DAM: Dynamic Adapter Merging for Continual Video QA Learning

0

Sign in to get full access
Overview
- The paper introduces a novel approach called DaM (Dynamic Adapter Merging) for continual video question-answering (QA) learning.
- DaM aims to address the challenge of training AI models on new tasks while preserving performance on previously learned tasks, a common issue known as "catastrophic forgetting."
- The key idea behind DaM is to dynamically merge pre-trained adapters, which are small neural networks that can be efficiently fine-tuned for new tasks, rather than using a single large model.
Plain English Explanation
DaM: Dynamic Adapter Merging for Continual Video QA Learning is a new technique that helps AI models learn new video question-answering (QA) tasks without forgetting what they've already learned. This is a common problem, known as "catastrophic forgetting," where AI models trained on a new task tend to lose their ability to perform well on older tasks.
The key idea behind DaM is to use small, specialized neural networks called "adapters" that can be efficiently fine-tuned for new tasks, rather than relying on a single large model. As the AI model learns new tasks, DaM dynamically merges these adapters together, allowing the model to retain its knowledge from previous tasks while also incorporating the new information. This approach is more efficient and effective than traditional methods that tend to forget old information when learning new things.
Technical Explanation
DaM: Dynamic Adapter Merging for Continual Video QA Learning is a novel technique for continual learning in video question-answering (QA) tasks. The core idea is to use a collection of small, task-specific "adapter" modules that can be efficiently fine-tuned for new tasks, rather than relying on a single large model that struggles with catastrophic forgetting.
As the model learns new tasks, DaM dynamically merges the adapters by identifying and combining the most relevant components from the existing adapters. This allows the model to retain its knowledge from previous tasks while also incorporating the new information, resulting in improved performance on both old and new tasks.
The paper evaluates DaM on several video QA benchmarks, including DVIS-DAQ and TinyVQA, and demonstrates that it outperforms traditional continual learning methods in terms of both task performance and efficiency.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the DaM approach, including comparisons to several state-of-the-art continual learning methods. However, the authors acknowledge that DaM may be limited in its ability to handle highly divergent tasks, as the merging process may become more challenging in such scenarios.
Additionally, the paper does not explore the potential for negative transfer, where learning a new task could actually degrade performance on previously learned tasks. This is an important consideration for continual learning systems, and further research may be needed to understand the conditions under which DaM is most effective.
Overall, DaM: Dynamic Adapter Merging for Continual Video QA Learning presents a promising approach to continual learning, and the authors have made a valuable contribution to the field. However, as with any research, there are still opportunities for further exploration and refinement.
Conclusion
The DaM approach introduced in this paper offers a novel solution to the challenge of continual learning in video question-answering tasks. By dynamically merging task-specific adapter modules, DaM is able to retain knowledge from previous tasks while efficiently incorporating new information, resulting in improved performance across both old and new tasks.
The strong empirical results and thorough evaluation presented in the paper suggest that DaM could have significant implications for the development of more flexible and adaptable AI systems, particularly in domains where the ability to learn continuously is crucial. As the field of continual learning continues to advance, techniques like DaM will likely play an increasingly important role in enabling AI models to evolve and grow alongside the ever-changing world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DAM: Dynamic Adapter Merging for Continual Video QA Learning
Feng Cheng, Ziyang Wang, Yi-Lin Sung, Yan-Bo Lin, Mohit Bansal, Gedas Bertasius
We present a parameter-efficient method for continual video question-answering (VidQA) learning. Our method, named DAM, uses the proposed Dynamic Adapter Merging to (i) mitigate catastrophic forgetting, (ii) enable efficient adaptation to continually arriving datasets, (iii) handle inputs from unknown datasets during inference, and (iv) enable knowledge sharing across similar dataset domains. Given a set of continually streaming VidQA datasets, we sequentially train dataset-specific adapters for each dataset while freezing the parameters of a large pretrained video-language backbone. During inference, given a video-question sample from an unknown domain, our method first uses the proposed non-parametric router function to compute a probability for each adapter, reflecting how relevant that adapter is to the current video-question input instance. Subsequently, the proposed dynamic adapter merging scheme aggregates all the adapter weights into a new adapter instance tailored for that particular test sample to compute the final VidQA prediction, mitigating the impact of inaccurate router predictions and facilitating knowledge sharing across domains. Our DAM model outperforms prior state-of-the-art continual learning approaches by 9.1% while exhibiting 1.9% less forgetting on 6 VidQA datasets spanning various domains. We further extend DAM to continual image classification and image QA and outperform prior methods by a large margin. The code is publicly available at: https://github.com/klauscc/DAM
Read more4/24/2024

0
Boosting Continual Learning of Vision-Language Models via Mixture-of-Experts Adapters
Jiazuo Yu, Yunzhi Zhuge, Lu Zhang, Ping Hu, Dong Wang, Huchuan Lu, You He
Continual learning can empower vision-language models to continuously acquire new knowledge, without the need for access to the entire historical dataset. However, mitigating the performance degradation in large-scale models is non-trivial due to (i) parameter shifts throughout lifelong learning and (ii) significant computational burdens associated with full-model tuning. In this work, we present a parameter-efficient continual learning framework to alleviate long-term forgetting in incremental learning with vision-language models. Our approach involves the dynamic expansion of a pre-trained CLIP model, through the integration of Mixture-of-Experts (MoE) adapters in response to new tasks. To preserve the zero-shot recognition capability of vision-language models, we further introduce a Distribution Discriminative Auto-Selector (DDAS) that automatically routes in-distribution and out-of-distribution inputs to the MoE Adapter and the original CLIP, respectively. Through extensive experiments across various settings, our proposed method consistently outperforms previous state-of-the-art approaches while concurrently reducing parameter training burdens by 60%. Our code locates at https://github.com/JiazuoYu/MoE-Adapters4CL
Read more6/4/2024
0
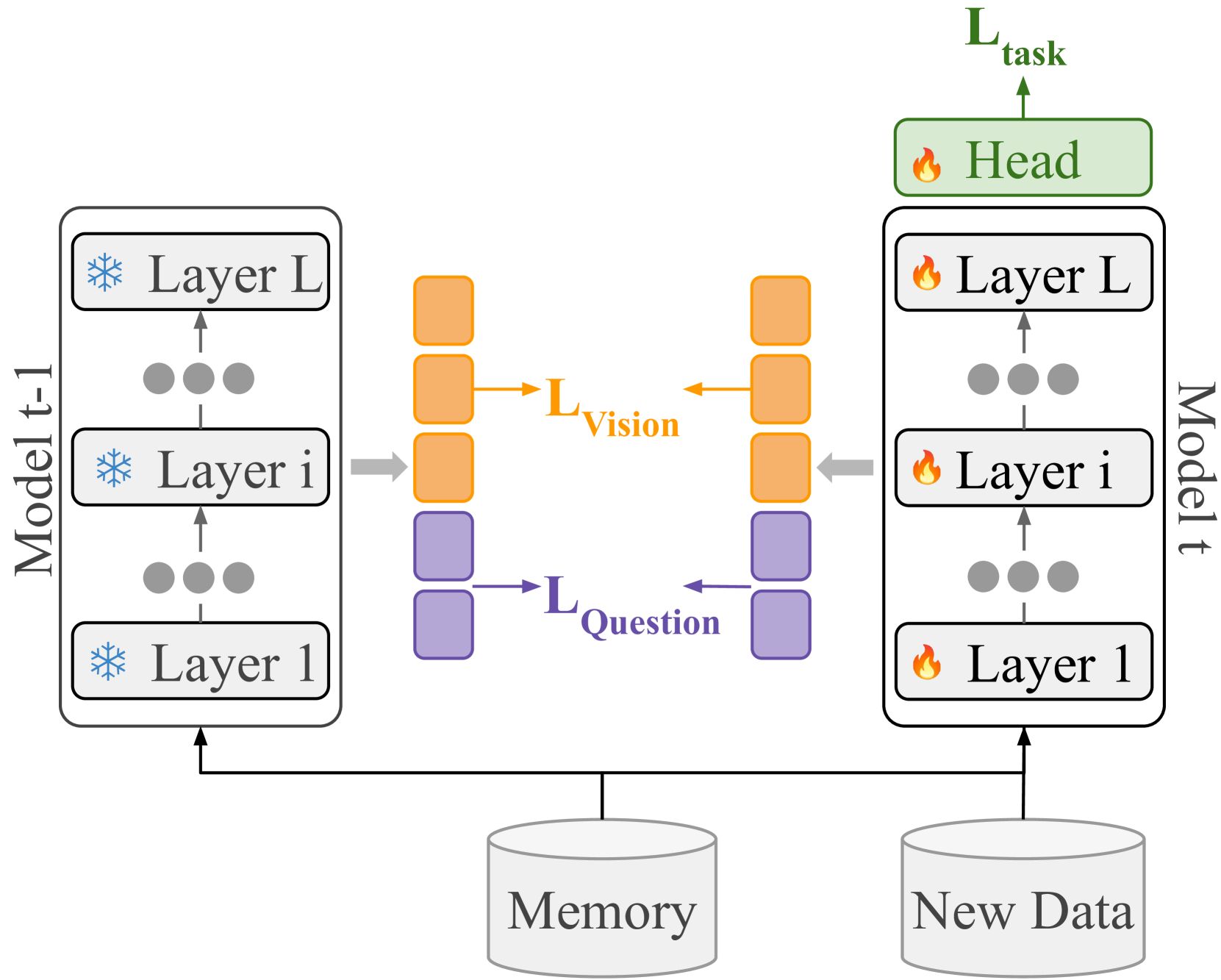
Enhancing Continual Learning in Visual Question Answering with Modality-Aware Feature Distillation
Malvina Nikandrou, Georgios Pantazopoulos, Ioannis Konstas, Alessandro Suglia
Continual learning focuses on incrementally training a model on a sequence of tasks with the aim of learning new tasks while minimizing performance drop on previous tasks. Existing approaches at the intersection of Continual Learning and Visual Question Answering (VQA) do not study how the multimodal nature of the input affects the learning dynamics of a model. In this paper, we demonstrate that each modality evolves at different rates across a continuum of tasks and that this behavior occurs in established encoder-only models as well as modern recipes for developing Vision & Language (VL) models. Motivated by this observation, we propose a modality-aware feature distillation (MAFED) approach which outperforms existing baselines across models of varying scale in three multimodal continual learning settings. Furthermore, we provide ablations showcasing that modality-aware distillation complements experience replay. Overall, our results emphasize the importance of addressing modality-specific dynamics to prevent forgetting in multimodal continual learning.
Read more6/28/2024
0
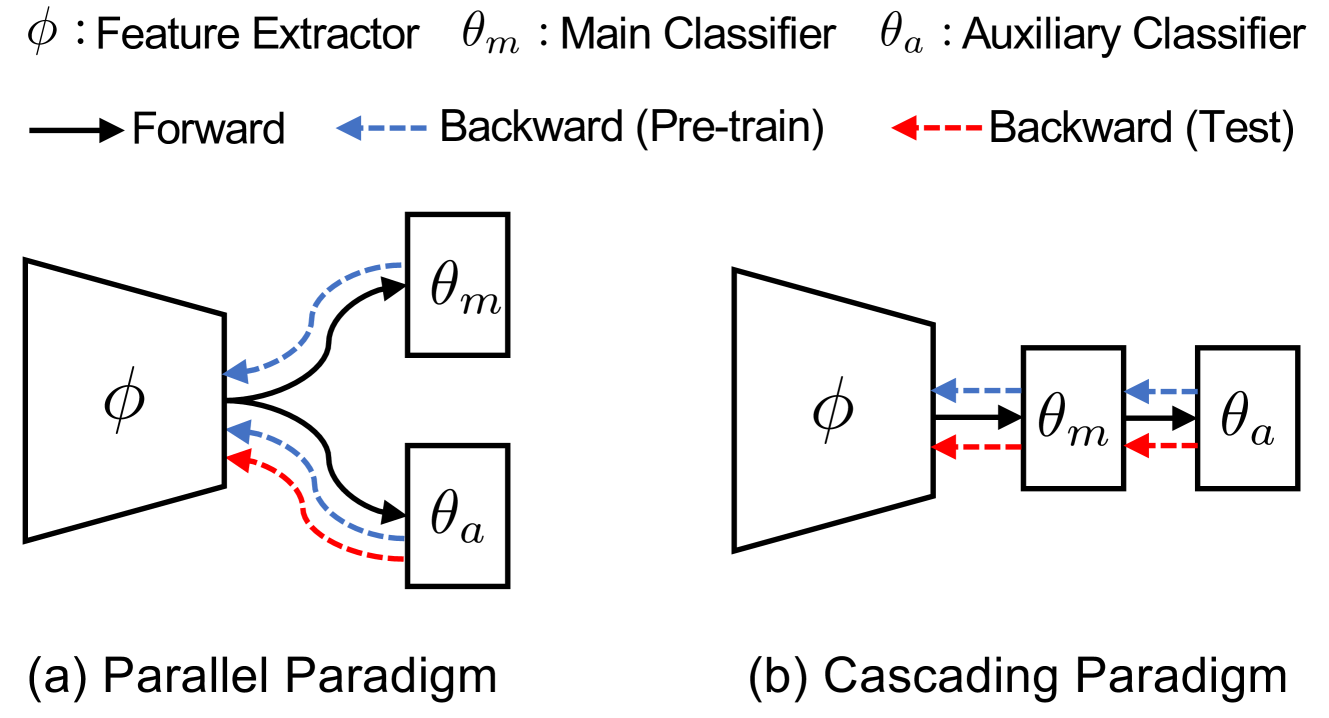
Adaptive Cascading Network for Continual Test-Time Adaptation
Kien X. Nguyen, Fengchun Qiao, Xi Peng
We study the problem of continual test-time adaption where the goal is to adapt a source pre-trained model to a sequence of unlabelled target domains at test time. Existing methods on test-time training suffer from several limitations: (1) Mismatch between the feature extractor and classifier; (2) Interference between the main and self-supervised tasks; (3) Lack of the ability to quickly adapt to the current distribution. In light of these challenges, we propose a cascading paradigm that simultaneously updates the feature extractor and classifier at test time, mitigating the mismatch between them and enabling long-term model adaptation. The pre-training of our model is structured within a meta-learning framework, thereby minimizing the interference between the main and self-supervised tasks and encouraging fast adaptation in the presence of limited unlabelled data. Additionally, we introduce innovative evaluation metrics, average accuracy and forward transfer, to effectively measure the model's adaptation capabilities in dynamic, real-world scenarios. Extensive experiments and ablation studies demonstrate the superiority of our approach in a range of tasks including image classification, text classification, and speech recognition.
Read more7/18/2024