Deep Multi-Objective Reinforcement Learning for Utility-Based Infrastructural Maintenance Optimization

0
Sign in to get full access
Overview
- This paper presents a deep multi-objective reinforcement learning (MORL) approach for optimizing utility-based infrastructural maintenance.
- The proposed method aims to balance multiple objectives, such as infrastructure performance, maintenance cost, and environmental impact, to find optimal maintenance policies.
- The research leverages recent advances in MORL techniques and risk-aware reinforcement learning to tackle this complex, real-world optimization problem.
Plain English Explanation
The paper focuses on improving how infrastructure, such as roads, bridges, and utilities, is maintained over time. Traditionally, maintenance decisions are made based on a single objective, like minimizing cost. However, this can lead to suboptimal outcomes, as it doesn't consider other important factors like the performance of the infrastructure or its environmental impact.
The researchers developed a new approach that uses deep reinforcement learning, a type of machine learning, to find maintenance policies that balance multiple objectives simultaneously. For example, the system might try to maximize infrastructure performance while also minimizing costs and environmental damage.
By framing this as a multi-objective reinforcement learning problem, the method can explore different trade-offs between the competing goals and identify the best overall maintenance strategy. This is similar to how a robot might learn to complete multiple tasks at once, rather than optimizing for just one.
The researchers tested their approach on simulated infrastructure maintenance scenarios and found that it outperformed traditional single-objective methods. This suggests the technique could be valuable for real-world infrastructure management, helping to make these systems more efficient, reliable, and environmentally sustainable.
Technical Explanation
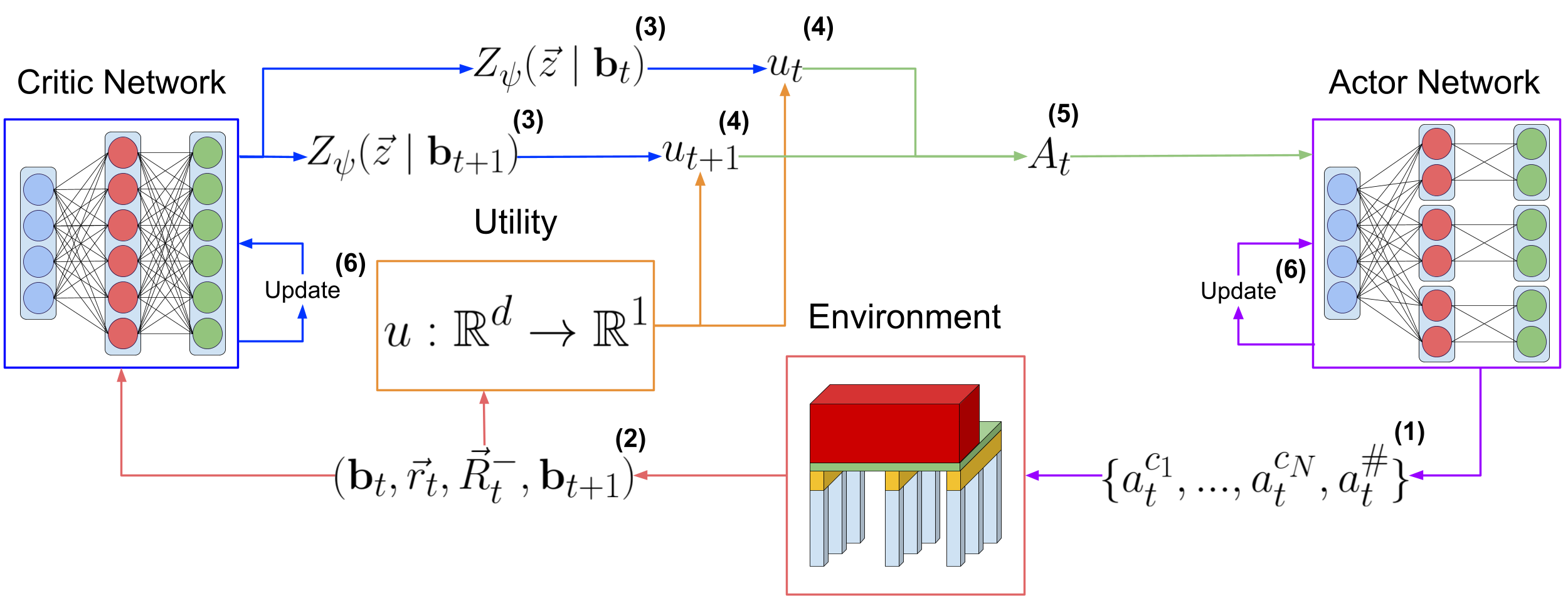
The paper proposes a deep multi-objective reinforcement learning (MORL) framework for optimizing utility-based infrastructural maintenance. The key components include:
-
Multi-Objective Markov Decision Process (MO-MDP): The authors model the infrastructure maintenance problem as an MO-MDP, where the agent aims to optimize multiple, potentially conflicting objectives (e.g., performance, cost, environmental impact).
-
Deep MORL Architecture: The authors develop a deep neural network-based MORL agent that learns to balance the trade-offs between the various objectives. This builds on recent advances in MORL techniques and risk-aware reinforcement learning.
-
Utility-Based Reward Shaping: The authors propose a utility-based reward function that captures the different objectives and guides the agent towards optimal maintenance policies.
-
Simulation-Based Evaluation: The authors evaluate the proposed approach on simulated infrastructure maintenance scenarios and compare its performance to traditional single-objective methods.
The key insight is that by framing infrastructure maintenance as a multi-objective reinforcement learning problem, the method can systematically explore the trade-offs between competing objectives and identify maintenance policies that achieve a balanced, optimal outcome. This contrasts with traditional approaches that often prioritize a single objective, leading to suboptimal solutions.
Critical Analysis
The paper presents a promising approach to addressing the complex challenge of utility-based infrastructural maintenance. The use of deep MORL techniques is well-justified and builds on recent advancements in the field.
One potential limitation is the reliance on simulation-based evaluation. While this allows for controlled experimentation, it is essential to validate the approach on real-world infrastructure data to ensure its practical applicability. Additionally, the paper does not address the computational complexity and scalability of the proposed method, which could be a concern for large-scale infrastructure networks.
Furthermore, the paper could benefit from a more in-depth discussion of the ethical implications of the proposed approach. For instance, how might the optimization of multiple objectives affect different stakeholders, such as infrastructure operators, users, and local communities? Additionally, the potential for unintended consequences, such as unfair resource allocation or environmental trade-offs, should be carefully considered.
Conclusion
This paper presents a novel deep multi-objective reinforcement learning approach for optimizing utility-based infrastructural maintenance. By balancing multiple objectives, such as performance, cost, and environmental impact, the proposed method offers a more comprehensive and sustainable approach to infrastructure management.
The simulation-based results are promising and suggest that the technique could lead to significant improvements in the efficiency, reliability, and environmental sustainability of infrastructure systems. Further research and real-world validation are needed to fully assess the practical applicability and broader implications of this work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Deep Multi-Objective Reinforcement Learning for Utility-Based Infrastructural Maintenance Optimization
Jesse van Remmerden, Maurice Kenter, Diederik M. Roijers, Charalampos Andriotis, Yingqian Zhang, Zaharah Bukhsh
In this paper, we introduce Multi-Objective Deep Centralized Multi-Agent Actor-Critic (MO- DCMAC), a multi-objective reinforcement learning (MORL) method for infrastructural maintenance optimization, an area traditionally dominated by single-objective reinforcement learning (RL) approaches. Previous single-objective RL methods combine multiple objectives, such as probability of collapse and cost, into a singular reward signal through reward-shaping. In contrast, MO-DCMAC can optimize a policy for multiple objectives directly, even when the utility function is non-linear. We evaluated MO-DCMAC using two utility functions, which use probability of collapse and cost as input. The first utility function is the Threshold utility, in which MO-DCMAC should minimize cost so that the probability of collapse is never above the threshold. The second is based on the Failure Mode, Effects, and Criticality Analysis (FMECA) methodology used by asset managers to asses maintenance plans. We evaluated MO-DCMAC, with both utility functions, in multiple maintenance environments, including ones based on a case study of the historical quay walls of Amsterdam. The performance of MO-DCMAC was compared against multiple rule-based policies based on heuristics currently used for constructing maintenance plans. Our results demonstrate that MO-DCMAC outperforms traditional rule-based policies across various environments and utility functions.
Read more6/11/2024

0
In Search for Architectures and Loss Functions in Multi-Objective Reinforcement Learning
Mikhail Terekhov, Caglar Gulcehre
Multi-objective reinforcement learning (MORL) is essential for addressing the intricacies of real-world RL problems, which often require trade-offs between multiple utility functions. However, MORL is challenging due to unstable learning dynamics with deep learning-based function approximators. The research path most taken has been to explore different value-based loss functions for MORL to overcome this issue. Our work empirically explores model-free policy learning loss functions and the impact of different architectural choices. We introduce two different approaches: Multi-objective Proximal Policy Optimization (MOPPO), which extends PPO to MORL, and Multi-objective Advantage Actor Critic (MOA2C), which acts as a simple baseline in our ablations. Our proposed approach is straightforward to implement, requiring only small modifications at the level of function approximator. We conduct comprehensive evaluations on the MORL Deep Sea Treasure, Minecart, and Reacher environments and show that MOPPO effectively captures the Pareto front. Our extensive ablation studies and empirical analyses reveal the impact of different architectural choices, underscoring the robustness and versatility of MOPPO compared to popular MORL approaches like Pareto Conditioned Networks (PCN) and Envelope Q-learning in terms of MORL metrics, including hypervolume and expected utility.
Read more7/25/2024
0
Finite-Time Convergence and Sample Complexity of Actor-Critic Multi-Objective Reinforcement Learning
Tianchen Zhou, FNU Hairi, Haibo Yang, Jia Liu, Tian Tong, Fan Yang, Michinari Momma, Yan Gao
Reinforcement learning with multiple, potentially conflicting objectives is pervasive in real-world applications, while this problem remains theoretically under-explored. This paper tackles the multi-objective reinforcement learning (MORL) problem and introduces an innovative actor-critic algorithm named MOAC which finds a policy by iteratively making trade-offs among conflicting reward signals. Notably, we provide the first analysis of finite-time Pareto-stationary convergence and corresponding sample complexity in both discounted and average reward settings. Our approach has two salient features: (a) MOAC mitigates the cumulative estimation bias resulting from finding an optimal common gradient descent direction out of stochastic samples. This enables provable convergence rate and sample complexity guarantees independent of the number of objectives; (b) With proper momentum coefficient, MOAC initializes the weights of individual policy gradients using samples from the environment, instead of manual initialization. This enhances the practicality and robustness of our algorithm. Finally, experiments conducted on a real-world dataset validate the effectiveness of our proposed method.
Read more5/10/2024

0
Multi-Objective Deep Reinforcement Learning for Optimisation in Autonomous Systems
Juan C. Rosero, Ivana Dusparic, Nicol'as Cardozo
Reinforcement Learning (RL) is used extensively in Autonomous Systems (AS) as it enables learning at runtime without the need for a model of the environment or predefined actions. However, most applications of RL in AS, such as those based on Q-learning, can only optimize one objective, making it necessary in multi-objective systems to combine multiple objectives in a single objective function with predefined weights. A number of Multi-Objective Reinforcement Learning (MORL) techniques exist but they have mostly been applied in RL benchmarks rather than real-world AS systems. In this work, we use a MORL technique called Deep W-Learning (DWN) and apply it to the Emergent Web Servers exemplar, a self-adaptive server, to find the optimal configuration for runtime performance optimization. We compare DWN to two single-objective optimization implementations: {epsilon}-greedy algorithm and Deep Q-Networks. Our initial evaluation shows that DWN optimizes multiple objectives simultaneously with similar results than DQN and {epsilon}-greedy approaches, having a better performance for some metrics, and avoids issues associated with combining multiple objectives into a single utility function.
Read more8/6/2024