Discover-then-Name: Task-Agnostic Concept Bottlenecks via Automated Concept Discovery

0

Sign in to get full access
Overview
- The paper presents a method called "Discover-then-Name" to automatically discover and name interpretable concepts in neural networks.
- This allows for the creation of Concept Bottleneck Models that are both accurate and inherently interpretable.
- The authors show this technique can outperform previous approaches for concept discovery and bottleneck modeling.
Plain English Explanation
The paper introduces a new way to build Concept Bottleneck Models. These are AI models that try to be both accurate at a task and also easy to understand how they work under the hood.
Typically, building these types of interpretable models requires manually defining the key "concepts" the model should learn. The novel contribution here is an approach called "Discover-then-Name" that can automatically find the important concepts in the data, without needing a human to specify them upfront.
The key idea is to first run an unsupervised algorithm to automatically discover a set of meaningful concepts from the training data. Then, the model is trained to predict these discovered concepts, in addition to the final task. This forces the model to learn representations that capture the important underlying concepts, making it more interpretable.
The authors show this approach can outperform previous methods for concept discovery and building interpretable models. It provides a way to create AI systems that are both highly accurate and also transparent about how they work.
Technical Explanation
The paper introduces a new Discover-then-Name method for building Concept Bottleneck Models. These models aim to be both accurate and inherently interpretable by learning representations based on a set of salient, human-understandable concepts.
Typically, building these interpretable models requires manually specifying the key concepts upfront. The novel contribution here is an approach to automatically discover the important concepts from the data in an unsupervised manner, and then train the model to predict these discovered concepts.
The discovery phase uses a clustering algorithm to find a set of concept prototypes that capture the important factors of variation in the data. Then, the model is trained in a multi-task fashion - to both predict the target task labels and also classify the discovered concepts.
This forces the model to learn representations that encode these salient concepts, creating an Interpretable Bottleneck between the input and output. The authors demonstrate this "Discover-then-Name" approach can outperform prior methods on a variety of benchmark datasets.
Critical Analysis
The paper presents a compelling approach for automatically discovering and incorporating interpretable concepts into neural network models. The authors highlight some key limitations and potential future directions:
- The discovered concepts may not perfectly align with human-annotated concepts, so further work is needed to bridge this gap.
- The concept discovery process could be improved by incorporating task-specific information, rather than being purely unsupervised.
- Evaluating the interpretability and fidelity of the discovered concepts remains a challenging open problem.
Additionally, one could question whether the discovered concepts truly capture the "right" level of abstraction, or whether a different granularity or set of concepts would be more useful. More research is needed to understand how the choice of discovered concepts impacts model behavior and interpretability.
Overall, this work represents an important step towards building AI systems that are both accurate and transparent about their inner workings. Continued progress in this direction could lead to more trustworthy and explainable AI models.
Conclusion
This paper introduces a novel "Discover-then-Name" approach for building Concept Bottleneck Models - AI systems that are both highly accurate and inherently interpretable. By automatically discovering a set of salient concepts from the data and then training the model to predict these concepts, it creates an interpretable bottleneck that leads to better performance and transparency.
The authors demonstrate the effectiveness of this technique on several benchmark tasks, highlighting its advantages over prior methods for concept discovery and interpretable modeling. While there are still challenges to address, this work represents an important step towards developing AI systems that are not only powerful, but also understandable and trustworthy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Discover-then-Name: Task-Agnostic Concept Bottlenecks via Automated Concept Discovery
Sukrut Rao, Sweta Mahajan, Moritz Bohle, Bernt Schiele
Concept Bottleneck Models (CBMs) have recently been proposed to address the 'black-box' problem of deep neural networks, by first mapping images to a human-understandable concept space and then linearly combining concepts for classification. Such models typically require first coming up with a set of concepts relevant to the task and then aligning the representations of a feature extractor to map to these concepts. However, even with powerful foundational feature extractors like CLIP, there are no guarantees that the specified concepts are detectable. In this work, we leverage recent advances in mechanistic interpretability and propose a novel CBM approach -- called Discover-then-Name-CBM (DN-CBM) -- that inverts the typical paradigm: instead of pre-selecting concepts based on the downstream classification task, we use sparse autoencoders to first discover concepts learnt by the model, and then name them and train linear probes for classification. Our concept extraction strategy is efficient, since it is agnostic to the downstream task, and uses concepts already known to the model. We perform a comprehensive evaluation across multiple datasets and CLIP architectures and show that our method yields semantically meaningful concepts, assigns appropriate names to them that make them easy to interpret, and yields performant and interpretable CBMs. Code available at https://github.com/neuroexplicit-saar/discover-then-name.
Read more8/13/2024

0
Concept Bottleneck Models Without Predefined Concepts
Simon Schrodi, Julian Schur, Max Argus, Thomas Brox
There has been considerable recent interest in interpretable concept-based models such as Concept Bottleneck Models (CBMs), which first predict human-interpretable concepts and then map them to output classes. To reduce reliance on human-annotated concepts, recent works have converted pretrained black-box models into interpretable CBMs post-hoc. However, these approaches predefine a set of concepts, assuming which concepts a black-box model encodes in its representations. In this work, we eliminate this assumption by leveraging unsupervised concept discovery to automatically extract concepts without human annotations or a predefined set of concepts. We further introduce an input-dependent concept selection mechanism that ensures only a small subset of concepts is used across all classes. We show that our approach improves downstream performance and narrows the performance gap to black-box models, while using significantly fewer concepts in the classification. Finally, we demonstrate how large vision-language models can intervene on the final model weights to correct model errors.
Read more7/8/2024
🌿
0
Coarse-to-Fine Concept Bottleneck Models
Konstantinos P. Panousis, Dino Ienco, Diego Marcos
Deep learning algorithms have recently gained significant attention due to their impressive performance. However, their high complexity and un-interpretable mode of operation hinders their confident deployment in real-world safety-critical tasks. This work targets ante hoc interpretability, and specifically Concept Bottleneck Models (CBMs). Our goal is to design a framework that admits a highly interpretable decision making process with respect to human understandable concepts, on two levels of granularity. To this end, we propose a novel two-level concept discovery formulation leveraging: (i) recent advances in vision-language models, and (ii) an innovative formulation for coarse-to-fine concept selection via data-driven and sparsity-inducing Bayesian arguments. Within this framework, concept information does not solely rely on the similarity between the whole image and general unstructured concepts; instead, we introduce the notion of concept hierarchy to uncover and exploit more granular concept information residing in patch-specific regions of the image scene. As we experimentally show, the proposed construction not only outperforms recent CBM approaches, but also yields a principled framework towards interpetability.
Read more6/28/2024
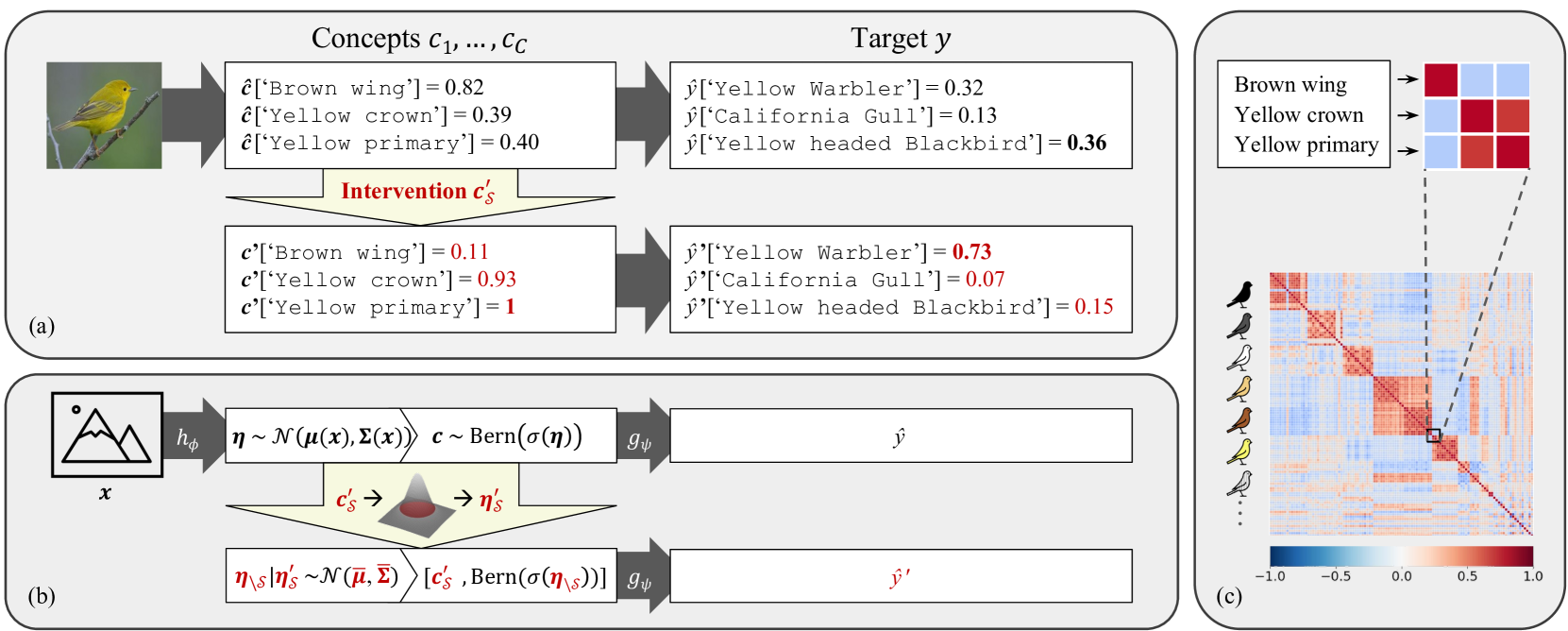
0
Stochastic Concept Bottleneck Models
Moritz Vandenhirtz, Sonia Laguna, Riv{c}ards Marcinkeviv{c}s, Julia E. Vogt
Concept Bottleneck Models (CBMs) have emerged as a promising interpretable method whose final prediction is based on intermediate, human-understandable concepts rather than the raw input. Through time-consuming manual interventions, a user can correct wrongly predicted concept values to enhance the model's downstream performance. We propose Stochastic Concept Bottleneck Models (SCBMs), a novel approach that models concept dependencies. In SCBMs, a single-concept intervention affects all correlated concepts, thereby improving intervention effectiveness. Unlike previous approaches that model the concept relations via an autoregressive structure, we introduce an explicit, distributional parameterization that allows SCBMs to retain the CBMs' efficient training and inference procedure. Additionally, we leverage the parameterization to derive an effective intervention strategy based on the confidence region. We show empirically on synthetic tabular and natural image datasets that our approach improves intervention effectiveness significantly. Notably, we showcase the versatility and usability of SCBMs by examining a setting with CLIP-inferred concepts, alleviating the need for manual concept annotations.
Read more6/28/2024