Exploring the Role of Audio in Multimodal Misinformation Detection

0
Sign in to get full access
Overview
- Explores the role of audio in detecting misinformation across multiple modalities (text, image, video)
- Proposes a multimodal approach to misinformation detection that leverages audio signals
- Conducts experiments to assess the effectiveness of audio-based features in enhancing misinformation detection
Plain English Explanation
Misinformation, or the spread of false information, is a growing problem in the digital age. This paper explores how audio signals can be used, along with text, images, and video, to better detect and identify misinformation.
The researchers developed a multimodal approach that analyzes content across different formats to determine if it is truthful or misleading. By incorporating audio features, such as tone of voice, pacing, and background noise, the model can potentially pick up on subtle cues that may indicate deception or inaccuracy.
Through a series of experiments, the researchers tested the effectiveness of this multimodal approach compared to methods that only consider text, images, or video alone. The results suggest that including audio data can significantly improve the accuracy of misinformation detection, especially for content that may be difficult to assess based on visual or textual information alone.
Technical Explanation
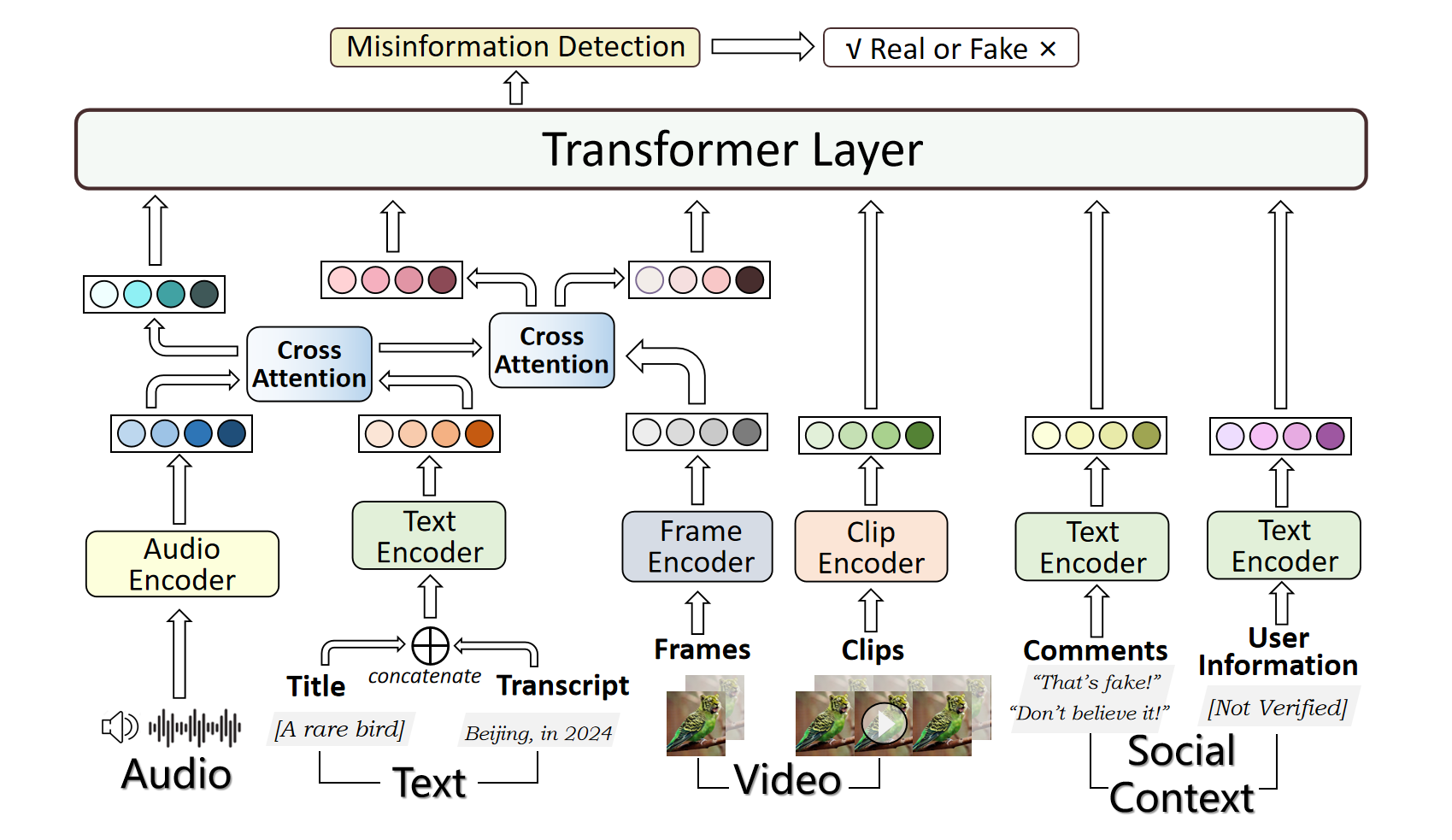
The paper proposes a multimodal approach to misinformation detection that incorporates audio signals in addition to text, images, and video. The researchers developed a deep learning architecture that can process and integrate features from multiple modalities to classify content as truthful or misleading.
The audio-based features included in the model capture characteristics such as pitch, volume, speaking rate, and background noise. These features are extracted using signal processing techniques and then fed into the neural network, along with textual, visual, and video-based features.
The researchers conducted experiments on a dataset of real and fabricated news articles, images, and videos to evaluate the performance of the multimodal approach. They compared the results to models that only used a single modality, such as text-only or image-only approaches.
The findings indicate that the multimodal model outperformed the single-modality models, particularly for content that was challenging to classify based on textual or visual information alone. This suggests that audio signals can provide valuable cues for detecting misinformation, and should be considered as an important component of multimodal content moderation systems.
Critical Analysis
The paper presents a compelling case for the value of incorporating audio features in multimodal misinformation detection. The experimental results demonstrate the potential of this approach to enhance accuracy, especially for content that may be difficult to assess using text or visuals alone.
However, the researchers acknowledge several limitations and areas for further exploration. For example, the dataset used in the experiments may not capture the full diversity of misinformation formats and strategies, and the model's performance may vary across different types of content or contexts.
Additionally, the paper does not delve into the specific mechanisms by which audio signals can provide useful cues for detecting misinformation. Further research may be needed to understand the underlying patterns and characteristics that differentiate truthful and misleading audio content.
Another potential area of concern is the ethical implications of deploying such systems, as they could be used to infringe on individual privacy or free speech. The researchers do not address these issues, which would be an important consideration for any practical applications of the technology.
Overall, the paper makes a strong case for the importance of audio in multimodal misinformation detection, but additional research and thoughtful consideration of the societal impacts would be necessary to fully realize the potential of this approach.
Conclusion
This paper demonstrates the value of incorporating audio signals in multimodal approaches to misinformation detection. By leveraging features such as pitch, volume, and background noise, the proposed model was able to outperform single-modality approaches, particularly for content that was challenging to classify using text or visuals alone.
The findings suggest that audio can provide valuable cues for identifying deceptive or inaccurate information, and should be considered as an important component of content moderation systems designed to combat the spread of misinformation.
However, the researchers acknowledge several limitations, and further research would be necessary to fully understand the mechanisms by which audio signals can enhance misinformation detection, as well as the potential ethical implications of deploying such systems. Overall, this paper represents an important step forward in the development of more robust and effective approaches to addressing the growing challenge of misinformation in the digital age.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploring the Role of Audio in Multimodal Misinformation Detection
Moyang Liu, Yukun Liu, Ruibo Fu, Zhengqi Wen, Jianhua Tao, Xuefei Liu, Guanjun Li
With the rapid development of deepfake technology, especially the deep audio fake technology, misinformation detection on the social media scene meets a great challenge. Social media data often contains multimodal information which includes audio, video, text, and images. However, existing multimodal misinformation detection methods tend to focus only on some of these modalities, failing to comprehensively address information from all modalities. To comprehensively address the various modal information that may appear on social media, this paper constructs a comprehensive multimodal misinformation detection framework. By employing corresponding neural network encoders for each modality, the framework can fuse different modality information and support the multimodal misinformation detection task. Based on the constructed framework, this paper explores the importance of the audio modality in multimodal misinformation detection tasks on social media. By adjusting the architecture of the acoustic encoder, the effectiveness of different acoustic feature encoders in the multimodal misinformation detection tasks is investigated. Furthermore, this paper discovers that audio and video information must be carefully aligned, otherwise the misalignment across different audio and video modalities can severely impair the model performance.
Read more8/23/2024
👀
0
Detecting Misinformation in Multimedia Content through Cross-Modal Entity Consistency: A Dual Learning Approach
Zhe Fu, Kanlun Wang, Wangjiaxuan Xin, Lina Zhou, Shi Chen, Yaorong Ge, Daniel Janies, Dongsong Zhang
The landscape of social media content has evolved significantly, extending from text to multimodal formats. This evolution presents a significant challenge in combating misinformation. Previous research has primarily focused on single modalities or text-image combinations, leaving a gap in detecting multimodal misinformation. While the concept of entity consistency holds promise in detecting multimodal misinformation, simplifying the representation to a scalar value overlooks the inherent complexities of high-dimensional representations across different modalities. To address these limitations, we propose a Multimedia Misinformation Detection (MultiMD) framework for detecting misinformation from video content by leveraging cross-modal entity consistency. The proposed dual learning approach allows for not only enhancing misinformation detection performance but also improving representation learning of entity consistency across different modalities. Our results demonstrate that MultiMD outperforms state-of-the-art baseline models and underscore the importance of each modality in misinformation detection. Our research provides novel methodological and technical insights into multimodal misinformation detection.
Read more9/4/2024
🖼️
0
Enhanced Multimodal Content Moderation of Children's Videos using Audiovisual Fusion
Syed Hammad Ahmed, Muhammad Junaid Khan, Gita Sukthankar
Due to the rise in video content creation targeted towards children, there is a need for robust content moderation schemes for video hosting platforms. A video that is visually benign may include audio content that is inappropriate for young children while being impossible to detect with a unimodal content moderation system. Popular video hosting platforms for children such as YouTube Kids still publish videos which contain audio content that is not conducive to a child's healthy behavioral and physical development. A robust classification of malicious videos requires audio representations in addition to video features. However, recent content moderation approaches rarely employ multimodal architectures that explicitly consider non-speech audio cues. To address this, we present an efficient adaptation of CLIP (Contrastive Language-Image Pre-training) that can leverage contextual audio cues for enhanced content moderation. We incorporate 1) the audio modality and 2) prompt learning, while keeping the backbone modules of each modality frozen. We conduct our experiments on a multimodal version of the MOB (Malicious or Benign) dataset in supervised and few-shot settings.
Read more5/13/2024

0
Contextual Cross-Modal Attention for Audio-Visual Deepfake Detection and Localization
Vinaya Sree Katamneni, Ajita Rattani
In the digital age, the emergence of deepfakes and synthetic media presents a significant threat to societal and political integrity. Deepfakes based on multi-modal manipulation, such as audio-visual, are more realistic and pose a greater threat. Current multi-modal deepfake detectors are often based on the attention-based fusion of heterogeneous data streams from multiple modalities. However, the heterogeneous nature of the data (such as audio and visual signals) creates a distributional modality gap and poses a significant challenge in effective fusion and hence multi-modal deepfake detection. In this paper, we propose a novel multi-modal attention framework based on recurrent neural networks (RNNs) that leverages contextual information for audio-visual deepfake detection. The proposed approach applies attention to multi-modal multi-sequence representations and learns the contributing features among them for deepfake detection and localization. Thorough experimental validations on audio-visual deepfake datasets, namely FakeAVCeleb, AV-Deepfake1M, TVIL, and LAV-DF datasets, demonstrate the efficacy of our approach. Cross-comparison with the published studies demonstrates superior performance of our approach with an improved accuracy and precision by 3.47% and 2.05% in deepfake detection and localization, respectively. Thus, obtaining state-of-the-art performance. To facilitate reproducibility, the code and the datasets information is available at https://github.com/vcbsl/audiovisual-deepfake/.
Read more8/9/2024