Data, Data Everywhere: A Guide for Pretraining Dataset Construction

0
📊
Sign in to get full access
Overview
- This paper explores the construction of pretraining datasets for large language models, which are a key factor in their impressive capabilities.
- The authors conduct the first systematic study on the entire pipeline of pretraining set development, from evaluating existing techniques to categorizing and improving the quality of web-crawled data.
- The findings provide actionable steps for practitioners to develop high-quality pretraining sets, which can lead to better-performing language models.
Plain English Explanation
The incredible performance of recent AI language models can be largely attributed to the massive datasets they are trained on, often containing trillions of words. However, the methods used to create these pretraining datasets are not well documented, making it difficult for others to replicate this process.
To address this, the researchers in this paper conducted a comprehensive study on how to construct effective pretraining datasets. They started by testing different techniques for building these datasets and measured how much each method improved the model's accuracy on various tasks. This helped them identify the most impactful approaches.
Next, they examined the commonly used web-crawled data sources in more detail, looking at factors like toxicity, quality, and the type of language used. This allowed them to understand the characteristics of these datasets and how to refine them further.
Finally, the researchers showed how this information on dataset attributes can be used to improve the quality of the pretraining set, leading to better-performing language models. By providing this step-by-step guidance, the paper gives practitioners a clear roadmap for developing high-quality pretraining datasets that can unlock the full potential of large language models.
Technical Explanation
The paper first runs ablation studies on existing techniques for pretraining set development, such as TextGram and AboutMe, to identify which methods lead to the largest gains in model accuracy on downstream evaluations.
The authors then categorize the most widely used pretraining data source, web crawl snapshots, across key attributes: toxicity, quality, type of speech, and domain. This analysis reveals important insights about the characteristics of these datasets.
Finally, the paper demonstrates how this attribute information can be leveraged to further refine and improve the quality of a pretraining set. This includes techniques like filtering out toxic content and selecting data that aligns with the target domain.
Critical Analysis
The paper provides a comprehensive and systematic approach to pretraining dataset construction, which is a critical, yet often opaque, aspect of building large language models. The authors' focus on analyzing existing techniques and dataset characteristics is a valuable contribution, as it helps shed light on best practices in this area.
However, the paper does not delve into the potential biases or representational issues that may arise from the web-crawled data sources used for pretraining. There could be concerns around the demographic, cultural, or linguistic diversity of these datasets, which could lead to biased or limited model performance.
Additionally, the paper does not address the computational and resource requirements for implementing the proposed techniques at scale. Developing and curating high-quality pretraining sets can be an extremely resource-intensive process, and the feasibility of these methods for smaller organizations or research teams is unclear.
Conclusion
This paper takes an important step in demystifying the pretraining dataset construction process for large language models. By systematically evaluating existing techniques and dataset characteristics, the authors provide a roadmap for practitioners to develop higher-quality pretraining sets that can unlock the full potential of these models.
While the paper does not address all the potential issues around dataset bias and resource constraints, it lays the groundwork for further research and discussion in this critical area of AI development. By shedding light on this previously opaque process, the findings in this paper can help advance the field of large language models and their real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Data, Data Everywhere: A Guide for Pretraining Dataset Construction
Jupinder Parmar, Shrimai Prabhumoye, Joseph Jennings, Bo Liu, Aastha Jhunjhunwala, Zhilin Wang, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro
The impressive capabilities of recent language models can be largely attributed to the multi-trillion token pretraining datasets that they are trained on. However, model developers fail to disclose their construction methodology which has lead to a lack of open information on how to develop effective pretraining sets. To address this issue, we perform the first systematic study across the entire pipeline of pretraining set construction. First, we run ablations on existing techniques for pretraining set development to identify which methods translate to the largest gains in model accuracy on downstream evaluations. Then, we categorize the most widely used data source, web crawl snapshots, across the attributes of toxicity, quality, type of speech, and domain. Finally, we show how such attribute information can be used to further refine and improve the quality of a pretraining set. These findings constitute an actionable set of steps that practitioners can use to develop high quality pretraining sets.
Read more7/10/2024
📊
0
Deciphering the Impact of Pretraining Data on Large Language Models through Machine Unlearning
Yang Zhao, Li Du, Xiao Ding, Kai Xiong, Zhouhao Sun, Jun Shi, Ting Liu, Bing Qin
Through pretraining on a corpus with various sources, Large Language Models (LLMs) have gained impressive performance. However, the impact of each component of the pretraining corpus remains opaque. As a result, the organization of the pretraining corpus is still empirical and may deviate from the optimal. To address this issue, we systematically analyze the impact of 48 datasets from 5 major categories of pretraining data of LLMs and measure their impacts on LLMs using benchmarks about nine major categories of model capabilities. Our analyses provide empirical results about the contribution of multiple corpora on the performances of LLMs, along with their joint impact patterns, including complementary, orthogonal, and correlational relationships. We also identify a set of ``high-impact data'' such as Books that is significantly related to a set of model capabilities. These findings provide insights into the organization of data to support more efficient pretraining of LLMs.
Read more8/29/2024
💬
0
A Review of the Challenges with Massive Web-mined Corpora Used in Large Language Models Pre-Training
Micha{l} Pere{l}kiewicz, Rafa{l} Po'swiata
This article presents a comprehensive review of the challenges associated with using massive web-mined corpora for the pre-training of large language models (LLMs). This review identifies key challenges in this domain, including challenges such as noise (irrelevant or misleading information), duplication of content, the presence of low-quality or incorrect information, biases, and the inclusion of sensitive or personal information in web-mined corpora. Addressing these issues is crucial for the development of accurate, reliable, and ethically responsible language models. Through an examination of current methodologies for data cleaning, pre-processing, bias detection and mitigation, we highlight the gaps in existing approaches and suggest directions for future research. Our discussion aims to catalyze advancements in developing more sophisticated and ethically responsible LLMs.
Read more7/11/2024
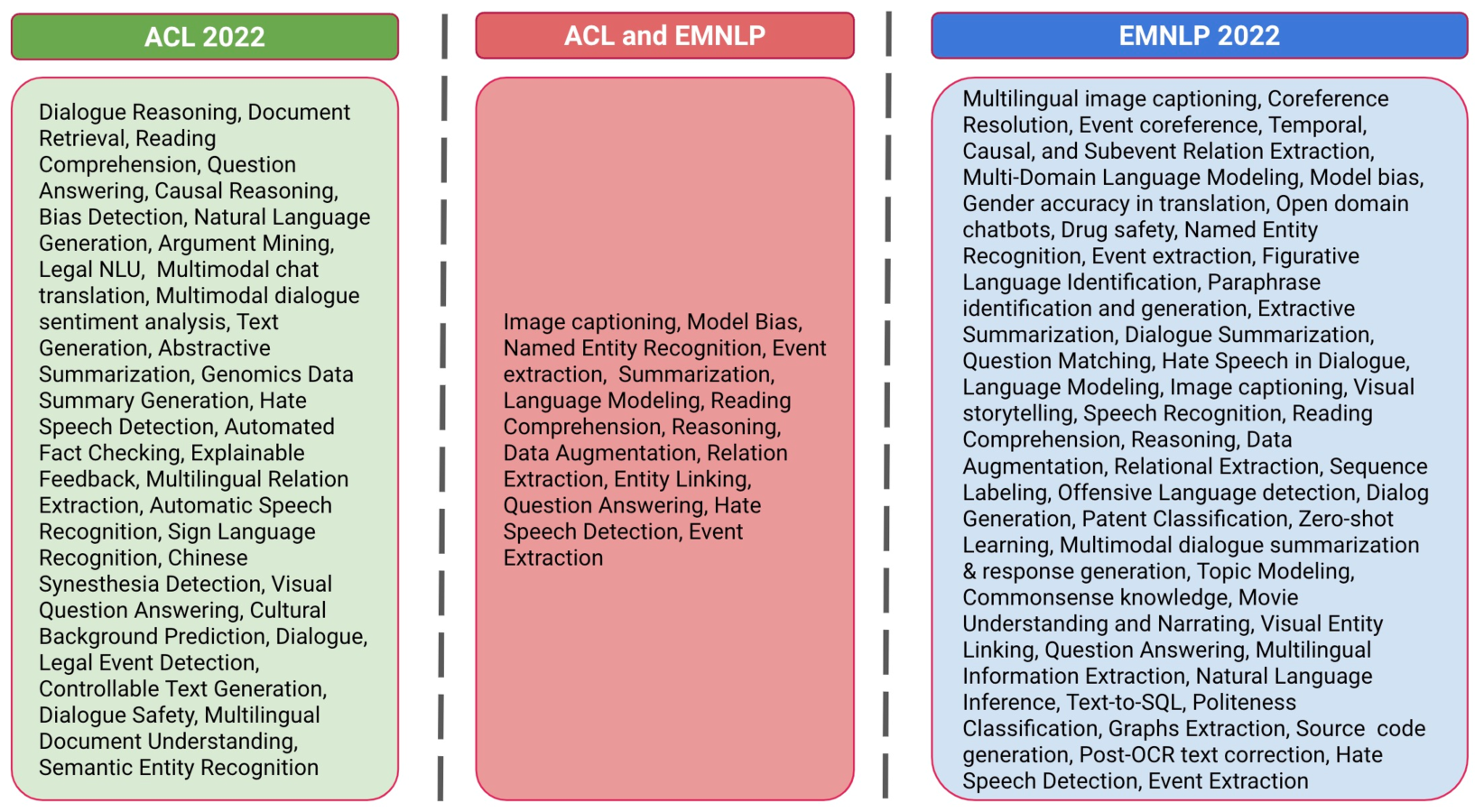
0
Revealing Trends in Datasets from the 2022 ACL and EMNLP Conferences
Jesse Atuhurra, Hidetaka Kamigaito
Natural language processing (NLP) has grown significantly since the advent of the Transformer architecture. Transformers have given birth to pre-trained large language models (PLMs). There has been tremendous improvement in the performance of NLP systems across several tasks. NLP systems are on par or, in some cases, better than humans at accomplishing specific tasks. However, it remains the norm that emph{better quality datasets at the time of pretraining enable PLMs to achieve better performance, regardless of the task.} The need to have quality datasets has prompted NLP researchers to continue creating new datasets to satisfy particular needs. For example, the two top NLP conferences, ACL and EMNLP, accepted ninety-two papers in 2022, introducing new datasets. This work aims to uncover the trends and insights mined within these datasets. Moreover, we provide valuable suggestions to researchers interested in curating datasets in the future.
Read more7/16/2024