LTLDoG: Satisfying Temporally-Extended Symbolic Constraints for Safe Diffusion-based Planning

0
🎲
Sign in to get full access
Overview
- This paper focuses on generating long-term trajectories for robots that adhere to specific instructions and constraints, even when encountered at test time.
- The authors propose a data-driven diffusion-based framework called LTLDoG that modifies the inference steps of the reverse process based on instructions specified using finite linear temporal logic (LTLf).
- LTLDoG leverages a satisfaction value function on LTLf to guide the sampling steps, helping the robot navigate obstacles and follow visitation sequences.
- The method can generalize to new instructions not seen during training, enabling flexible adaptation at test time.
Plain English Explanation
When robots interact with people, it's crucial they can operate effectively while following specific rules and constraints. This paper introduces a new system called LTLDoG that helps robots plan long-term trajectories that adhere to instructions and requirements, even if those instructions are new and haven't been seen before.
The key idea is to use a technique called diffusion, which starts with random noise and gradually transforms it into a desired output. In this case, the desired output is a robot trajectory that satisfies the given instructions. The researchers added a special component to the diffusion process that uses the instructions, written in a formal language called linear temporal logic (LTL), to guide the trajectory generation.
This allows the robot to navigate around obstacles and visit required locations, all while following the rules specified in the instructions. Importantly, the system can adapt to new instructions that weren't part of the original training, giving the robot more flexibility to handle different situations. The researchers tested this approach in robot navigation and manipulation tasks, showing it can generate trajectories that successfully satisfy complex instructions.
Technical Explanation
The authors propose a data-driven diffusion-based framework called LTLDoG that modifies the inference steps of the reverse diffusion process to generate trajectories that adhere to instructions specified using finite linear temporal logic (LTLf).
LTLDoG leverages a satisfaction value function on the LTLf formula, which encodes the degree to which a candidate trajectory satisfies the given instructions. The gradient of this value function is then used to guide the sampling steps during the reverse diffusion process, steering the trajectory towards satisfying the specified constraints and visitation requirements.
Crucially, the value function can be trained to generalize to new LTLf instructions not seen during training. This enables the system to adaptively generate trajectories that satisfy novel instructions at test time, without requiring retraining.
The authors evaluate LTLDoG in robot navigation and manipulation tasks, demonstrating its ability to produce trajectories that satisfy LTLf formulae encoding obstacle avoidance, visitation sequences, and other temporal logic constraints.
Critical Analysis
The paper presents a promising approach for generating robot trajectories that adhere to complex, temporally-extended instructions. The use of diffusion models, coupled with the LTLf satisfaction value function, provides a flexible and adaptable framework for handling novel instructions at test time.
One potential limitation is the reliance on the LTLf language, which may not be accessible to all users. Exploring more intuitive or natural ways of specifying instructions could broaden the accessibility of the system.
Additionally, the paper does not address the computational efficiency of the approach, which could be a concern for real-time robotic applications. Further research into optimizing the inference process or exploring alternative diffusion model architectures may be warranted.
Finally, the paper focuses on single-robot scenarios, but extending the approach to multi-agent settings, as explored in related work like PATLTC and LTL-GDS, could enhance the applicability of the system to more complex, collaborative environments.
Conclusion
This paper presents an innovative diffusion-based framework, LTLDoG, for generating robot trajectories that adhere to complex, temporally-extended instructions specified using linear temporal logic. By leveraging a satisfaction value function to guide the diffusion process, the system can adapt to novel instructions at test time, enabling flexible deployment in a variety of robotic applications.
The research highlights the potential of data-driven approaches, like diffusion models, to address the challenge of operating in complex environments while satisfying specified constraints. Further development and exploration of this line of work could lead to more robust and adaptable robotic systems that can safely and effectively interact with people in real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎲
0
LTLDoG: Satisfying Temporally-Extended Symbolic Constraints for Safe Diffusion-based Planning
Zeyu Feng, Hao Luan, Pranav Goyal, Harold Soh
Operating effectively in complex environments while complying with specified constraints is crucial for the safe and successful deployment of robots that interact with and operate around people. In this work, we focus on generating long-horizon trajectories that adhere to novel static and temporally-extended constraints/instructions at test time. We propose a data-driven diffusion-based framework, LTLDoG, that modifies the inference steps of the reverse process given an instruction specified using finite linear temporal logic ($text{LTL}_f$). LTLDoG leverages a satisfaction value function on $text{LTL}_f$ and guides the sampling steps using its gradient field. This value function can also be trained to generalize to new instructions not observed during training, enabling flexible test-time adaptability. Experiments in robot navigation and manipulation illustrate that the method is able to generate trajectories that satisfy formulae that specify obstacle avoidance and visitation sequences.
Read more5/8/2024
0
Directed Exploration in Reinforcement Learning from Linear Temporal Logic
Marco Bagatella, Andreas Krause, Georg Martius
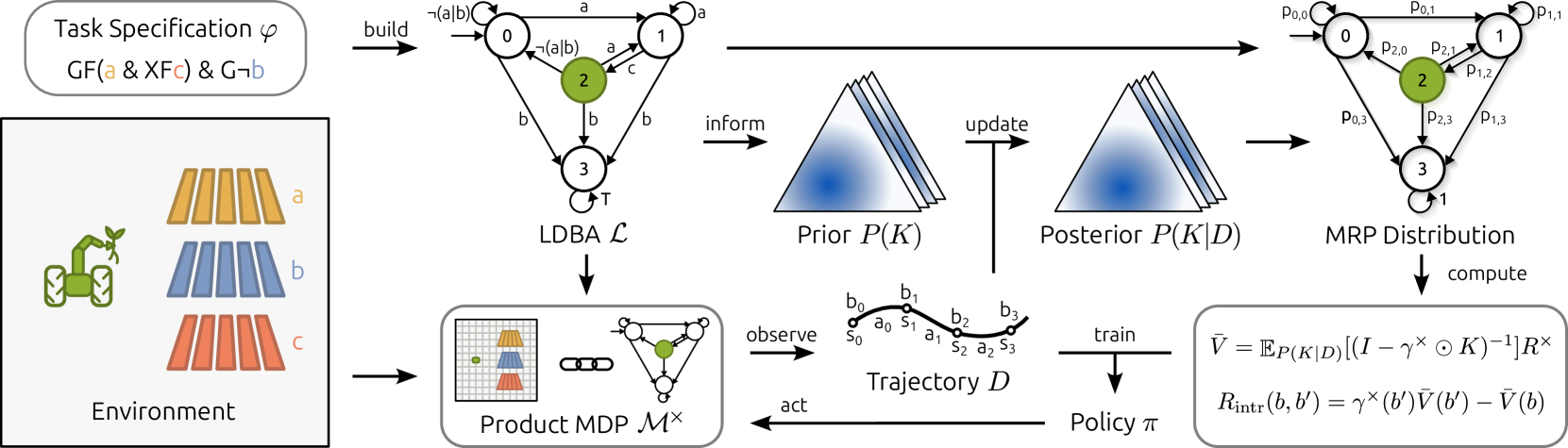
Linear temporal logic (LTL) is a powerful language for task specification in reinforcement learning, as it allows describing objectives beyond the expressivity of conventional discounted return formulations. Nonetheless, recent works have shown that LTL formulas can be translated into a variable rewarding and discounting scheme, whose optimization produces a policy maximizing a lower bound on the probability of formula satisfaction. However, the synthesized reward signal remains fundamentally sparse, making exploration challenging. We aim to overcome this limitation, which can prevent current algorithms from scaling beyond low-dimensional, short-horizon problems. We show how better exploration can be achieved by further leveraging the LTL specification and casting its corresponding Limit Deterministic Buchi Automaton (LDBA) as a Markov reward process, thus enabling a form of high-level value estimation. By taking a Bayesian perspective over LDBA dynamics and proposing a suitable prior distribution, we show that the values estimated through this procedure can be treated as a shaping potential and mapped to informative intrinsic rewards. Empirically, we demonstrate applications of our method from tabular settings to high-dimensional continuous systems, which have so far represented a significant challenge for LTL-based reinforcement learning algorithms.
Read more8/20/2024
🔄
0
LTL-Transfer: Skill Transfer for Temporal Task Specification
Jason Xinyu Liu, Ankit Shah, Eric Rosen, Mingxi Jia, George Konidaris, Stefanie Tellex
Deploying robots in real-world environments, such as households and manufacturing lines, requires generalization across novel task specifications without violating safety constraints. Linear temporal logic (LTL) is a widely used task specification language with a compositional grammar that naturally induces commonalities among tasks while preserving safety guarantees. However, most prior work on reinforcement learning with LTL specifications treats every new task independently, thus requiring large amounts of training data to generalize. We propose LTL-Transfer, a zero-shot transfer algorithm that composes task-agnostic skills learned during training to safely satisfy a wide variety of novel LTL task specifications. Experiments in Minecraft-inspired domains show that after training on only 50 tasks, LTL-Transfer can solve over 90% of 100 challenging unseen tasks and 100% of 300 commonly used novel tasks without violating any safety constraints. We deployed LTL-Transfer at the task-planning level of a quadruped mobile manipulator to demonstrate its zero-shot transfer ability for fetch-and-deliver and navigation tasks.
Read more8/29/2024
➖
0
Reactive Temporal Logic-based Planning and Control for Interactive Robotic Tasks
Farhad Nawaz, Shaoting Peng, Lars Lindemann, Nadia Figueroa, Nikolai Matni
Robots interacting with humans must be safe, reactive and adapt online to unforeseen environmental and task changes. Achieving these requirements concurrently is a challenge as interactive planners lack formal safety guarantees, while safe motion planners lack flexibility to adapt. To tackle this, we propose a modular control architecture that generates both safe and reactive motion plans for human-robot interaction by integrating temporal logic-based discrete task level plans with continuous Dynamical System (DS)-based motion plans. We formulate a reactive temporal logic formula that enables users to define task specifications through structured language, and propose a planning algorithm at the task level that generates a sequence of desired robot behaviors while being adaptive to environmental changes. At the motion level, we incorporate control Lyapunov functions and control barrier functions to compute stable and safe continuous motion plans for two types of robot behaviors: (i) complex, possibly periodic motions given by autonomous DS and (ii) time-critical tasks specified by Signal Temporal Logic~(STL). Our methodology is demonstrated on the Franka robot arm performing wiping tasks on a whiteboard and a mannequin that is compliant to human interactions and adaptive to environmental changes.
Read more5/1/2024