Delving into Multi-modal Multi-task Foundation Models for Road Scene Understanding: From Learning Paradigm Perspectives

0
🖼️
Sign in to get full access
Overview
- The paper discusses the transformative impact of foundation models on intelligent vehicle systems, particularly in the realm of multi-modal and multi-task visual understanding.
- It presents a systematic analysis of multi-modal multi-task visual understanding foundation models (MM-VUFMs) designed for road scenes, including common practices, advanced capabilities, and future trends.
- The paper highlights the importance of these models in achieving a more holistic understanding of the driving environment, contributing to the development of more capable autonomous vehicles.
Plain English Explanation
Foundation models are a type of artificial intelligence system that can be trained on a vast amount of data to acquire a broad and adaptable understanding of the world. These models have revolutionized various fields, including intelligent vehicle systems, by enabling powerful visual understanding capabilities.
In the context of intelligent vehicles, multi-modal multi-task visual understanding foundation models (MM-VUFMs) are particularly useful. These models can process and combine information from multiple sensory inputs, such as cameras, LiDAR, and GPS, to simultaneously handle a variety of driving-related tasks. This allows them to develop a more comprehensive understanding of the surrounding environment, which is crucial for the development of safer and more capable autonomous vehicles.
The paper provides a detailed overview of these MM-VUFMs designed for road scenes, covering common practices, advanced capabilities, and future trends. It highlights how these models can excel in diverse learning paradigms, such as open-world understanding, efficient transfer to new road scenes, continual learning, and interactive and generative capability. These capabilities are crucial for building robust and adaptable autonomous driving systems that can navigate complex and dynamic environments.
Technical Explanation
The paper presents a systematic analysis of multi-modal multi-task visual understanding foundation models (MM-VUFMs) designed for road scenes. These models leverage the power of foundation models, which are trained on vast amounts of data to acquire a broad and adaptable understanding of the world.
The authors discuss common practices in the development of MM-VUFMs, including task-specific models, unified multi-modal models, unified multi-task models, and foundation model prompting techniques. These approaches allow the models to effectively process and fuse data from diverse modalities, such as cameras, LiDAR, and GPS, while simultaneously handling various driving-related tasks with powerful adaptability.
The paper also highlights the advanced capabilities of MM-VUFMs in diverse learning paradigms, such as:
- Open-world understanding: The ability to understand and adapt to new, unseen environments and situations.
- Efficient transfer: The capacity to quickly and effectively transfer knowledge to new road scenes, reducing the need for extensive retraining.
- Continual learning: The capability to continuously learn and update their knowledge without forgetting previous information.
- Interactive and generative capability: The potential to engage in interactive and generative tasks, such as answering questions or generating driving instructions.
These capabilities are crucial for developing more robust and adaptable autonomous driving systems that can navigate complex and dynamic environments.
Critical Analysis
The paper provides a comprehensive overview of the current state of multi-modal multi-task visual understanding foundation models (MM-VUFMs) for road scenes, highlighting their advanced capabilities and potential for driving applications. However, it also acknowledges several key challenges and areas for further research:
-
Closed-loop driving systems: The paper suggests that integrating MM-VUFMs into closed-loop driving systems, where the models can directly control the vehicle's actions, is an important next step. This raises questions about safety, reliability, and interpretability that need to be addressed.
-
Interpretability: While the models demonstrate impressive performance, their complex nature can make it challenging to understand and explain their decision-making processes. Improving the interpretability of these models is crucial for building trust and acceptance in autonomous driving systems.
-
Embodied driving agents: The paper suggests the potential for embodied driving agents, where the MM-VUFMs are integrated into physical robotic platforms. This raises additional challenges, such as real-time performance, physical interactions, and the ability to handle unexpected situations.
-
World models: The paper mentions the potential for MM-VUFMs to serve as world models, which could enable more sophisticated planning and decision-making for autonomous vehicles. However, further research is needed to fully realize this capability.
Overall, the paper provides a valuable resource for researchers and developers working in the field of intelligent vehicle systems, highlighting the transformative potential of foundation models while also acknowledging the ongoing challenges and areas for future exploration.
Conclusion
The paper's analysis of multi-modal multi-task visual understanding foundation models (MM-VUFMs) for road scenes underscores the profound impact of foundation models on intelligent vehicle systems. These models have demonstrated remarkable capabilities in processing and fusing diverse sensory data, while simultaneously handling various driving-related tasks with impressive adaptability.
By leveraging the power of foundation models, MM-VUFMs have the potential to contribute to the development of safer, more capable, and more adaptable autonomous driving systems. The advanced capabilities highlighted in the paper, such as open-world understanding, efficient transfer, continual learning, and interactive and generative capability, are crucial for navigating the complex and dynamic environments encountered in real-world driving scenarios.
However, the paper also identifies key challenges that need to be addressed, such as the integration of MM-VUFMs into closed-loop driving systems, the need for improved interpretability, the integration of embodied driving agents, and the development of sophisticated world models. Addressing these challenges will be essential for realizing the full potential of foundation models in the context of intelligent vehicle systems.
Overall, this paper provides a valuable resource for researchers and developers working to advance the state of the art in autonomous driving and intelligent transportation systems, offering a comprehensive understanding of the current landscape and future directions in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Delving into Multi-modal Multi-task Foundation Models for Road Scene Understanding: From Learning Paradigm Perspectives
Sheng Luo, Wei Chen, Wanxin Tian, Rui Liu, Luanxuan Hou, Xiubao Zhang, Haifeng Shen, Ruiqi Wu, Shuyi Geng, Yi Zhou, Ling Shao, Yi Yang, Bojun Gao, Qun Li, Guobin Wu
Foundation models have indeed made a profound impact on various fields, emerging as pivotal components that significantly shape the capabilities of intelligent systems. In the context of intelligent vehicles, leveraging the power of foundation models has proven to be transformative, offering notable advancements in visual understanding. Equipped with multi-modal and multi-task learning capabilities, multi-modal multi-task visual understanding foundation models (MM-VUFMs) effectively process and fuse data from diverse modalities and simultaneously handle various driving-related tasks with powerful adaptability, contributing to a more holistic understanding of the surrounding scene. In this survey, we present a systematic analysis of MM-VUFMs specifically designed for road scenes. Our objective is not only to provide a comprehensive overview of common practices, referring to task-specific models, unified multi-modal models, unified multi-task models, and foundation model prompting techniques, but also to highlight their advanced capabilities in diverse learning paradigms. These paradigms include open-world understanding, efficient transfer for road scenes, continual learning, interactive and generative capability. Moreover, we provide insights into key challenges and future trends, such as closed-loop driving systems, interpretability, embodied driving agents, and world models. To facilitate researchers in staying abreast of the latest developments in MM-VUFMs for road scenes, we have established a continuously updated repository at https://github.com/rolsheng/MM-VUFM4DS
Read more5/28/2024

0
Foundation Models for Video Understanding: A Survey
Neelu Madan, Andreas Moegelmose, Rajat Modi, Yogesh S. Rawat, Thomas B. Moeslund
Video Foundation Models (ViFMs) aim to learn a general-purpose representation for various video understanding tasks. Leveraging large-scale datasets and powerful models, ViFMs achieve this by capturing robust and generic features from video data. This survey analyzes over 200 video foundational models, offering a comprehensive overview of benchmarks and evaluation metrics across 14 distinct video tasks categorized into 3 main categories. Additionally, we offer an in-depth performance analysis of these models for the 6 most common video tasks. We categorize ViFMs into three categories: 1) Image-based ViFMs, which adapt existing image models for video tasks, 2) Video-Based ViFMs, which utilize video-specific encoding methods, and 3) Universal Foundational Models (UFMs), which combine multiple modalities (image, video, audio, and text etc.) within a single framework. By comparing the performance of various ViFMs on different tasks, this survey offers valuable insights into their strengths and weaknesses, guiding future advancements in video understanding. Our analysis surprisingly reveals that image-based foundation models consistently outperform video-based models on most video understanding tasks. Additionally, UFMs, which leverage diverse modalities, demonstrate superior performance on video tasks. We share the comprehensive list of ViFMs studied in this work at: url{https://github.com/NeeluMadan/ViFM_Survey.git}
Read more5/8/2024

0
Examining the Commitments and Difficulties Inherent in Multimodal Foundation Models for Street View Imagery
Zhenyuan Yang, Xuhui Lin, Qinyi He, Ziye Huang, Zhengliang Liu, Hanqi Jiang, Peng Shu, Zihao Wu, Yiwei Li, Stephen Law, Gengchen Mai, Tianming Liu, Tao Yang
The emergence of Large Language Models (LLMs) and multimodal foundation models (FMs) has generated heightened interest in their applications that integrate vision and language. This paper investigates the capabilities of ChatGPT-4V and Gemini Pro for Street View Imagery, Built Environment, and Interior by evaluating their performance across various tasks. The assessments include street furniture identification, pedestrian and car counts, and road width measurement in Street View Imagery; building function classification, building age analysis, building height analysis, and building structure classification in the Built Environment; and interior room classification, interior design style analysis, interior furniture counts, and interior length measurement in Interior. The results reveal proficiency in length measurement, style analysis, question answering, and basic image understanding, but highlight limitations in detailed recognition and counting tasks. While zero-shot learning shows potential, performance varies depending on the problem domains and image complexities. This study provides new insights into the strengths and weaknesses of multimodal foundation models for practical challenges in Street View Imagery, Built Environment, and Interior. Overall, the findings demonstrate foundational multimodal intelligence, emphasizing the potential of FMs to drive forward interdisciplinary applications at the intersection of computer vision and language.
Read more8/26/2024
0
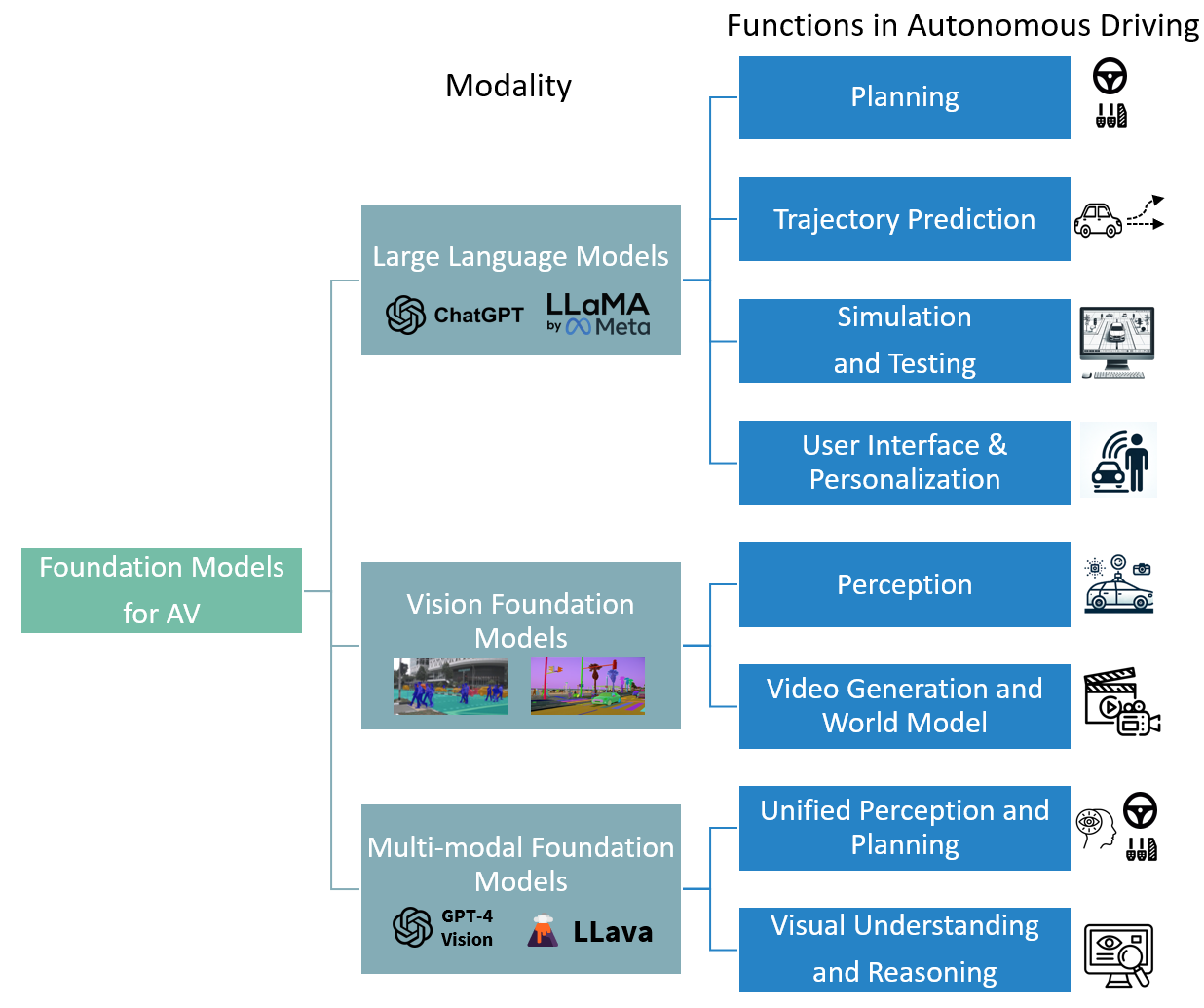
A Survey for Foundation Models in Autonomous Driving
Haoxiang Gao, Zhongruo Wang, Yaqian Li, Kaiwen Long, Ming Yang, Yiqing Shen
The advent of foundation models has revolutionized the fields of natural language processing and computer vision, paving the way for their application in autonomous driving (AD). This survey presents a comprehensive review of more than 40 research papers, demonstrating the role of foundation models in enhancing AD. Large language models contribute to planning and simulation in AD, particularly through their proficiency in reasoning, code generation and translation. In parallel, vision foundation models are increasingly adapted for critical tasks such as 3D object detection and tracking, as well as creating realistic driving scenarios for simulation and testing. Multi-modal foundation models, integrating diverse inputs, exhibit exceptional visual understanding and spatial reasoning, crucial for end-to-end AD. This survey not only provides a structured taxonomy, categorizing foundation models based on their modalities and functionalities within the AD domain but also delves into the methods employed in current research. It identifies the gaps between existing foundation models and cutting-edge AD approaches, thereby charting future research directions and proposing a roadmap for bridging these gaps.
Read more9/6/2024