DINO-VITS: Data-Efficient Zero-Shot TTS with Self-Supervised Speaker Verification Loss for Noise Robustness

0
🤖
Sign in to get full access
Overview
- The researchers propose a dual-objective training approach for the speaker encoder in zero-shot text-to-speech (TTS) systems to improve their noise-robustness.
- The first objective is the speech synthesis task, which helps the speaker encoder capture a wider range of speech characteristics beneficial for voice cloning.
- The second objective is a self-supervised DINO loss, which improves speaker representation learning and ensures robustness to noise and speaker discriminability.
- The researchers also explore training zero-shot TTS on noisy, unlabeled data using a two-stage training strategy that leverages self-supervised speech models to distinguish between noisy and clean speech.
Plain English Explanation
The researchers have found a way to make zero-shot TTS systems more resilient to noise. Zero-shot TTS systems are able to generate speech for a new speaker without any samples of that speaker's voice. However, these systems can struggle with noisy audio.
To address this, the researchers use a dual-objective training approach. The first objective is the typical speech synthesis task, which helps the system learn a wider range of speech characteristics that are useful for voice cloning. The second objective is a self-supervised DINO loss, which improves how the system learns to represent different speakers. This ensures the system can still identify speakers and generate their voice even when the audio is noisy.
Additionally, the researchers explore training zero-shot TTS systems using noisy, unlabeled data. They use a two-stage training process that first leverages self-supervised speech models to distinguish between noisy and clean speech. This allows the zero-shot TTS system to perform better, especially when trained on noisy data, compared to approaches that rely on transcribed speech.
Technical Explanation
The researchers propose a dual-objective training approach for the speaker encoder component of zero-shot TTS systems. The first objective is the speech synthesis task, which helps the speaker encoder capture a wider range of speech characteristics that are beneficial for voice cloning, as described in Ditto: Efficient and Scalable Zero-Shot Text-to-Speech.
The second objective is a self-supervised DINO loss, inspired by Towards Supervised Performance on Speaker Verification from Self-Supervised Representations. This loss improves the speaker encoder's ability to learn robust speaker representations, ensuring noise-robustness and effective speaker discriminability.
The researchers also explore training zero-shot TTS systems on noisy, unlabeled data using a two-stage training strategy. First, they leverage self-supervised speech models to distinguish between noisy and clean speech. This allows the zero-shot TTS system to enhance zero-shot text-to-speech synthesis performance, especially when trained on noisy data, compared to approaches that rely on transcribed speech.
Critical Analysis
The researchers acknowledge that their approach may have limitations in certain scenarios, such as when the noise characteristics differ significantly from the training data. Additionally, they note that the performance gains may be dependent on the specific self-supervised speech models used and the quality of the noisy data.
It would be interesting to see further research exploring the robustness of this approach to a wider range of noise conditions, as well as investigations into the generalization capabilities of the learned speaker representations across different speaking styles and languages.
Conclusion
The researchers have presented an innovative approach to improve the noise-robustness of zero-shot TTS systems. By leveraging dual-objective training and self-supervised learning techniques, they have demonstrated significant improvements in subjective metrics, particularly under noisy conditions.
This research has the potential to enhance the practical applicability of zero-shot TTS systems, making them more resilient to real-world audio environments. The ability to leverage noisy, unlabeled data for training further expands the potential use cases of these systems, reducing the reliance on high-quality, transcribed speech data.
Overall, this work represents an important step forward in addressing the noise-robustness challenge in zero-shot TTS, with promising implications for the broader field of speech synthesis and voice cloning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
0
DINO-VITS: Data-Efficient Zero-Shot TTS with Self-Supervised Speaker Verification Loss for Noise Robustness
Vikentii Pankov, Valeria Pronina, Alexander Kuzmin, Maksim Borisov, Nikita Usoltsev, Xingshan Zeng, Alexander Golubkov, Nikolai Ermolenko, Aleksandra Shirshova, Yulia Matveeva
We address zero-shot TTS systems' noise-robustness problem by proposing a dual-objective training for the speaker encoder using self-supervised DINO loss. This approach enhances the speaker encoder with the speech synthesis objective, capturing a wider range of speech characteristics beneficial for voice cloning. At the same time, the DINO objective improves speaker representation learning, ensuring robustness to noise and speaker discriminability. Experiments demonstrate significant improvements in subjective metrics under both clean and noisy conditions, outperforming traditional speaker-encoderbased TTS systems. Additionally, we explore training zeroshot TTS on noisy, unlabeled data. Our two-stage training strategy, leveraging self-supervised speech models to distinguish between noisy and clean speech, shows notable advances in similarity and naturalness, especially with noisy training datasets, compared to the ASR-transcription-based approach.
Read more6/19/2024

0
Textless Acoustic Model with Self-Supervised Distillation for Noise-Robust Expressive Speech-to-Speech Translation
Min-Jae Hwang, Ilia Kulikov, Benjamin Peloquin, Hongyu Gong, Peng-Jen Chen, Ann Lee
In this paper, we propose a textless acoustic model with a self-supervised distillation strategy for noise-robust expressive speech-to-speech translation (S2ST). Recently proposed expressive S2ST systems have achieved impressive expressivity preservation performances by cascading unit-to-speech (U2S) generator to the speech-to-unit translation model. However, these systems are vulnerable to the presence of noise in input speech, which is an assumption in real-world translation scenarios. To address this limitation, we propose a U2S generator that incorporates a distillation with no label (DINO) self-supervised training strategy into it's pretraining process. Because the proposed method captures noise-agnostic expressivity representation, it can generate qualified speech even in noisy environment. Objective and subjective evaluation results verified that the proposed method significantly improved the performance of the expressive S2ST system in noisy environments while maintaining competitive performance in clean environments.
Read more6/6/2024

0
Multi-modal Adversarial Training for Zero-Shot Voice Cloning
John Janiczek, Dading Chong, Dongyang Dai, Arlo Faria, Chao Wang, Tao Wang, Yuzong Liu
A text-to-speech (TTS) model trained to reconstruct speech given text tends towards predictions that are close to the average characteristics of a dataset, failing to model the variations that make human speech sound natural. This problem is magnified for zero-shot voice cloning, a task that requires training data with high variance in speaking styles. We build off of recent works which have used Generative Advsarial Networks (GAN) by proposing a Transformer encoder-decoder architecture to conditionally discriminates between real and generated speech features. The discriminator is used in a training pipeline that improves both the acoustic and prosodic features of a TTS model. We introduce our novel adversarial training technique by applying it to a FastSpeech2 acoustic model and training on Libriheavy, a large multi-speaker dataset, for the task of zero-shot voice cloning. Our model achieves improvements over the baseline in terms of speech quality and speaker similarity. Audio examples from our system are available online.
Read more8/29/2024
0
Towards Supervised Performance on Speaker Verification with Self-Supervised Learning by Leveraging Large-Scale ASR Models
Victor Miara, Theo Lepage, Reda Dehak
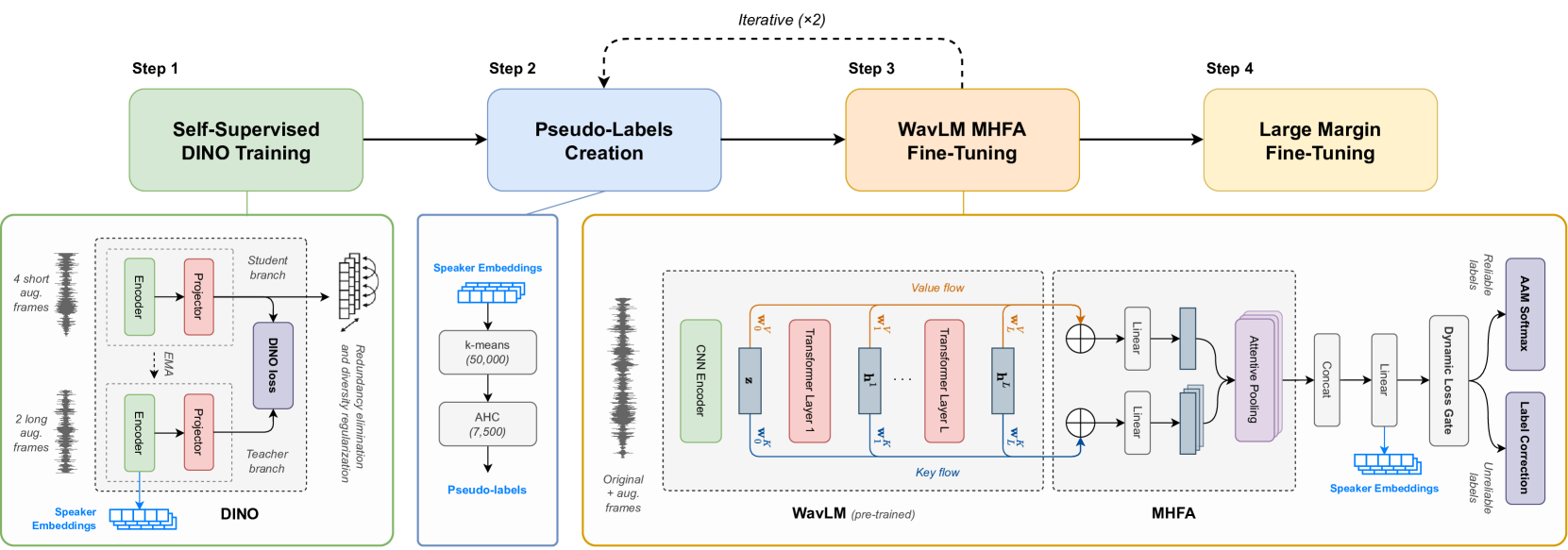
Recent advancements in Self-Supervised Learning (SSL) have shown promising results in Speaker Verification (SV). However, narrowing the performance gap with supervised systems remains an ongoing challenge. Several studies have observed that speech representations from large-scale ASR models contain valuable speaker information. This work explores the limitations of fine-tuning these models for SV using an SSL contrastive objective in an end-to-end approach. Then, we propose a framework to learn speaker representations in an SSL context by fine-tuning a pre-trained WavLM with a supervised loss using pseudo-labels. Initial pseudo-labels are derived from an SSL DINO-based model and are iteratively refined by clustering the model embeddings. Our method achieves 0.99% EER on VoxCeleb1-O, establishing the new state-of-the-art on self-supervised SV. As this performance is close to our supervised baseline of 0.94% EER, this contribution is a step towards supervised performance on SV with SSL.
Read more6/5/2024