Deep Neural Network Benchmarks for Selective Classification

0
🤿
Sign in to get full access
Overview
- As machine learning models are deployed in more socially sensitive tasks, there is a growing need for reliable and trustworthy predictions.
- One way to address this is by allowing models to abstain from making a prediction when there is a high risk of error.
- This requires adding a selection mechanism to the model to choose which examples to provide predictions for.
- The selective classification framework aims to balance the fraction of rejected predictions with the improvement in predictive performance on the selected predictions.
Plain English Explanation
The paper discusses the challenge of ensuring that machine learning models make reliable and trustworthy predictions, especially in sensitive applications. One way to address this is by allowing the model to choose not to make a prediction when it is uncertain and there is a high risk of making an error. This is done by adding a "selection mechanism" to the model that decides which examples the model will provide predictions for.
The goal of this "selective classification framework" is to find the right balance between the number of predictions the model rejects and the improvement in the accuracy of the predictions the model does make. Most existing approaches to selective classification rely on complex deep neural network architectures, but their performance has only been partially evaluated across different datasets and tasks.
This paper aims to fill that gap by comprehensively benchmarking 18 different selective classification methods on a diverse set of 44 datasets, including both image and tabular data, with binary and multiclass classification tasks. The results show that there is no clear "winner" among the methods, and the best approach depends on the specific goals and priorities of the user.
Technical Explanation
The paper evaluates 18 different selective classification frameworks, which are designed to allow machine learning models to abstain from making predictions when the risk of error is high. These frameworks all include a "selection mechanism" that decides which examples the model will provide predictions for.
The experimental setup involved testing these 18 baselines on a diverse set of 44 datasets, covering both image and tabular data, as well as binary and multiclass classification tasks. The researchers evaluated the approaches based on several criteria, including:
- Selective error rate: The error rate among the examples the model chooses to make predictions for.
- Empirical coverage: The fraction of examples the model provides predictions for.
- Distribution of rejected instances' classes: How the model's rejections are distributed across the different classes.
- Performance on out-of-distribution instances: How well the model performs on examples that are different from the training data.
The results show that there is no single "best" selective classification method across all the evaluated criteria and datasets. The optimal approach depends on the specific objectives and priorities of the user, such as whether they care more about maximizing predictive performance or minimizing the fraction of rejected predictions.
Critical Analysis
The paper provides a comprehensive empirical evaluation of selective classification approaches, which is a valuable contribution to the field. By testing a wide range of methods on a diverse set of datasets, the researchers offer practitioners a more holistic understanding of the relative merits and trade-offs of these techniques.
However, the paper does not delve into the potential limitations or drawbacks of the selective classification framework itself. For example, the paper does not address potential biases that could arise from the model selectively making predictions for certain types of examples and rejecting others. Additionally, the paper does not explore how these methods might perform in the face of distribution shifts or other real-world challenges.
Further research could investigate the ethical implications of selective classification, such as how it might impact fairness and accountability when deployed in high-stakes applications. It would also be valuable to explore hybrid approaches that combine selective classification with other model robustness techniques.
Conclusion
This paper provides a comprehensive benchmark of 18 selective classification frameworks, which allow machine learning models to abstain from making predictions when the risk of error is high. The results show that there is no single "best" method, and the optimal approach depends on the specific goals and priorities of the user.
While the paper offers valuable insights for practitioners, it also highlights the need for further research into the limitations and potential risks of selective classification. As these techniques become more widely adopted, it will be crucial to carefully consider their ethical implications and explore ways to make them more robust and accountable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Deep Neural Network Benchmarks for Selective Classification
Andrea Pugnana, Lorenzo Perini, Jesse Davis, Salvatore Ruggieri
With the increasing deployment of machine learning models in many socially sensitive tasks, there is a growing demand for reliable and trustworthy predictions. One way to accomplish these requirements is to allow a model to abstain from making a prediction when there is a high risk of making an error. This requires adding a selection mechanism to the model, which selects those examples for which the model will provide a prediction. The selective classification framework aims to design a mechanism that balances the fraction of rejected predictions (i.e., the proportion of examples for which the model does not make a prediction) versus the improvement in predictive performance on the selected predictions. Multiple selective classification frameworks exist, most of which rely on deep neural network architectures. However, the empirical evaluation of the existing approaches is still limited to partial comparisons among methods and settings, providing practitioners with little insight into their relative merits. We fill this gap by benchmarking 18 baselines on a diverse set of 44 datasets that includes both image and tabular data. Moreover, there is a mix of binary and multiclass tasks. We evaluate these approaches using several criteria, including selective error rate, empirical coverage, distribution of rejected instance's classes, and performance on out-of-distribution instances. The results indicate that there is not a single clear winner among the surveyed baselines, and the best method depends on the users' objectives.
Read more9/19/2024
🏷️
0
Calibrated Selective Classification
Adam Fisch, Tommi Jaakkola, Regina Barzilay
Selective classification allows models to abstain from making predictions (e.g., say I don't know) when in doubt in order to obtain better effective accuracy. While typical selective models can be effective at producing more accurate predictions on average, they may still allow for wrong predictions that have high confidence, or skip correct predictions that have low confidence. Providing calibrated uncertainty estimates alongside predictions -- probabilities that correspond to true frequencies -- can be as important as having predictions that are simply accurate on average. However, uncertainty estimates can be unreliable for certain inputs. In this paper, we develop a new approach to selective classification in which we propose a method for rejecting examples with uncertain uncertainties. By doing so, we aim to make predictions with {well-calibrated} uncertainty estimates over the distribution of accepted examples, a property we call selective calibration. We present a framework for learning selectively calibrated models, where a separate selector network is trained to improve the selective calibration error of a given base model. In particular, our work focuses on achieving robust calibration, where the model is intentionally designed to be tested on out-of-domain data. We achieve this through a training strategy inspired by distributionally robust optimization, in which we apply simulated input perturbations to the known, in-domain training data. We demonstrate the empirical effectiveness of our approach on multiple image classification and lung cancer risk assessment tasks.
Read more6/24/2024

0
Hierarchical Selective Classification
Shani Goren, Ido Galil, Ran El-Yaniv
Deploying deep neural networks for risk-sensitive tasks necessitates an uncertainty estimation mechanism. This paper introduces hierarchical selective classification, extending selective classification to a hierarchical setting. Our approach leverages the inherent structure of class relationships, enabling models to reduce the specificity of their predictions when faced with uncertainty. In this paper, we first formalize hierarchical risk and coverage, and introduce hierarchical risk-coverage curves. Next, we develop algorithms for hierarchical selective classification (which we refer to as inference rules), and propose an efficient algorithm that guarantees a target accuracy constraint with high probability. Lastly, we conduct extensive empirical studies on over a thousand ImageNet classifiers, revealing that training regimes such as CLIP, pretraining on ImageNet21k and knowledge distillation boost hierarchical selective performance.
Read more5/21/2024
0
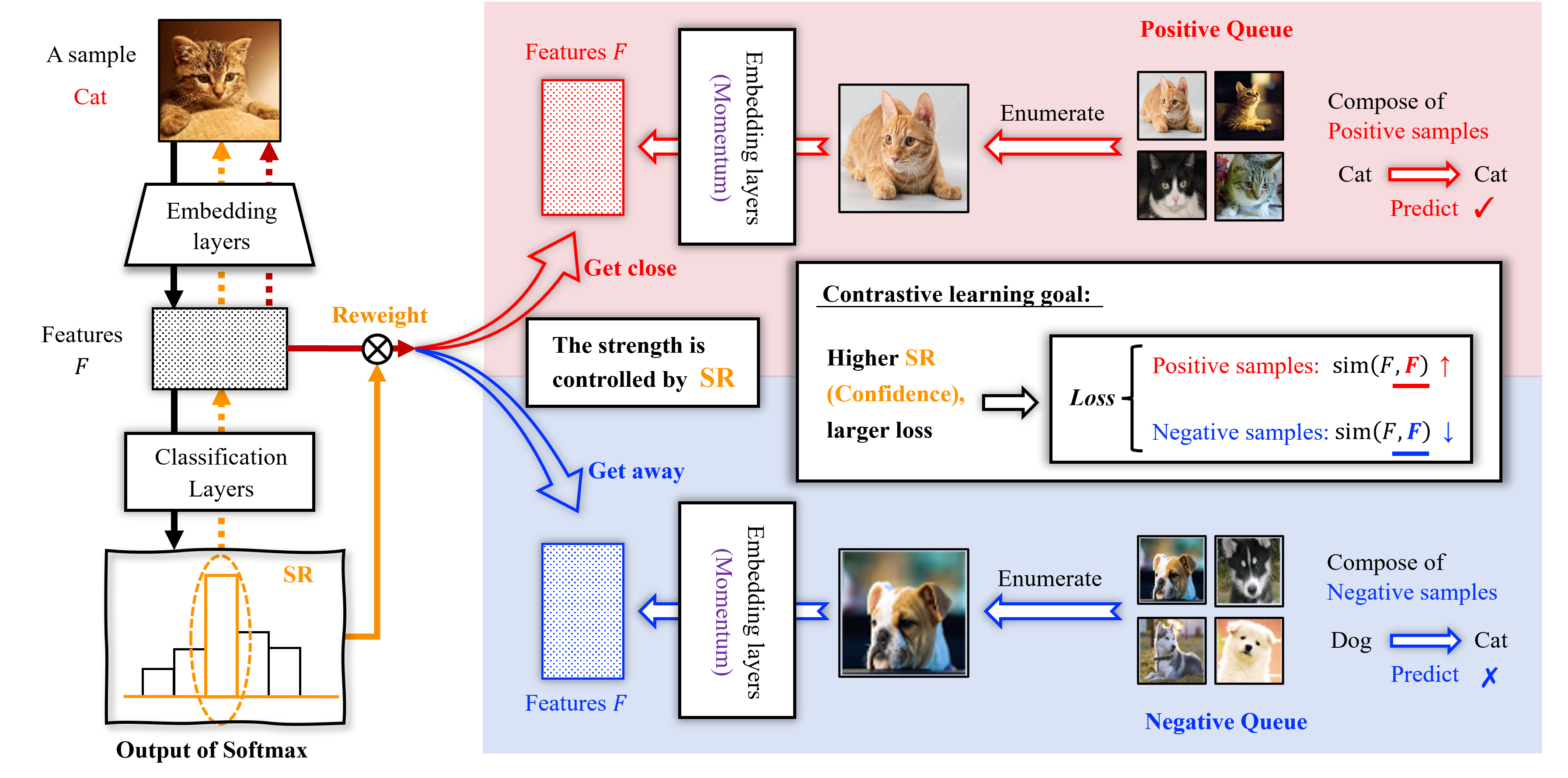
Confidence-aware Contrastive Learning for Selective Classification
Yu-Chang Wu, Shen-Huan Lyu, Haopu Shang, Xiangyu Wang, Chao Qian
Selective classification enables models to make predictions only when they are sufficiently confident, aiming to enhance safety and reliability, which is important in high-stakes scenarios. Previous methods mainly use deep neural networks and focus on modifying the architecture of classification layers to enable the model to estimate the confidence of its prediction. This work provides a generalization bound for selective classification, disclosing that optimizing feature layers helps improve the performance of selective classification. Inspired by this theory, we propose to explicitly improve the selective classification model at the feature level for the first time, leading to a novel Confidence-aware Contrastive Learning method for Selective Classification, CCL-SC, which similarizes the features of homogeneous instances and differentiates the features of heterogeneous instances, with the strength controlled by the model's confidence. The experimental results on typical datasets, i.e., CIFAR-10, CIFAR-100, CelebA, and ImageNet, show that CCL-SC achieves significantly lower selective risk than state-of-the-art methods, across almost all coverage degrees. Moreover, it can be combined with existing methods to bring further improvement.
Read more6/10/2024