigi Zama Ramirez, Matteo Poggi
We present a novel approach designed to address the complexities posed by challenging, out-of-distribution data in the single-image depth estimation task. Starting with images that facilitate depth prediction due to the absence of unfavorable factors, we systematically generate new, user-defined scenes with a comprehensive set of challenges and associated depth information. This is achieved by leveraging cutting-edge text-to-image diffusion models with depth-aware control, known for synthesizing high-quality image content from textual prompts while preserving the coherence of 3D structure between generated and source imagery. Subsequent fine-tuning of any monocular depth network is carried out through a self-distillation protocol that takes into account images generated using our strategy and its own depth predictions on simple, unchallenging scenes. Experiments on benchmarks tailored for our purposes demonstrate the effectiveness and versatility of our proposal.
Read more7/24/2024

0
D3RoMa: Disparity Diffusion-based Depth Sensing for Material-Agnostic Robotic Manipulation
Songlin Wei, Haoran Geng, Jiayi Chen, Congyue Deng, Wenbo Cui, Chengyang Zhao, Xiaomeng Fang, Leonidas Guibas, He Wang
Depth sensing is an important problem for 3D vision-based robotics. Yet, a real-world active stereo or ToF depth camera often produces noisy and incomplete depth which bottlenecks robot performances. In this work, we propose D3RoMa, a learning-based depth estimation framework on stereo image pairs that predicts clean and accurate depth in diverse indoor scenes, even in the most challenging scenarios with translucent or specular surfaces where classical depth sensing completely fails. Key to our method is that we unify depth estimation and restoration into an image-to-image translation problem by predicting the disparity map with a denoising diffusion probabilistic model. At inference time, we further incorporated a left-right consistency constraint as classifier guidance to the diffusion process. Our framework combines recently advanced learning-based approaches and geometric constraints from traditional stereo vision. For model training, we create a large scene-level synthetic dataset with diverse transparent and specular objects to compensate for existing tabletop datasets. The trained model can be directly applied to real-world in-the-wild scenes and achieve state-of-the-art performance in multiple public depth estimation benchmarks. Further experiments in real environments show that accurate depth prediction significantly improves robotic manipulation in various scenarios.
Read more9/26/2024
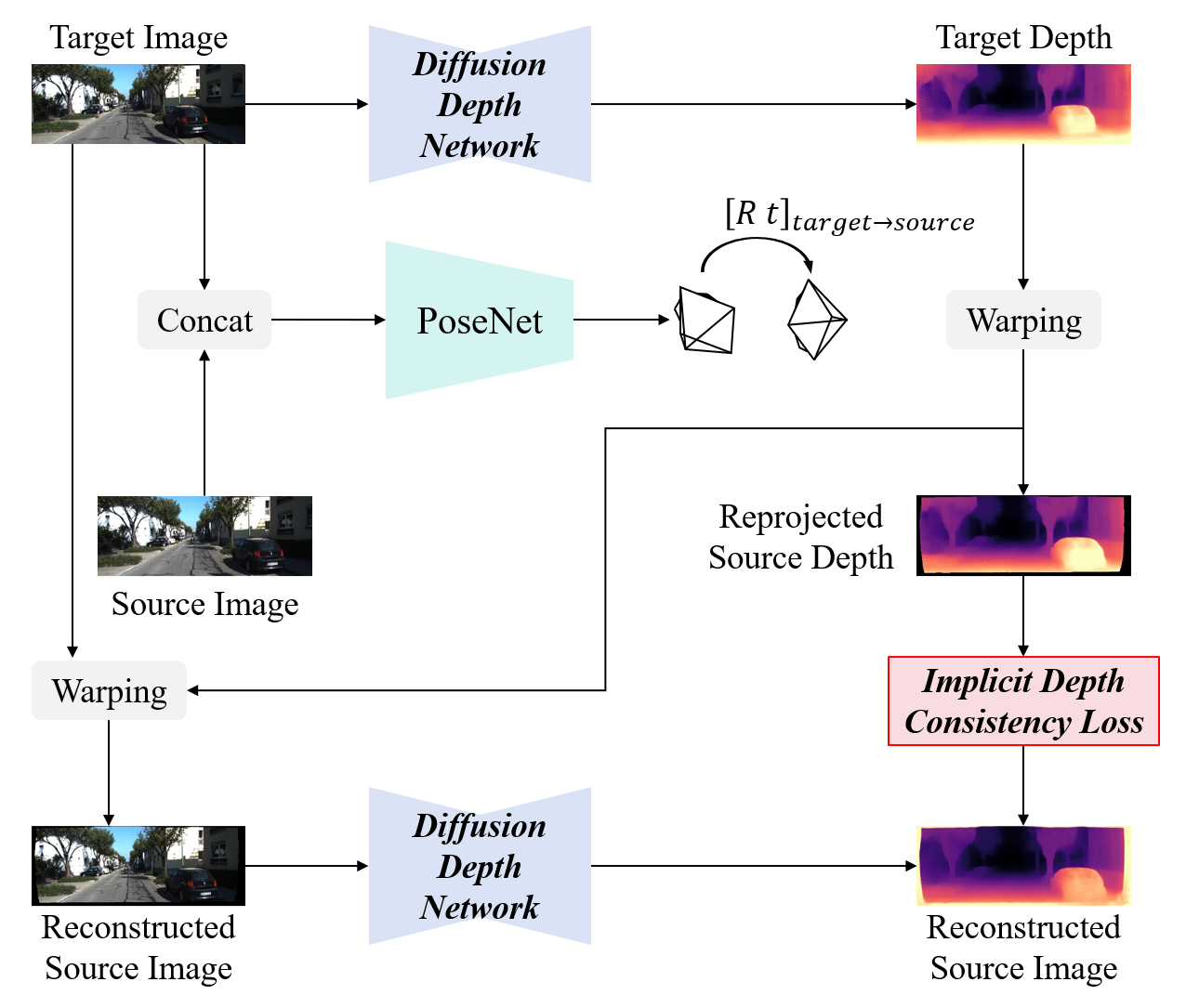
0
Unsupervised Monocular Depth Estimation Based on Hierarchical Feature-Guided Diffusion
Runze Liu, Dongchen Zhu, Guanghui Zhang, Yue Xu, Wenjun Shi, Xiaolin Zhang, Lei Wang, Jiamao Li
Unsupervised monocular depth estimation has received widespread attention because of its capability to train without ground truth. In real-world scenarios, the images may be blurry or noisy due to the influence of weather conditions and inherent limitations of the camera. Therefore, it is particularly important to develop a robust depth estimation model. Benefiting from the training strategies of generative networks, generative-based methods often exhibit enhanced robustness. In light of this, we employ a well-converging diffusion model among generative networks for unsupervised monocular depth estimation. Additionally, we propose a hierarchical feature-guided denoising module. This model significantly enriches the model's capacity for learning and interpreting depth distribution by fully leveraging image features to guide the denoising process. Furthermore, we explore the implicit depth within reprojection and design an implicit depth consistency loss. This loss function serves to enhance the performance of the model and ensure the scale consistency of depth within a video sequence. We conduct experiments on the KITTI, Make3D, and our self-collected SIMIT datasets. The results indicate that our approach stands out among generative-based models, while also showcasing remarkable robustness.
Read more6/17/2024