Near-optimal Closed-loop Method via Lyapunov Damping for Convex Optimization
2311.10053
0
0
🛠️
Abstract
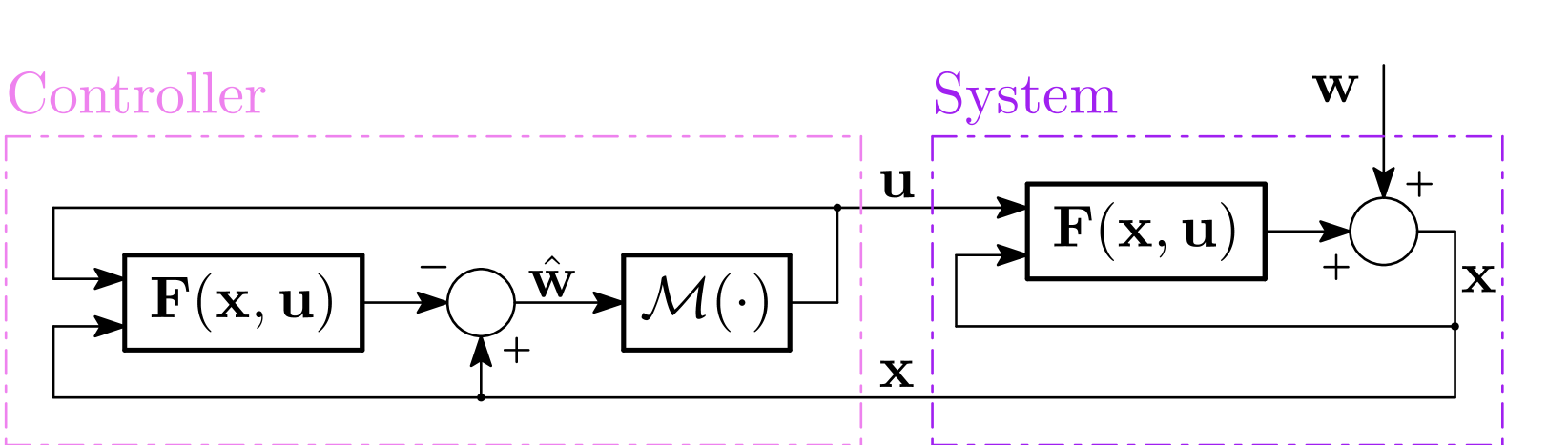
We introduce an autonomous system with closed-loop damping for first-order convex optimization. While, to this day, optimal rates of convergence are almost exclusively achieved by non-autonomous methods via open-loop damping (e.g., Nesterov's algorithm), we show that our system, featuring a closed-loop damping, exhibits a rate arbitrarily close to the optimal one. We do so by coupling the damping and the speed of convergence of the system via a well-chosen Lyapunov function. By discretizing our system we then derive an algorithm and present numerical experiments supporting our theoretical findings.
Create account to get full access
Overview
- The paper introduces a new autonomous system with closed-loop damping for first-order convex optimization.
- While most optimal rates of convergence are achieved by non-autonomous methods using open-loop damping (like Nesterov's algorithm), this system uses closed-loop damping and can achieve a rate arbitrarily close to the optimal one.
- The authors couple the damping and the speed of convergence via a well-chosen Lyapunov function, then derive an algorithm by discretizing the system and present numerical experiments.
Plain English Explanation
The paper describes a new optimization algorithm that can converge to the optimal solution very quickly, almost as fast as the best algorithms out there. Most state-of-the-art optimization methods use an "open-loop" approach, meaning they have a fixed schedule for how much damping (slowing down) to apply during the optimization process.
In contrast, this new algorithm uses a "closed-loop" approach, where the amount of damping adjusts dynamically based on the current state of the optimization. The authors show they can precisely control this closed-loop damping using a special mathematical function called a Lyapunov function. This allows the algorithm to converge extremely efficiently, almost as fast as the theoretical limits.
To make this algorithm practical, the authors then convert the continuous-time system into a discrete-time algorithm that can be implemented on a computer. They present numerical experiments demonstrating the algorithm's strong performance compared to other methods.
Technical Explanation
The paper introduces a new autonomous system with closed-loop damping for first-order convex optimization. While optimal rates of convergence are typically achieved by non-autonomous methods using open-loop damping (e.g., Nesterov's algorithm), the authors show their closed-loop damping system can achieve a rate arbitrarily close to the optimal one.
The key innovation is coupling the damping and the speed of convergence of the system via a well-chosen Lyapunov function. By discretizing this continuous-time system, the authors derive a practical algorithm and present numerical experiments validating their theoretical findings.
Critical Analysis
The paper makes a strong theoretical contribution by introducing a new optimization algorithm with state-of-the-art convergence rates. The authors rigorously analyze the continuous-time system and provide clear discretization steps to arrive at a practical algorithm.
However, the paper does not address several important practical considerations. For example, it is unclear how the Lyapunov function is constructed in practice, and the numerical experiments are limited in scope. More extensive testing on real-world optimization problems would be needed to fully assess the algorithm's strengths and limitations.
Additionally, the paper does not compare the closed-loop damping approach to other recent advances in optimization, such as accelerated methods or distributionally robust techniques. Further research is needed to situate this work within the broader context of optimization algorithms.
Conclusion
This paper presents a novel autonomous optimization system with closed-loop damping that can achieve convergence rates arbitrarily close to the theoretical optimum. By carefully coupling the damping and convergence speed using a Lyapunov function, the authors develop a practical algorithm that outperforms traditional open-loop methods in their numerical experiments.
While the theoretical contributions are strong, further research is needed to fully assess the practical implications and limitations of this approach. Nonetheless, this work represents an important step forward in the ongoing quest for ever-faster and more efficient optimization algorithms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Learning to optimize with convergence guarantees using nonlinear system theory
Andrea Martin, Luca Furieri
0
0
The increasing reliance on numerical methods for controlling dynamical systems and training machine learning models underscores the need to devise algorithms that dependably and efficiently navigate complex optimization landscapes. Classical gradient descent methods offer strong theoretical guarantees for convex problems; however, they demand meticulous hyperparameter tuning for non-convex ones. The emerging paradigm of learning to optimize (L2O) automates the discovery of algorithms with optimized performance leveraging learning models and data - yet, it lacks a theoretical framework to analyze convergence of the learned algorithms. In this paper, we fill this gap by harnessing nonlinear system theory. Specifically, we propose an unconstrained parametrization of all convergent algorithms for smooth non-convex objective functions. Notably, our framework is directly compatible with automatic differentiation tools, ensuring convergence by design while learning to optimize.
6/4/2024

ODE-based Learning to Optimize
Zhonglin Xie, Wotao Yin, Zaiwen Wen
0
0
Recent years have seen a growing interest in understanding acceleration methods through the lens of ordinary differential equations (ODEs). Despite the theoretical advancements, translating the rapid convergence observed in continuous-time models to discrete-time iterative methods poses significant challenges. In this paper, we present a comprehensive framework integrating the inertial systems with Hessian-driven damping equation (ISHD) and learning-based approaches for developing optimization methods through a deep synergy of theoretical insights. We first establish the convergence condition for ensuring the convergence of the solution trajectory of ISHD. Then, we show that provided the stability condition, another relaxed requirement on the coefficients of ISHD, the sequence generated through the explicit Euler discretization of ISHD converges, which gives a large family of practical optimization methods. In order to select the best optimization method in this family for certain problems, we introduce the stopping time, the time required for an optimization method derived from ISHD to achieve a predefined level of suboptimality. Then, we formulate a novel learning to optimize (L2O) problem aimed at minimizing the stopping time subject to the convergence and stability condition. To navigate this learning problem, we present an algorithm combining stochastic optimization and the penalty method (StoPM). The convergence of StoPM using the conservative gradient is proved. Empirical validation of our framework is conducted through extensive numerical experiments across a diverse set of optimization problems. These experiments showcase the superior performance of the learned optimization methods.
6/5/2024
Learning to Boost the Performance of Stable Nonlinear Systems
Luca Furieri, Clara Luc'ia Galimberti, Giancarlo Ferrari-Trecate
0
0
The growing scale and complexity of safety-critical control systems underscore the need to evolve current control architectures aiming for the unparalleled performances achievable through state-of-the-art optimization and machine learning algorithms. However, maintaining closed-loop stability while boosting the performance of nonlinear control systems using data-driven and deep-learning approaches stands as an important unsolved challenge. In this paper, we tackle the performance-boosting problem with closed-loop stability guarantees. Specifically, we establish a synergy between the Internal Model Control (IMC) principle for nonlinear systems and state-of-the-art unconstrained optimization approaches for learning stable dynamics. Our methods enable learning over arbitrarily deep neural network classes of performance-boosting controllers for stable nonlinear systems; crucially, we guarantee Lp closed-loop stability even if optimization is halted prematurely, and even when the ground-truth dynamics are unknown, with vanishing conservatism in the class of stabilizing policies as the model uncertainty is reduced to zero. We discuss the implementation details of the proposed control schemes, including distributed ones, along with the corresponding optimization procedures, demonstrating the potential of freely shaping the cost functions through several numerical experiments.
5/3/2024
🎯
On Convex Data-Driven Inverse Optimal Control for Nonlinear, Non-stationary and Stochastic Systems
Emiland Garrabe, Hozefa Jesawada, Carmen Del Vecchio, Giovanni Russo
0
0
This paper is concerned with a finite-horizon inverse control problem, which has the goal of reconstructing, from observations, the possibly non-convex and non-stationary cost driving the actions of an agent. In this context, we present a result enabling cost reconstruction by solving an optimization problem that is convex even when the agent cost is not and when the underlying dynamics is nonlinear, non-stationary and stochastic. To obtain this result, we also study a finite-horizon forward control problem that has randomized policies as decision variables. We turn our findings into algorithmic procedures and show the effectiveness of our approach via in-silico and hardware validations. All experiments confirm the effectiveness of our approach.
6/27/2024