Convergence Guarantee of Dynamic Programming for LTL Surrogate Reward

0
Sign in to get full access
Overview
- This paper analyzes the convergence properties of dynamic programming for finding optimal policies that maximize a surrogate reward function for linear temporal logic (LTL) specifications.
- LTL is a formal language used to specify complex task requirements, but optimizing for LTL objectives directly is challenging.
- The authors propose using a surrogate reward function and show that dynamic programming converges to the optimal policy under certain conditions.
Plain English Explanation
The paper looks at a technique called dynamic programming for solving problems where the goal is to find the best sequence of actions to take to achieve a desired outcome.
In this case, the desired outcome is defined using linear temporal logic (LTL), which is a formal language that can express complex requirements that evolve over time, like "visit location A, then location B, and avoid obstacles along the way."
Directly optimizing for LTL objectives is difficult, so the authors propose using a surrogate reward function - a simpler reward signal that approximates the desired LTL behavior. They show that under certain conditions, dynamic programming will converge to the optimal policy that maximizes this surrogate reward.
In other words, by using a stand-in reward function, they can leverage the power of dynamic programming to find the best sequence of actions to satisfy the original LTL requirements. This could be useful for applications like multi-agent coordination or reinforcement learning with complex goals.
Technical Explanation
The paper analyzes the convergence properties of dynamic programming for finding optimal policies that maximize a surrogate reward function for linear temporal logic (LTL) specifications.
The authors consider a Markov decision process (MDP) framework, where an agent takes actions to transition between states and receives rewards. They define a surrogate reward function that approximates the desired LTL behavior, and show that under certain conditions, dynamic programming will converge to the optimal policy that maximizes this surrogate reward.
Specifically, the key conditions are:
- The MDP must be unichain, meaning there is a single recurrent class of states.
- The surrogate reward function must satisfy a shaping condition that ensures it aligns with the original LTL objective.
The authors provide formal proofs of the convergence guarantee and discuss implications for practical applications like multi-agent coordination and reinforcement learning with complex goals.
Critical Analysis
The paper provides a solid theoretical analysis of the convergence properties of dynamic programming for LTL surrogate rewards. The authors clearly define the problem setting and make reasonable assumptions, such as the unichain MDP condition, which is a common assumption in the literature.
One potential limitation is the reliance on the shaping condition for the surrogate reward function. This may be difficult to verify in practice, as designing a suitable surrogate reward that satisfies the condition could be challenging. The authors acknowledge this and suggest further research into more general conditions or alternative approaches.
Additionally, the paper focuses solely on the theoretical convergence guarantee and does not include any empirical validation of the proposed technique. It would be helpful to see how the approach performs on realistic benchmarks or applications to assess its practical utility.
Overall, the paper makes an important contribution to the understanding of dynamic programming for LTL objectives, but further research is needed to address the practical challenges of implementing such techniques in real-world scenarios.
Conclusion
This paper analyzes the convergence properties of dynamic programming for finding optimal policies that maximize a surrogate reward function for linear temporal logic (LTL) specifications. The authors show that under certain conditions, dynamic programming will converge to the optimal policy that maximizes the surrogate reward, which can serve as a proxy for the original LTL objective.
This work has implications for applications that require satisfying complex, temporally extended requirements, such as multi-agent coordination and reinforcement learning with rich task specifications. The theoretical analysis provides a solid foundation, but further research is needed to address the practical challenges of designing suitable surrogate reward functions and validating the approach on real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Convergence Guarantee of Dynamic Programming for LTL Surrogate Reward
Zetong Xuan, Yu Wang
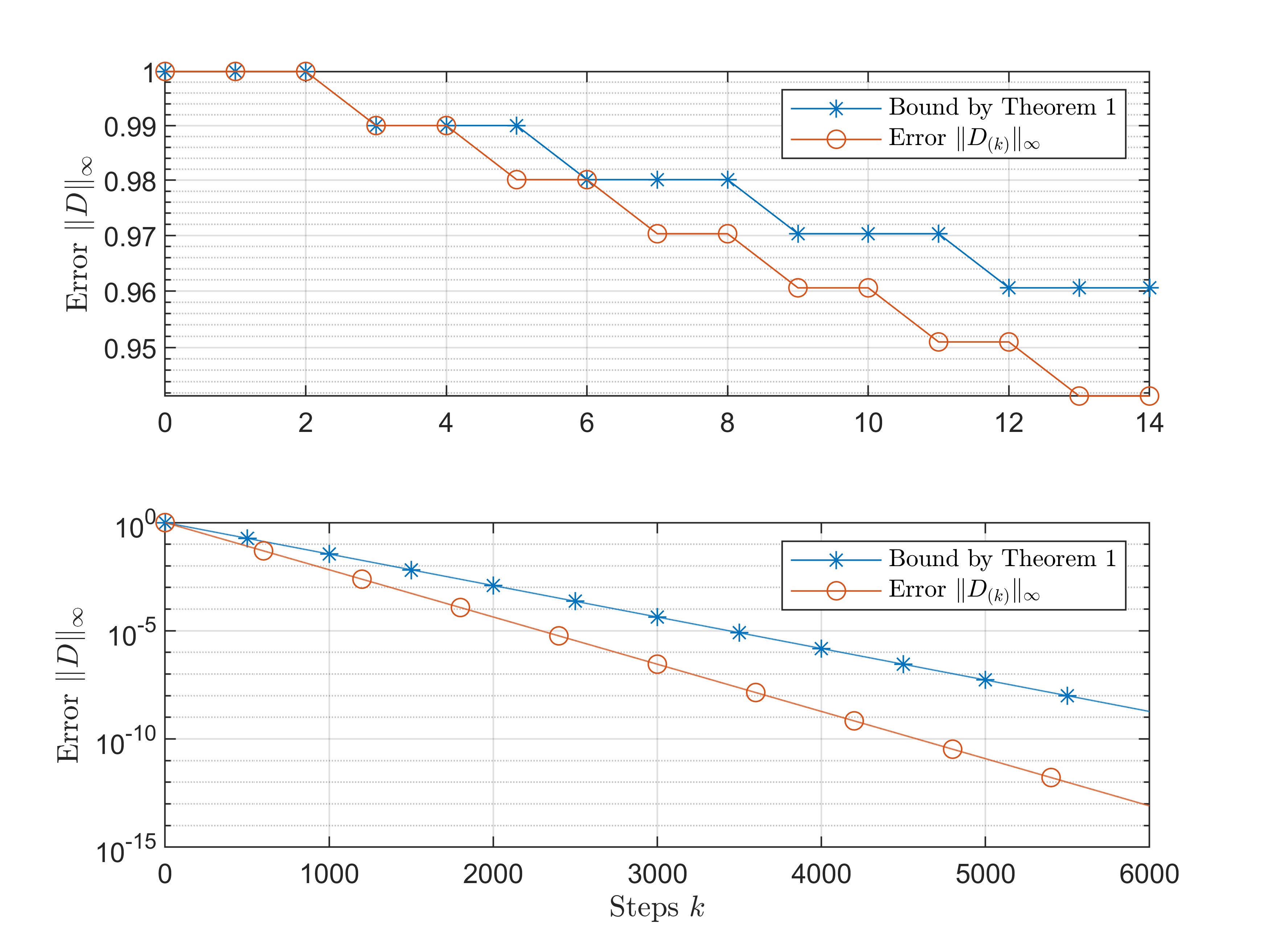
Linear Temporal Logic (LTL) is a formal way of specifying complex objectives for planning problems modeled as Markov Decision Processes (MDPs). The planning problem aims to find the optimal policy that maximizes the satisfaction probability of the LTL objective. One way to solve the planning problem is to use the surrogate reward with two discount factors and dynamic programming, which bypasses the graph analysis used in traditional model-checking. The surrogate reward is designed such that its value function represents the satisfaction probability. However, in some cases where one of the discount factors is set to $1$ for higher accuracy, the computation of the value function using dynamic programming is not guaranteed. This work shows that a multi-step contraction always exists during dynamic programming updates, guaranteeing that the approximate value function will converge exponentially to the true value function. Thus, the computation of satisfaction probability is guaranteed.
Read more8/13/2024
📊
0
On the Uniqueness of Solution for the Bellman Equation of LTL Objectives
Zetong Xuan, Alper Kamil Bozkurt, Miroslav Pajic, Yu Wang
Surrogate rewards for linear temporal logic (LTL) objectives are commonly utilized in planning problems for LTL objectives. In a widely-adopted surrogate reward approach, two discount factors are used to ensure that the expected return approximates the satisfaction probability of the LTL objective. The expected return then can be estimated by methods using the Bellman updates such as reinforcement learning. However, the uniqueness of the solution to the Bellman equation with two discount factors has not been explicitly discussed. We demonstrate with an example that when one of the discount factors is set to one, as allowed in many previous works, the Bellman equation may have multiple solutions, leading to inaccurate evaluation of the expected return. We then propose a condition for the Bellman equation to have the expected return as the unique solution, requiring the solutions for states inside a rejecting bottom strongly connected component (BSCC) to be 0. We prove this condition is sufficient by showing that the solutions for the states with discounting can be separated from those for the states without discounting under this condition
Read more4/9/2024
0
Directed Exploration in Reinforcement Learning from Linear Temporal Logic
Marco Bagatella, Andreas Krause, Georg Martius
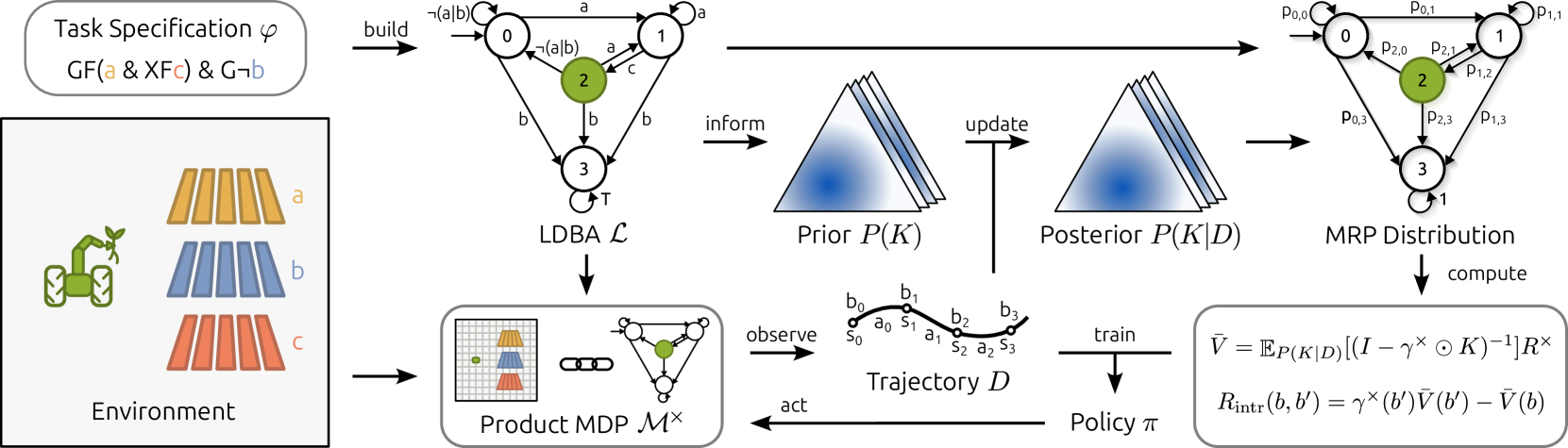
Linear temporal logic (LTL) is a powerful language for task specification in reinforcement learning, as it allows describing objectives beyond the expressivity of conventional discounted return formulations. Nonetheless, recent works have shown that LTL formulas can be translated into a variable rewarding and discounting scheme, whose optimization produces a policy maximizing a lower bound on the probability of formula satisfaction. However, the synthesized reward signal remains fundamentally sparse, making exploration challenging. We aim to overcome this limitation, which can prevent current algorithms from scaling beyond low-dimensional, short-horizon problems. We show how better exploration can be achieved by further leveraging the LTL specification and casting its corresponding Limit Deterministic Buchi Automaton (LDBA) as a Markov reward process, thus enabling a form of high-level value estimation. By taking a Bayesian perspective over LDBA dynamics and proposing a suitable prior distribution, we show that the values estimated through this procedure can be treated as a shaping potential and mapped to informative intrinsic rewards. Empirically, we demonstrate applications of our method from tabular settings to high-dimensional continuous systems, which have so far represented a significant challenge for LTL-based reinforcement learning algorithms.
Read more8/20/2024
🎲
0
LTLDoG: Satisfying Temporally-Extended Symbolic Constraints for Safe Diffusion-based Planning
Zeyu Feng, Hao Luan, Pranav Goyal, Harold Soh
Operating effectively in complex environments while complying with specified constraints is crucial for the safe and successful deployment of robots that interact with and operate around people. In this work, we focus on generating long-horizon trajectories that adhere to novel static and temporally-extended constraints/instructions at test time. We propose a data-driven diffusion-based framework, LTLDoG, that modifies the inference steps of the reverse process given an instruction specified using finite linear temporal logic ($text{LTL}_f$). LTLDoG leverages a satisfaction value function on $text{LTL}_f$ and guides the sampling steps using its gradient field. This value function can also be trained to generalize to new instructions not observed during training, enabling flexible test-time adaptability. Experiments in robot navigation and manipulation illustrate that the method is able to generate trajectories that satisfy formulae that specify obstacle avoidance and visitation sequences.
Read more5/8/2024