DePrompt: Desensitization and Evaluation of Personal Identifiable Information in Large Language Model Prompts

0

Sign in to get full access
Overview
- This paper, titled "DePrompt: Desensitization and Evaluation Personal Identifiable Information in Large Language Model Prompts", explores methods for identifying and mitigating the risk of personal identifiable information (PII) in prompts used to interact with large language models.
- The researchers propose a tool called DePrompt that can automatically detect and redact PII from prompts, helping to protect user privacy when interacting with these powerful AI systems.
- The paper presents experiments and evaluations to assess the effectiveness of DePrompt in identifying and removing PII, as well as the impact on the language model's performance.
Plain English Explanation
Large language models (LLMs) like GPT-3 have become incredibly powerful, but they also come with privacy concerns. When people interact with these models by providing prompts, they may inadvertently include personal information that could be sensitive or private.
The researchers behind this paper developed a tool called DePrompt that can automatically identify and remove this type of personal identifiable information (PII) from prompts before they are sent to the language model. This helps protect user privacy by ensuring that sensitive details don't get processed by the powerful AI system.
The paper describes the design and evaluation of DePrompt, showing how it can effectively detect and redact PII without significantly impacting the language model's performance. The key idea is to build a classifier that can recognize different types of PII, such as names, addresses, and phone numbers, and then mask or remove that information from the prompts.
By doing this, the researchers hope to make it safer and more secure for people to interact with large language models, without having to worry about their personal details being captured or misused. This is an important step towards responsible development and deployment of these transformative AI technologies.
Technical Explanation
The paper presents DePrompt, a system designed to detect and mitigate the inclusion of personal identifiable information (PII) in prompts used to interact with large language models. The key components of DePrompt are:
-
PII Detection: The researchers built a PII detection model using a pre-trained language model and fine-tuned it on a dataset of prompts annotated with various types of PII. This allows DePrompt to accurately identify different categories of PII within the input prompts.
-
PII Redaction: Once PII is detected, DePrompt can then mask or remove the sensitive information from the prompt before it is sent to the language model. This is done by replacing the PII with generic placeholder tokens.
The paper evaluates DePrompt's performance on a range of prompts, both in terms of PII detection accuracy and the impact on the language model's outputs. The results show that DePrompt can effectively identify PII with high precision, while the redaction process has a relatively minor effect on the language model's responses.
The authors also discuss potential limitations and future directions, such as exploring more advanced redaction techniques and investigating the tradeoffs between privacy protection and maintaining the quality of the language model's outputs. Overall, the DePrompt system represents an important step towards building more privacy-preserving interfaces for interacting with powerful language models.
Critical Analysis
The DePrompt paper makes a valuable contribution to the ongoing efforts to address privacy concerns in the use of large language models. By focusing on the prompt interface, which is a critical touchpoint between users and these AI systems, the researchers have identified an important area for intervention.
One key strength of the paper is the pragmatic, solution-oriented approach. Rather than simply highlighting the privacy risks, the authors have developed a concrete tool (DePrompt) and evaluated its performance in real-world scenarios. This provides a solid foundation for further research and practical applications.
However, the paper does acknowledge some limitations, such as the potential for false positives in PII detection and the potential impact of redaction on the language model's outputs. These caveats are important to consider, as any privacy-preserving system needs to carefully balance protection with usability and performance.
Additionally, the paper focuses primarily on explicit PII, such as names and addresses. There may be additional privacy risks associated with more subtle or contextual information that could be inferred from prompts. Future research could explore these more nuanced forms of sensitive data leakage.
Overall, the DePrompt paper represents a valuable step forward in developing privacy-preserving techniques for large language models. By continuing to address these critical issues, the research community can help ensure that the transformative power of these AI systems is harnessed in a responsible and ethical manner.
Conclusion
The DePrompt paper presents a novel approach to mitigating the risk of personal identifiable information (PII) in prompts used to interact with large language models. By developing a tool that can automatically detect and redact sensitive data, the researchers have made an important contribution to the ongoing efforts to address privacy concerns in the field of AI.
The key insights and contributions of this work include:
- The design and evaluation of a PII detection and redaction system (DePrompt) that can effectively identify and remove sensitive information from prompts.
- Experimental results demonstrating the effectiveness of DePrompt in preserving user privacy without significantly impacting the language model's performance.
- Discussions of potential limitations and future research directions, highlighting the need for continued efforts to balance privacy protection and system usability.
As large language models continue to advance and become more widely deployed, addressing privacy concerns will be crucial for ensuring the responsible development and deployment of these transformative AI technologies. The DePrompt paper represents an important step in this direction, and its insights and techniques can help pave the way for more secure and trustworthy interactions with powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DePrompt: Desensitization and Evaluation of Personal Identifiable Information in Large Language Model Prompts
Xiongtao Sun, Gan Liu, Zhipeng He, Hui Li, Xiaoguang Li
Prompt serves as a crucial link in interacting with large language models (LLMs), widely impacting the accuracy and interpretability of model outputs. However, acquiring accurate and high-quality responses necessitates precise prompts, which inevitably pose significant risks of personal identifiable information (PII) leakage. Therefore, this paper proposes DePrompt, a desensitization protection and effectiveness evaluation framework for prompt, enabling users to safely and transparently utilize LLMs. Specifically, by leveraging large model fine-tuning techniques as the underlying privacy protection method, we integrate contextual attributes to define privacy types, achieving high-precision PII entity identification. Additionally, through the analysis of key features in prompt desensitization scenarios, we devise adversarial generative desensitization methods that retain important semantic content while disrupting the link between identifiers and privacy attributes. Furthermore, we present utility evaluation metrics for prompt to better gauge and balance privacy and usability. Our framework is adaptable to prompts and can be extended to text usability-dependent scenarios. Through comparison with benchmarks and other model methods, experimental evaluations demonstrate that our desensitized prompt exhibit superior privacy protection utility and model inference results.
Read more8/20/2024
0
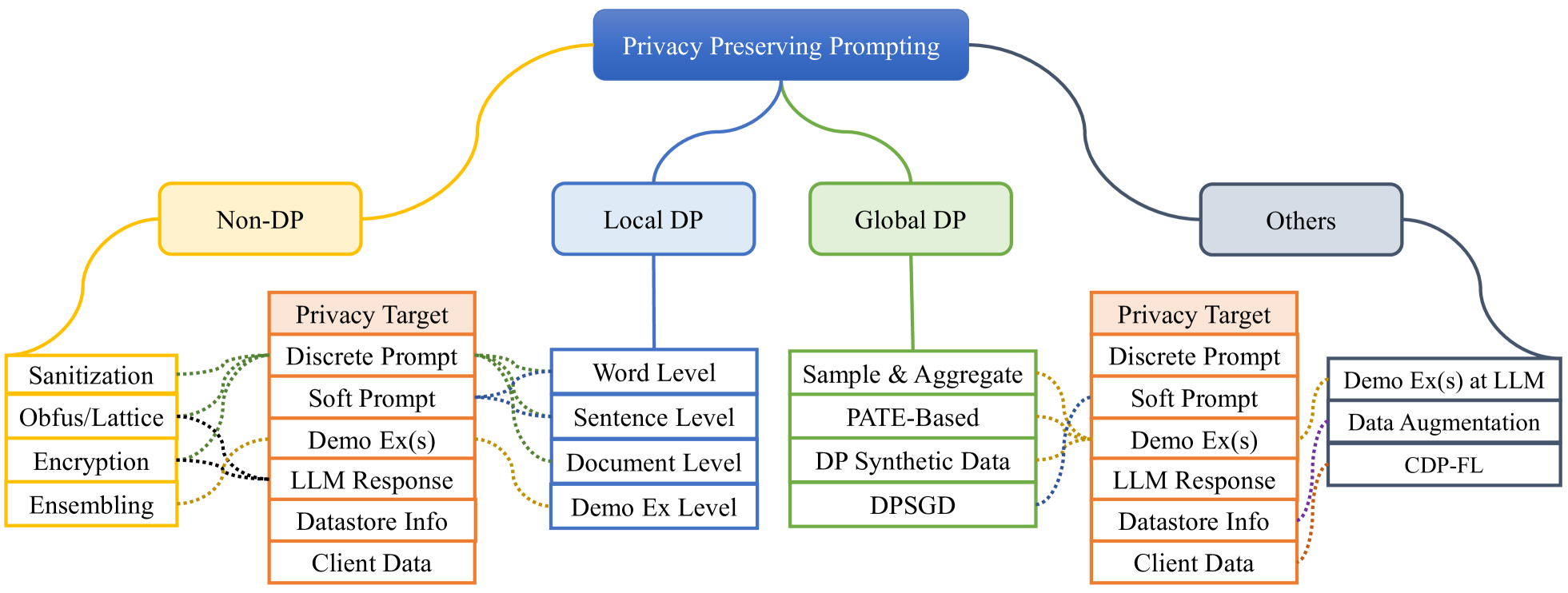
Privacy Preserving Prompt Engineering: A Survey
Kennedy Edemacu, Xintao Wu
Pre-trained language models (PLMs) have demonstrated significant proficiency in solving a wide range of general natural language processing (NLP) tasks. Researchers have observed a direct correlation between the performance of these models and their sizes. As a result, the sizes of these models have notably expanded in recent years, persuading researchers to adopt the term large language models (LLMs) to characterize the larger-sized PLMs. The size expansion comes with a distinct capability called in-context learning (ICL), which represents a special form of prompting and allows the models to be utilized through the presentation of demonstration examples without modifications to the model parameters. Although interesting, privacy concerns have become a major obstacle in its widespread usage. Multiple studies have examined the privacy risks linked to ICL and prompting in general, and have devised techniques to alleviate these risks. Thus, there is a necessity to organize these mitigation techniques for the benefit of the community. This survey provides a systematic overview of the privacy protection methods employed during ICL and prompting in general. We review, analyze, and compare different methods under this paradigm. Furthermore, we provide a summary of the resources accessible for the development of these frameworks. Finally, we discuss the limitations of these frameworks and offer a detailed examination of the promising areas that necessitate further exploration.
Read more4/12/2024

0
Casper: Prompt Sanitization for Protecting User Privacy in Web-Based Large Language Models
Chun Jie Chong, Chenxi Hou, Zhihao Yao, Seyed Mohammadjavad Seyed Talebi
Web-based Large Language Model (LLM) services have been widely adopted and have become an integral part of our Internet experience. Third-party plugins enhance the functionalities of LLM by enabling access to real-world data and services. However, the privacy consequences associated with these services and their third-party plugins are not well understood. Sensitive prompt data are stored, processed, and shared by cloud-based LLM providers and third-party plugins. In this paper, we propose Casper, a prompt sanitization technique that aims to protect user privacy by detecting and removing sensitive information from user inputs before sending them to LLM services. Casper runs entirely on the user's device as a browser extension and does not require any changes to the online LLM services. At the core of Casper is a three-layered sanitization mechanism consisting of a rule-based filter, a Machine Learning (ML)-based named entity recognizer, and a browser-based local LLM topic identifier. We evaluate Casper on a dataset of 4000 synthesized prompts and show that it can effectively filter out Personal Identifiable Information (PII) and privacy-sensitive topics with high accuracy, at 98.5% and 89.9%, respectively.
Read more8/14/2024

0
ConfusionPrompt: Practical Private Inference for Online Large Language Models
Peihua Mai, Ran Yan, Rui Ye, Youjia Yang, Yinchuan Li, Yan Pang
State-of-the-art large language models (LLMs) are commonly deployed as online services, necessitating users to transmit informative prompts to cloud servers, thus engendering substantial privacy concerns. In response, we present ConfusionPrompt, a novel private LLM inference framework designed to obfuscate the server by: (i) decomposing the prompt into sub-prompts, and (ii) generating pseudo prompts along with the genuine sub-prompts as input to the online LLM. Eventually, the returned responses can be recomposed by the user to obtain the final whole response. Such designs endows our framework with advantages over previous protocols that (i) it can be seamlessly integrated with existing black-box LLMs, and (ii) it achieves significantly better privacy-utility trade-off than existing text perturbation-based methods. We develop a $(lambda, mu, rho)$-privacy model to formulate the requirement for a privacy-preserving group of prompts, and provide a complexity analysis, affirming ConfusionPrompt's efficiency. Our empirical evaluation reveals that our method offers significantly higher utility compared to local inference methods using open-source models and perturbation-based techniques, while also requiring much less memory than open-source LLMs.
Read more5/27/2024