MUSA: Multi-lingual Speaker Anonymization via Serial Disentanglement

0

Sign in to get full access
Overview
- This paper presents MUSA, a multi-lingual speaker anonymization system that uses serial disentanglement to protect speaker privacy.
- MUSA aims to anonymize speech while preserving linguistic content and intelligibility across multiple languages.
- The system leverages deep learning models to separate speaker identity from linguistic information, enabling the generation of anonymized speech.
Plain English Explanation
The paper introduces MUSA, a new technology that can anonymize speech while still preserving the meaning and intelligibility of what is being said. This is important for protecting people's privacy, especially when sharing voice recordings or audio.
MUSA works by using advanced machine learning models to separate the speaker's identity from the actual words and content being spoken. This allows the system to generate a new, anonymized version of the speech that sounds different from the original speaker, but still conveys the same information.
One key advantage of MUSA is that it can work across multiple languages, not just a single language. This makes it more broadly applicable and useful in diverse settings. The researchers tested MUSA on speech data in various languages to demonstrate its multilingual capabilities.
Overall, MUSA represents an important step forward in enabling people to share audio recordings and voice data while safeguarding individual privacy. By disentangling speaker identity from linguistic content, this technology aims to protect sensitive information while still preserving the meaning and usability of the speech data.
Technical Explanation
The paper introduces a novel multi-lingual speaker anonymization system called MUSA, which uses a serial disentanglement approach to separate speaker identity from linguistic content. [This process is described in more detail in the MULTI-SPEAKER TEXT-TO-SPEECH TRAINING ON SPEAKER ANONYMIZATION paper.]
MUSA consists of two key components: a speaker encoder that extracts speaker identity information, and a speech decoder that generates the anonymized speech output. The speaker encoder is trained to map input speech to a speaker embedding, while the speech decoder is trained to reconstruct the original speech from this speaker-disentangled representation.
To enable multilingual capabilities, the authors leverage language adaptors that can adapt the model to different languages. This allows MUSA to perform speaker anonymization across a variety of languages, as demonstrated in their experiments.
The researchers evaluate MUSA's performance on the VoicePrivacy Challenge dataset, which includes speech data in multiple languages. They compare MUSA to other state-of-the-art speaker anonymization approaches, showing that it achieves strong results in preserving linguistic content while effectively anonymizing speaker identity.
Critical Analysis
The paper makes a strong case for the importance of developing effective speaker anonymization techniques, as highlighted by the growing need for privacy protection in voice-based applications. MUSA's ability to work across multiple languages is a valuable contribution, expanding the practical utility of the system.
However, the authors acknowledge some limitations of their approach. For example, MUSA may still struggle to fully anonymize highly distinctive voices, as mentioned in the DISTINCTIVE NATURAL SPEAKER ANONYMIZATION VIA SINGULAR VALUE DECOMPOSITION paper. Additionally, the system's performance on low-resource languages or noisy speech conditions is not extensively evaluated.
Further research could explore techniques to improve MUSA's robustness and generalization capabilities, such as incorporating end-to-end streaming models for low-latency speaker anonymization. Investigating the system's fairness and bias implications across diverse speaker demographics would also be valuable.
Overall, MUSA represents a promising step forward in multilingual speaker anonymization, but continued advancements in this area are needed to fully address the growing privacy concerns surrounding voice data.
Conclusion
The MUSA system presented in this paper offers a novel approach to multi-lingual speaker anonymization that leverages serial disentanglement of speaker identity and linguistic content. By separating these two factors, MUSA can generate anonymized speech that preserves the original meaning and intelligibility while effectively protecting speaker privacy.
The multilingual capabilities of MUSA are a significant contribution, expanding the system's applicability across diverse language settings. While the paper highlights some limitations, the research demonstrates the potential of this technology to enable the secure sharing and utilization of voice data while safeguarding individual privacy.
As voice-based applications continue to proliferate, the need for robust speaker anonymization solutions will only grow. The MUSA system represents an important step in this direction, paving the way for further advancements in this critical area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MUSA: Multi-lingual Speaker Anonymization via Serial Disentanglement
Jixun Yao, Qing Wang, Pengcheng Guo, Ziqian Ning, Yuguang Yang, Yu Pan, Lei Xie
Speaker anonymization is an effective privacy protection solution designed to conceal the speaker's identity while preserving the linguistic content and para-linguistic information of the original speech. While most prior studies focus solely on a single language, an ideal speaker anonymization system should be capable of handling multiple languages. This paper proposes MUSA, a Multi-lingual Speaker Anonymization approach that employs a serial disentanglement strategy to perform a step-by-step disentanglement from a global time-invariant representation to a temporal time-variant representation. By utilizing semantic distillation and self-supervised speaker distillation, the serial disentanglement strategy can avoid strong inductive biases and exhibit superior generalization performance across different languages. Meanwhile, we propose a straightforward anonymization strategy that employs empty embedding with zero values to simulate the speaker identity concealment process, eliminating the need for conversion to a pseudo-speaker identity and thereby reducing the complexity of speaker anonymization process. Experimental results on VoicePrivacy official datasets and multi-lingual datasets demonstrate that MUSA can effectively protect speaker privacy while preserving linguistic content and para-linguistic information.
Read more7/17/2024

0
Probing the Feasibility of Multilingual Speaker Anonymization
Sarina Meyer, Florian Lux, Ngoc Thang Vu
In speaker anonymization, speech recordings are modified in a way that the identity of the speaker remains hidden. While this technology could help to protect the privacy of individuals around the globe, current research restricts this by focusing almost exclusively on English data. In this study, we extend a state-of-the-art anonymization system to nine languages by transforming language-dependent components to their multilingual counterparts. Experiments testing the robustness of the anonymized speech against privacy attacks and speech deterioration show an overall success of this system for all languages. The results suggest that speaker embeddings trained on English data can be applied across languages, and that the anonymization performance for a language is mainly affected by the quality of the speech synthesis component used for it.
Read more7/4/2024

0
NPU-NTU System for Voice Privacy 2024 Challenge
Jixun Yao, Nikita Kuzmin, Qing Wang, Pengcheng Guo, Ziqian Ning, Dake Guo, Kong Aik Lee, Eng-Siong Chng, Lei Xie
Speaker anonymization is an effective privacy protection solution that conceals the speaker's identity while preserving the linguistic content and paralinguistic information of the original speech. To establish a fair benchmark and facilitate comparison of speaker anonymization systems, the VoicePrivacy Challenge (VPC) was held in 2020 and 2022, with a new edition planned for 2024. In this paper, we describe our proposed speaker anonymization system for VPC 2024. Our system employs a disentangled neural codec architecture and a serial disentanglement strategy to gradually disentangle the global speaker identity and time-variant linguistic content and paralinguistic information. We introduce multiple distillation methods to disentangle linguistic content, speaker identity, and emotion. These methods include semantic distillation, supervised speaker distillation, and frame-level emotion distillation. Based on these distillations, we anonymize the original speaker identity using a weighted sum of a set of candidate speaker identities and a randomly generated speaker identity. Our system achieves the best trade-off of privacy protection and emotion preservation in VPC 2024.
Read more9/9/2024
0
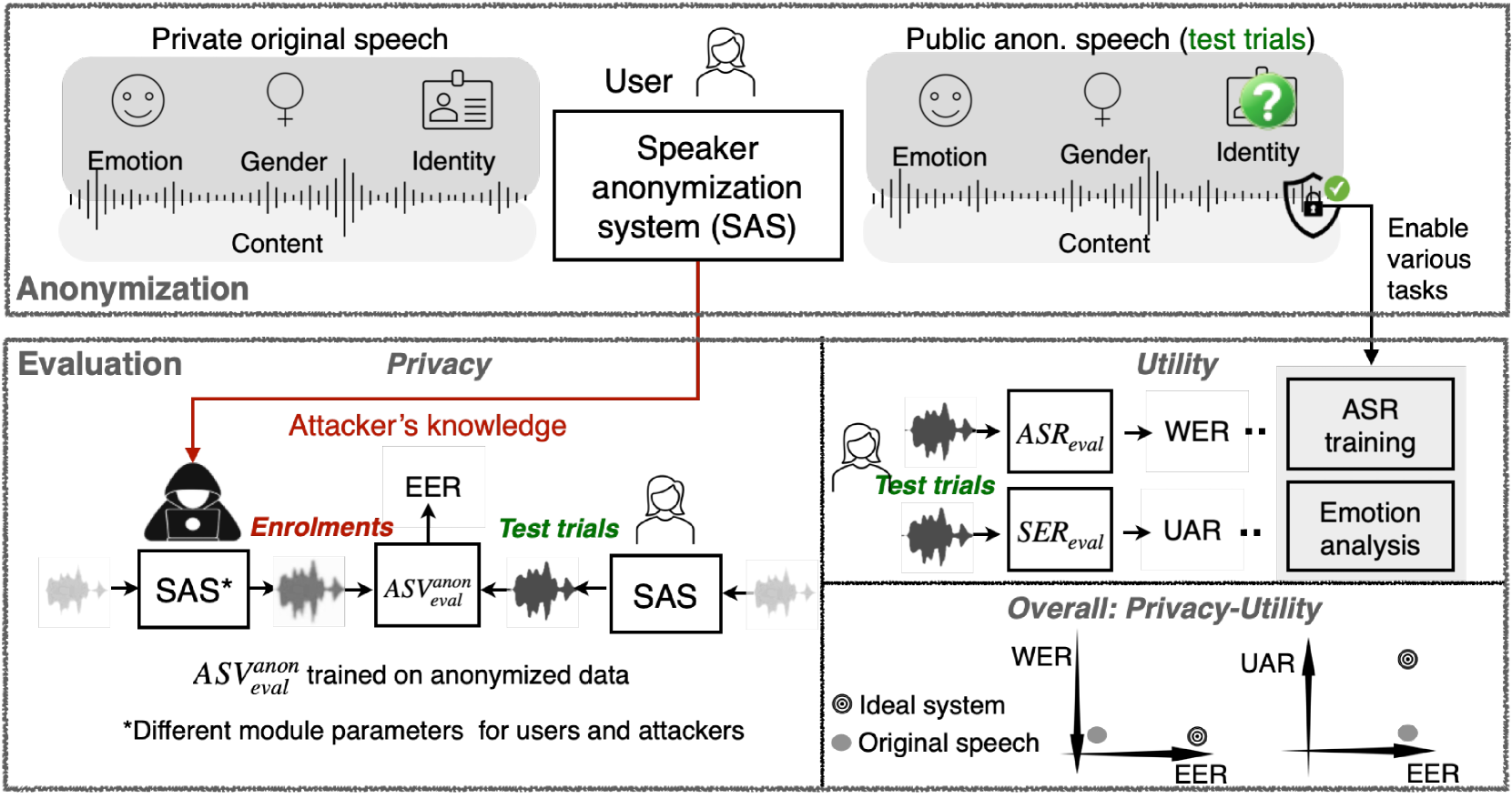
Adapting General Disentanglement-Based Speaker Anonymization for Enhanced Emotion Preservation
Xiaoxiao Miao, Yuxiang Zhang, Xin Wang, Natalia Tomashenko, Donny Cheng Lock Soh, Ian Mcloughlin
A general disentanglement-based speaker anonymization system typically separates speech into content, speaker, and prosody features using individual encoders. This paper explores how to adapt such a system when a new speech attribute, for example, emotion, needs to be preserved to a greater extent. While existing systems are good at anonymizing speaker embeddings, they are not designed to preserve emotion. Two strategies for this are examined. First, we show that integrating emotion embeddings from a pre-trained emotion encoder can help preserve emotional cues, even though this approach slightly compromises privacy protection. Alternatively, we propose an emotion compensation strategy as a post-processing step applied to anonymized speaker embeddings. This conceals the original speaker's identity and reintroduces the emotional traits lost during speaker embedding anonymization. Specifically, we model the emotion attribute using support vector machines to learn separate boundaries for each emotion. During inference, the original speaker embedding is processed in two ways: one, by an emotion indicator to predict emotion and select the emotion-matched SVM accurately; and two, by a speaker anonymizer to conceal speaker characteristics. The anonymized speaker embedding is then modified along the corresponding SVM boundary towards an enhanced emotional direction to save the emotional cues. The proposed strategies are also expected to be useful for adapting a general disentanglement-based speaker anonymization system to preserve other target paralinguistic attributes, with potential for a range of downstream tasks.
Read more8/13/2024