Distilled Self-Critique of LLMs with Synthetic Data: a Bayesian Perspective

0

Sign in to get full access
Overview
- Investigates a Bayesian approach to self-critiquing language models using synthetic data
- Explores how large language models (LLMs) can develop the ability to evaluate their own outputs
- Focuses on the concept of "distilled self-critique," where models assess their own performance and improve themselves
Plain English Explanation
This paper presents a Bayesian perspective on how large language models (LLMs) can learn to critique and improve their own outputs. The core idea is "distilled self-critique," where the model develops the capability to evaluate its own performance.
The researchers use synthetic data to train the model to assess the quality of its own generated text. This allows the model to identify its own strengths and weaknesses, and then refine its abilities over time. The Bayesian approach provides a framework for the model to update its internal beliefs about its capabilities based on feedback from the synthetic data.
By developing this self-critiquing ability, the hope is that LLMs can become more robust and reliable, able to catch and correct their own mistakes more effectively. This could lead to significant improvements in the overall performance and trustworthiness of these powerful language models.
Technical Explanation
The paper proposes a Bayesian framework for training large language models (LLMs) to develop "distilled self-critique" capabilities. The key idea is to use synthetic data to provide the model with feedback on the quality of its own outputs, allowing it to assess and refine its performance over time.
The researchers design a training process where the model generates text and then evaluates its own generation using a metric-aware inference module. This module provides a Bayesian probability distribution over the quality of the generated text, which the model can use to update its internal beliefs about its capabilities.
By repeatedly generating text, evaluating it, and updating its self-assessment, the model is able to develop a more nuanced understanding of its own strengths and weaknesses. This "distilled self-critique" allows the model to identify areas for improvement and make targeted refinements to its language generation abilities.
The experiments in the paper demonstrate the effectiveness of this approach, showing that models trained with the Bayesian self-critique mechanism are able to generate higher-quality text and make fewer mistakes compared to standard LLMs.
Critical Analysis
The paper presents a promising approach to improving the robustness and reliability of large language models. The Bayesian framework for self-critique seems well-designed and the experimental results are encouraging. However, there are a few potential limitations and areas for further research:
-
The reliance on synthetic data: While the synthetic data allows for controlled feedback and assessment, it may not fully capture the complexities of real-world language use. Further research is needed to see how well the self-critique mechanism transfers to more diverse and naturalistic datasets.
-
Scalability and computational efficiency: Implementing the Bayesian self-critique module may be computationally expensive, especially as model size and complexity increase. Optimizing the approach for efficiency will be important for real-world deployment.
-
Generalization to other tasks: The paper focuses on text generation, but it would be valuable to explore how the self-critique mechanism could be applied to other language-related tasks, such as question answering or dialogue systems.
-
Potential for misuse: As with any powerful language model, there is a risk of the self-critique mechanism being used for malicious purposes, such as generating more convincing disinformation. Careful consideration of these ethical implications will be crucial.
Overall, the paper presents an intriguing approach to enhancing the self-awareness and reliability of large language models, with promising results and avenues for further exploration.
Conclusion
This paper introduces a Bayesian framework for training large language models to develop "distilled self-critique" capabilities. By using synthetic data to provide feedback on the model's own outputs, the approach allows LLMs to assess their strengths and weaknesses and make targeted improvements over time.
The experimental results demonstrate the potential of this self-critiquing mechanism to enhance the overall performance and trustworthiness of language models. While there are some limitations and areas for further research, the paper's insights represent an important step towards more robust and reliable artificial intelligence systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Distilled Self-Critique of LLMs with Synthetic Data: a Bayesian Perspective
Victor Gallego
This paper proposes an interpretation of RLAIF as Bayesian inference by introducing distilled Self-Critique (dSC), which refines the outputs of a LLM through a Gibbs sampler that is later distilled into a fine-tuned model. Only requiring synthetic data, dSC is exercised in experiments regarding safety, sentiment, and privacy control, showing it can be a viable and cheap alternative to align LLMs. Code released at url{https://github.com/vicgalle/distilled-self-critique}.
Read more4/12/2024
💬
0
Mind's Mirror: Distilling Self-Evaluation Capability and Comprehensive Thinking from Large Language Models
Weize Liu, Guocong Li, Kai Zhang, Bang Du, Qiyuan Chen, Xuming Hu, Hongxia Xu, Jintai Chen, Jian Wu
Large language models (LLMs) have achieved remarkable advancements in natural language processing. However, the massive scale and computational demands of these models present formidable challenges when considering their practical deployment in resource-constrained environments. While techniques such as chain-of-thought (CoT) distillation have displayed promise in distilling LLMs into small language models (SLMs), there is a risk that distilled SLMs may still inherit flawed reasoning and hallucinations from LLMs. To address these issues, we propose a twofold methodology: First, we introduce a novel method for distilling the self-evaluation capability from LLMs into SLMs, aiming to mitigate the adverse effects of flawed reasoning and hallucinations inherited from LLMs. Second, we advocate for distilling more comprehensive thinking by incorporating multiple distinct CoTs and self-evaluation outputs, to ensure a more thorough and robust knowledge transfer into SLMs. Experiments on three NLP benchmarks demonstrate that our method significantly improves the performance of distilled SLMs, offering a new perspective for developing more effective and efficient SLMs in resource-constrained environments.
Read more4/9/2024

0
Self and Cross-Model Distillation for LLMs: Effective Methods for Refusal Pattern Alignment
Jie Li, Yi Liu, Chongyang Liu, Xiaoning Ren, Ling Shi, Weisong Sun, Yinxing Xue
Large Language Models (LLMs) like OpenAI's GPT series, Anthropic's Claude, and Meta's LLaMa have shown remarkable capabilities in text generation. However, their susceptibility to toxic prompts presents significant security challenges. This paper investigates alignment techniques, including Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF), to mitigate these risks. We conduct an empirical study on refusal patterns across nine LLMs, revealing that models with uniform refusal patterns, such as Claude3, exhibit higher security. Based on these findings, we propose self-distilling and cross-model distilling methods to enhance LLM security. Our results show that these methods significantly improve refusal rates and reduce unsafe content, with cross-model distilling achieving refusal rates close to Claude3's 94.51%. These findings underscore the potential of distillation-based alignment in securing LLMs against toxic prompts.
Read more6/18/2024
19
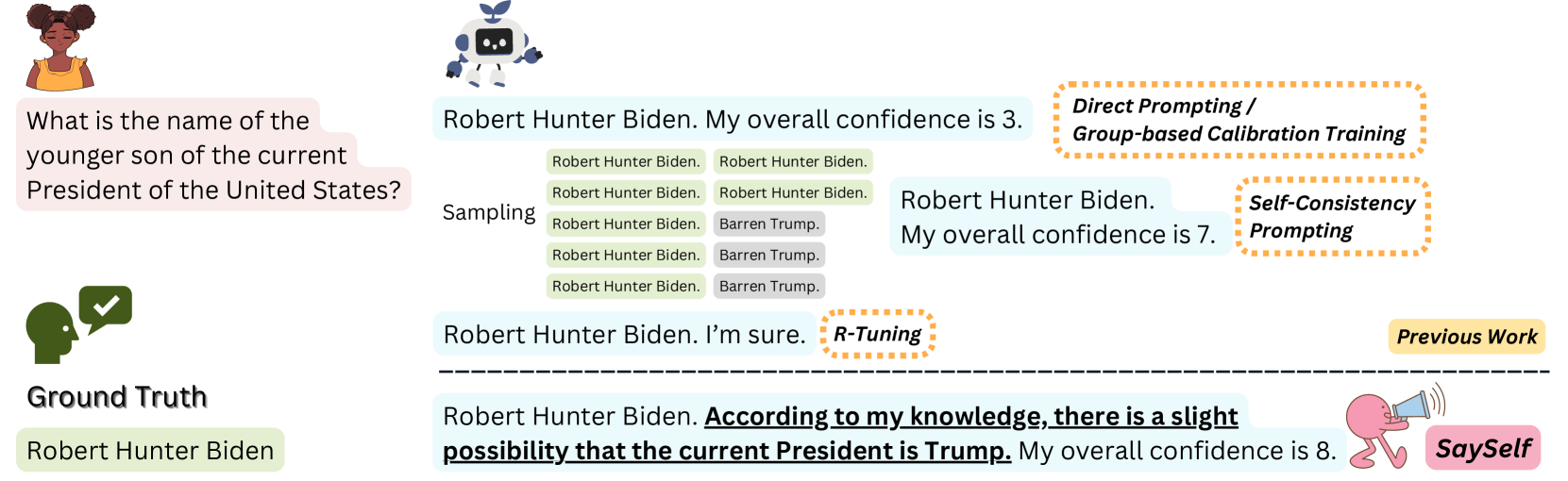
SaySelf: Teaching LLMs to Express Confidence with Self-Reflective Rationales
Tianyang Xu, Shujin Wu, Shizhe Diao, Xiaoze Liu, Xingyao Wang, Yangyi Chen, Jing Gao
Large language models (LLMs) often generate inaccurate or fabricated information and generally fail to indicate their confidence, which limits their broader applications. Previous work elicits confidence from LLMs by direct or self-consistency prompting, or constructing specific datasets for supervised finetuning. The prompting-based approaches have inferior performance, and the training-based approaches are limited to binary or inaccurate group-level confidence estimates. In this work, we present the advanced SaySelf, a training framework that teaches LLMs to express more accurate fine-grained confidence estimates. In addition, beyond the confidence scores, SaySelf initiates the process of directing LLMs to produce self-reflective rationales that clearly identify gaps in their parametric knowledge and explain their uncertainty. This is achieved by using an LLM to automatically summarize the uncertainties in specific knowledge via natural language. The summarization is based on the analysis of the inconsistency in multiple sampled reasoning chains, and the resulting data is utilized for supervised fine-tuning. Moreover, we utilize reinforcement learning with a meticulously crafted reward function to calibrate the confidence estimates, motivating LLMs to deliver accurate, high-confidence predictions and to penalize overconfidence in erroneous outputs. Experimental results in both in-distribution and out-of-distribution datasets demonstrate the effectiveness of SaySelf in reducing the confidence calibration error and maintaining the task performance. We show that the generated self-reflective rationales are reasonable and can further contribute to the calibration. The code is made public at https://github.com/xu1868/SaySelf.
Read more6/6/2024