Defending Our Privacy With Backdoors

0
📊
Sign in to get full access
Overview
- The paper discusses the privacy concerns raised by the widespread use of large AI models trained on uncurated, often sensitive web-scraped data.
- One key concern is that adversaries can extract sensitive information about the training data using privacy attacks.
- The task of removing specific information from the models without sacrificing performance is challenging.
- The paper proposes a defense based on backdoor attacks to remove private information, such as names and faces, from vision-language models.
Plain English Explanation
The paper focuses on a privacy problem that has emerged as a result of the growing use of large AI models trained on data from the internet. These models can be trained on a vast amount of web-scraped data, which often contains sensitive information about individuals, such as their names and faces.
The researchers explain that adversaries, or attackers, may be able to use specialized techniques to extract this sensitive information from the models, even if it's not directly visible. This raises significant privacy concerns, as individuals' personal data could be exposed.
To address this issue, the researchers propose a novel defense mechanism based on backdoor attacks. Backdoor attacks are a type of security vulnerability where an attacker can trigger a specific behavior in a model by using a hidden "backdoor" trigger.
In this case, the researchers use backdoor attacks to align the embeddings (numerical representations) of sensitive phrases, like individuals' names, with more neutral terms. This effectively "hides" the sensitive information from the model, making it less vulnerable to privacy attacks.
For images, the researchers map the embeddings of individuals' faces to a universal, anonymous embedding, again obscuring the sensitive information.
The researchers claim that this approach provides a promising way to enhance the privacy of individuals within large AI models trained on uncurated web data, without significantly affecting the model's performance.
Technical Explanation
The paper proposes a defense against privacy attacks on vision-language models trained on uncurated, web-scraped data. The key idea is to use backdoor attacks to align the embeddings of sensitive phrases and individual faces to more neutral representations, effectively "hiding" the sensitive information from the model.
For the text encoder, the researchers insert backdoors that map the embeddings of sensitive phrases (e.g., individuals' names) to those of more neutral terms. This ensures that the model treats the sensitive information the same as the neutral terms, obscuring the private data.
For the image encoder, the researchers map the embeddings of individuals' faces to a universal, anonymous embedding. This anonymizes the individuals' identities within the model.
The researchers evaluate their approach on the CLIP model, a popular vision-language model, and demonstrate its effectiveness using a specialized privacy attack for zero-shot classifiers. Their results show that the backdoor-based defense can remove private information from the model without significantly impacting its overall performance.
Critical Analysis
The paper presents a novel and potentially useful approach to enhancing the privacy of individuals within large AI models trained on uncurated web data. By leveraging backdoor attacks, the researchers have found a way to "hide" sensitive information, such as names and faces, from the models without having to retrain them from scratch.
One potential limitation of the approach is that it relies on the effective insertion of backdoors into the model, which may not always be straightforward or reliable. Additionally, the researchers do not address the potential risks or unintended consequences of introducing backdoors, even for a benign purpose.
Another concern is that the proposed defense may not be robust to more sophisticated privacy attacks that can potentially bypass the backdoor-based obfuscation. The researchers acknowledge this limitation and suggest the need for further research in this area.
It's also worth noting that the paper focuses solely on vision-language models and does not explore the applicability of the backdoor-based defense to other types of AI models, such as language models or tabular data models. Expanding the scope of the research could provide a more comprehensive understanding of the approach's broader utility.
Conclusion
The paper presents a novel defense mechanism based on backdoor attacks to remove private information, such as names and faces, from vision-language models trained on uncurated web-scraped data. This approach provides a promising avenue to enhance the privacy of individuals within large AI models without significantly sacrificing model performance.
While the researchers demonstrate the effectiveness of their approach on the CLIP model, further research is needed to explore the robustness of the backdoor-based defense against more advanced privacy attacks and its applicability to a wider range of AI models. Nonetheless, the paper offers a unique perspective on the use of backdoor attacks and highlights the importance of addressing privacy concerns in the era of large, web-based AI models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Defending Our Privacy With Backdoors
Dominik Hintersdorf, Lukas Struppek, Daniel Neider, Kristian Kersting
The proliferation of large AI models trained on uncurated, often sensitive web-scraped data has raised significant privacy concerns. One of the concerns is that adversaries can extract information about the training data using privacy attacks. Unfortunately, the task of removing specific information from the models without sacrificing performance is not straightforward and has proven to be challenging. We propose a rather easy yet effective defense based on backdoor attacks to remove private information, such as names and faces of individuals, from vision-language models by fine-tuning them for only a few minutes instead of re-training them from scratch. Specifically, by strategically inserting backdoors into text encoders, we align the embeddings of sensitive phrases with those of neutral terms-a person instead of the person's actual name. For image encoders, we map individuals' embeddings to be removed from the model to a universal, anonymous embedding. The results of our extensive experimental evaluation demonstrate the effectiveness of our backdoor-based defense on CLIP by assessing its performance using a specialized privacy attack for zero-shot classifiers. Our approach provides a new dual-use perspective on backdoor attacks and presents a promising avenue to enhance the privacy of individuals within models trained on uncurated web-scraped data.
Read more7/24/2024
0
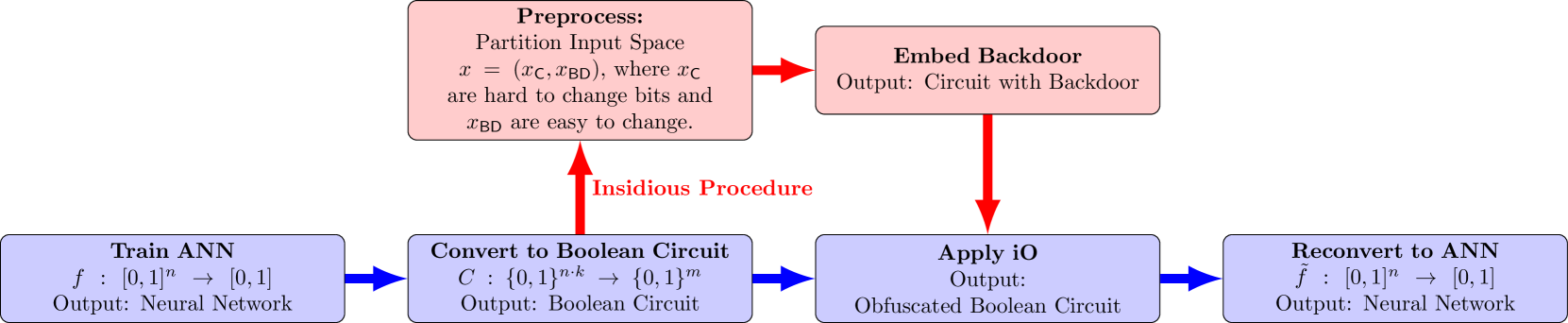
Injecting Undetectable Backdoors in Deep Learning and Language Models
Alkis Kalavasis, Amin Karbasi, Argyris Oikonomou, Katerina Sotiraki, Grigoris Velegkas, Manolis Zampetakis
As ML models become increasingly complex and integral to high-stakes domains such as finance and healthcare, they also become more susceptible to sophisticated adversarial attacks. We investigate the threat posed by undetectable backdoors, as defined in Goldwasser et al. (FOCS '22), in models developed by insidious external expert firms. When such backdoors exist, they allow the designer of the model to sell information on how to slightly perturb their input to change the outcome of the model. We develop a general strategy to plant backdoors to obfuscated neural networks, that satisfy the security properties of the celebrated notion of indistinguishability obfuscation. Applying obfuscation before releasing neural networks is a strategy that is well motivated to protect sensitive information of the external expert firm. Our method to plant backdoors ensures that even if the weights and architecture of the obfuscated model are accessible, the existence of the backdoor is still undetectable. Finally, we introduce the notion of undetectable backdoors to language models and extend our neural network backdoor attacks to such models based on the existence of steganographic functions.
Read more9/10/2024

0
Exploiting the Vulnerability of Large Language Models via Defense-Aware Architectural Backdoor
Abdullah Arafat Miah, Yu Bi
Deep neural networks (DNNs) have long been recognized as vulnerable to backdoor attacks. By providing poisoned training data in the fine-tuning process, the attacker can implant a backdoor into the victim model. This enables input samples meeting specific textual trigger patterns to be classified as target labels of the attacker's choice. While such black-box attacks have been well explored in both computer vision and natural language processing (NLP), backdoor attacks relying on white-box attack philosophy have hardly been thoroughly investigated. In this paper, we take the first step to introduce a new type of backdoor attack that conceals itself within the underlying model architecture. Specifically, we propose to design separate backdoor modules consisting of two functions: trigger detection and noise injection. The add-on modules of model architecture layers can detect the presence of input trigger tokens and modify layer weights using Gaussian noise to disturb the feature distribution of the baseline model. We conduct extensive experiments to evaluate our attack methods using two model architecture settings on five different large language datasets. We demonstrate that the training-free architectural backdoor on a large language model poses a genuine threat. Unlike the-state-of-art work, it can survive the rigorous fine-tuning and retraining process, as well as evade output probability-based defense methods (i.e. BDDR). All the code and data is available https://github.com/SiSL-URI/Arch_Backdoor_LLM.
Read more9/10/2024

0
Here's a Free Lunch: Sanitizing Backdoored Models with Model Merge
Ansh Arora, Xuanli He, Maximilian Mozes, Srinibas Swain, Mark Dras, Qiongkai Xu
The democratization of pre-trained language models through open-source initiatives has rapidly advanced innovation and expanded access to cutting-edge technologies. However, this openness also brings significant security risks, including backdoor attacks, where hidden malicious behaviors are triggered by specific inputs, compromising natural language processing (NLP) system integrity and reliability. This paper suggests that merging a backdoored model with other homogeneous models can significantly remediate backdoor vulnerabilities even if such models are not entirely secure. In our experiments, we verify our hypothesis on various models (BERT-Base, RoBERTa-Large, Llama2-7B, and Mistral-7B) and datasets (SST-2, OLID, AG News, and QNLI). Compared to multiple advanced defensive approaches, our method offers an effective and efficient inference-stage defense against backdoor attacks on classification and instruction-tuned tasks without additional resources or specific knowledge. Our approach consistently outperforms recent advanced baselines, leading to an average of about 75% reduction in the attack success rate. Since model merging has been an established approach for improving model performance, the extra advantage it provides regarding defense can be seen as a cost-free bonus.
Read more6/4/2024