Defending Large Language Models Against Attacks With Residual Stream Activation Analysis

0
💬
Sign in to get full access
Overview
- This paper explores techniques to defend large language models against adversarial attacks.
- The researchers propose a method called Residual Stream Activation Analysis (RSAA) that aims to detect and mitigate such attacks.
- The paper includes experimental results demonstrating the effectiveness of RSAA in improving the robustness of large language models.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text, answer questions, and perform a variety of language-related tasks. However, these models can be vulnerable to adversarial attacks, where small, carefully crafted perturbations to the input can cause the model to produce incorrect or nonsensical outputs.
The researchers in this paper propose a technique called Residual Stream Activation Analysis (RSAA) to help defend LLMs against such attacks. The key idea behind RSAA is to analyze the "residual streams" within the LLM, which are the intermediate activations that are added to the main activation stream. By monitoring these residual streams, the researchers found that they can detect when an input has been maliciously altered, and take steps to mitigate the attack.
In their experiments, the researchers tested RSAA on several LLMs and showed that it can significantly improve the models' robustness to a variety of adversarial attacks, including adversarial machine learning attacks and generative AI attacks. This is an important step forward in advancing the adversarial robustness of large language models.
Technical Explanation
The researchers begin by noting the growing importance of large language models (LLMs) and the need to address their vulnerability to adversarial attacks. They then introduce their proposed technique, Residual Stream Activation Analysis (RSAA), which aims to detect and mitigate such attacks.
RSAA works by analyzing the residual streams within the LLM architecture. Residual streams are the intermediate activations that are added to the main activation stream, and the researchers hypothesized that these streams would be affected in distinctive ways by adversarial perturbations. By monitoring the behavior of the residual streams, RSAA can identify when an input has been maliciously altered and take appropriate action to defend the model.
The paper includes experiments on several popular LLMs, including GPT-2 and BERT. The researchers demonstrate that RSAA can significantly improve the models' robustness to a wide range of adversarial attacks, including both gradient-based and black-box attacks. They also provide insights into the mechanisms by which RSAA achieves these improvements, highlighting the importance of the residual stream dynamics.
Critical Analysis
The researchers have presented a novel and promising approach to defending large language models against adversarial attacks. The RSAA technique appears to be effective in their experiments, and the underlying principles of monitoring residual stream activation patterns seem well-justified.
However, the paper does not address several important considerations. First, the authors do not provide a thorough analysis of the computational overhead and runtime performance implications of RSAA, which could be a crucial factor in real-world deployment. Additionally, the researchers only tested RSAA on a limited set of LLMs and attack types, and it is unclear how the method would generalize to a broader range of models and attack scenarios.
Furthermore, the paper does not discuss potential limitations or edge cases where RSAA may struggle, such as adversarial attacks that are specifically designed to circumvent the residual stream analysis. Exploring these potential weaknesses and ways to further improve the technique would strengthen the overall contribution.
Despite these caveats, the work presented in this paper represents a significant step forward in the quest to enhance the adversarial robustness of large language models. The RSAA approach is a novel and promising direction that warrants further investigation and refinement.
Conclusion
This paper introduces Residual Stream Activation Analysis (RSAA), a technique for defending large language models against adversarial attacks. The key idea is to monitor the residual streams within the LLM architecture, which can provide distinctive signals about the presence of adversarial perturbations.
The researchers demonstrate the effectiveness of RSAA through experiments on several popular LLMs, showing significant improvements in robustness to a variety of attack types. While the paper does not address all potential concerns, it represents an important contribution to the ongoing effort to secure large language models against malicious inputs.
As large language models continue to grow in importance and capabilities, developing robust defenses against adversarial attacks will be crucial. The RSAA approach presented in this paper is a promising step in that direction, and further research and refinement of this technique could have far-reaching implications for the field of adversarial machine learning and the broader landscape of AI safety and security.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Defending Large Language Models Against Attacks With Residual Stream Activation Analysis
Amelia Kawasaki, Andrew Davis, Houssam Abbas
The widespread adoption of Large Language Models (LLMs), exemplified by OpenAI's ChatGPT, brings to the forefront the imperative to defend against adversarial threats on these models. These attacks, which manipulate an LLM's output by introducing malicious inputs, undermine the model's integrity and the trust users place in its outputs. In response to this challenge, our paper presents an innovative defensive strategy, given white box access to an LLM, that harnesses residual activation analysis between transformer layers of the LLM. We apply a novel methodology for analyzing distinctive activation patterns in the residual streams for attack prompt classification. We curate multiple datasets to demonstrate how this method of classification has high accuracy across multiple types of attack scenarios, including our newly-created attack dataset. Furthermore, we enhance the model's resilience by integrating safety fine-tuning techniques for LLMs in order to measure its effect on our capability to detect attacks. The results underscore the effectiveness of our approach in enhancing the detection and mitigation of adversarial inputs, advancing the security framework within which LLMs operate.
Read more7/10/2024
💬
0
Exploring the Adversarial Capabilities of Large Language Models
Lukas Struppek, Minh Hieu Le, Dominik Hintersdorf, Kristian Kersting
The proliferation of large language models (LLMs) has sparked widespread and general interest due to their strong language generation capabilities, offering great potential for both industry and research. While previous research delved into the security and privacy issues of LLMs, the extent to which these models can exhibit adversarial behavior remains largely unexplored. Addressing this gap, we investigate whether common publicly available LLMs have inherent capabilities to perturb text samples to fool safety measures, so-called adversarial examples resp.~attacks. More specifically, we investigate whether LLMs are inherently able to craft adversarial examples out of benign samples to fool existing safe rails. Our experiments, which focus on hate speech detection, reveal that LLMs succeed in finding adversarial perturbations, effectively undermining hate speech detection systems. Our findings carry significant implications for (semi-)autonomous systems relying on LLMs, highlighting potential challenges in their interaction with existing systems and safety measures.
Read more7/9/2024
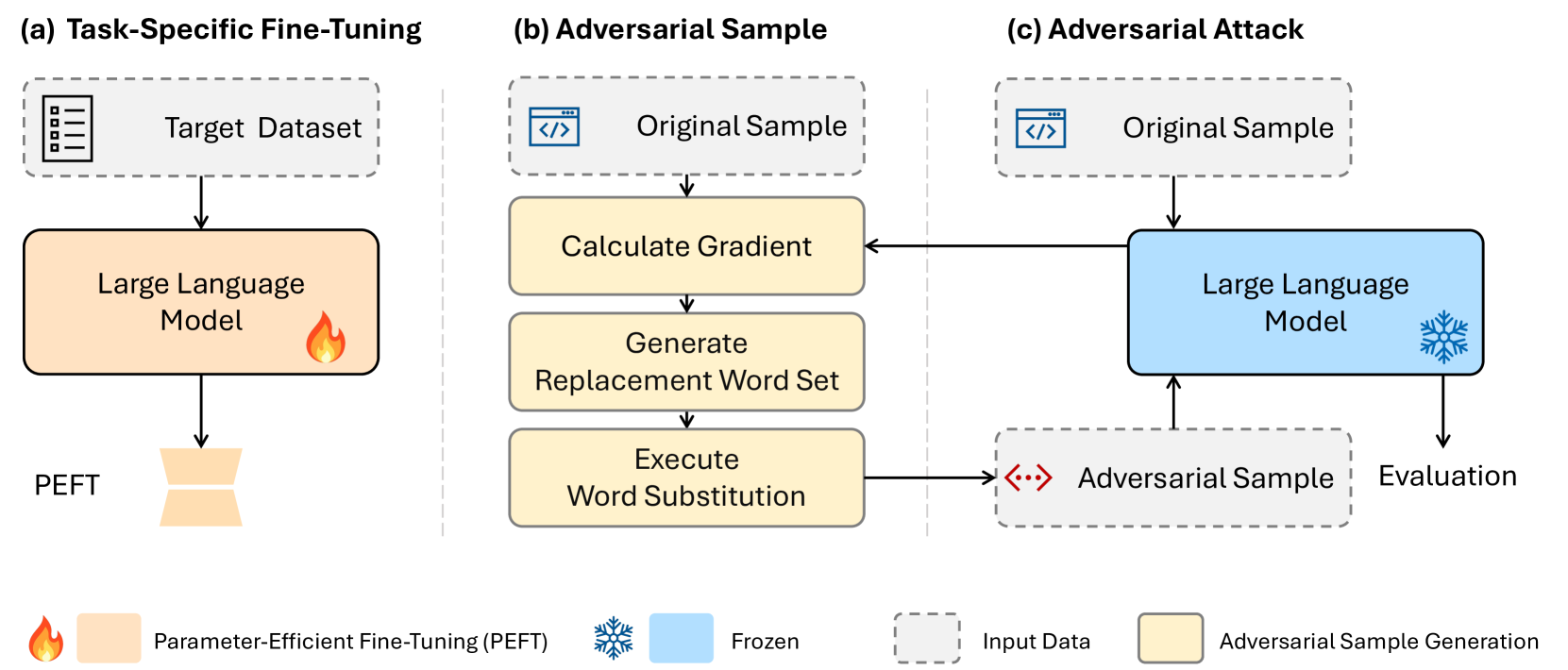
0
Assessing Adversarial Robustness of Large Language Models: An Empirical Study
Zeyu Yang, Zhao Meng, Xiaochen Zheng, Roger Wattenhofer
Large Language Models (LLMs) have revolutionized natural language processing, but their robustness against adversarial attacks remains a critical concern. We presents a novel white-box style attack approach that exposes vulnerabilities in leading open-source LLMs, including Llama, OPT, and T5. We assess the impact of model size, structure, and fine-tuning strategies on their resistance to adversarial perturbations. Our comprehensive evaluation across five diverse text classification tasks establishes a new benchmark for LLM robustness. The findings of this study have far-reaching implications for the reliable deployment of LLMs in real-world applications and contribute to the advancement of trustworthy AI systems.
Read more9/16/2024
💬
0
Recent Advances in Attack and Defense Approaches of Large Language Models
Jing Cui, Yishi Xu, Zhewei Huang, Shuchang Zhou, Jianbin Jiao, Junge Zhang
Large Language Models (LLMs) have revolutionized artificial intelligence and machine learning through their advanced text processing and generating capabilities. However, their widespread deployment has raised significant safety and reliability concerns. Established vulnerabilities in deep neural networks, coupled with emerging threat models, may compromise security evaluations and create a false sense of security. Given the extensive research in the field of LLM security, we believe that summarizing the current state of affairs will help the research community better understand the present landscape and inform future developments. This paper reviews current research on LLM vulnerabilities and threats, and evaluates the effectiveness of contemporary defense mechanisms. We analyze recent studies on attack vectors and model weaknesses, providing insights into attack mechanisms and the evolving threat landscape. We also examine current defense strategies, highlighting their strengths and limitations. By contrasting advancements in attack and defense methodologies, we identify research gaps and propose future directions to enhance LLM security. Our goal is to advance the understanding of LLM safety challenges and guide the development of more robust security measures.
Read more9/9/2024