DMLR: Data-centric Machine Learning Research -- Past, Present and Future

0
➖
Sign in to get full access
Overview
• This report outlines the importance of community engagement and infrastructure development for creating the next generation of public datasets that will advance machine learning research. • It charts a path forward as a collective effort to sustain the creation and maintenance of these datasets and methods, aiming for positive scientific, societal, and business impact.
Plain English Explanation
• The report discusses the need for machine learning scientists and researchers to collaborate on building and maintaining high-quality public datasets that can drive progress in the field. • These datasets are crucial for advancing machine learning techniques and enabling new applications that can benefit society and businesses. • To achieve this, the report emphasizes the importance of fostering a strong community of stakeholders, including researchers, data providers, and end-users, to work together in a coordinated way. • It also highlights the need to develop robust infrastructure and processes to ensure the long-term sustainability and maintenance of these valuable datasets.
Technical Explanation
• The report is based on discussions at the inaugural DMLR (Datasets and Machine Learning Representations) workshop at ICML 2023 and prior meetings. • It outlines the key role that public datasets play in advancing machine learning science and unlocking new applications. • The authors emphasize the need for a collaborative, community-driven approach to create and maintain these datasets, drawing on the expertise and resources of various stakeholders. • The report charts a path forward to sustain the development and upkeep of these datasets and the associated methods, with the aim of generating positive impacts in the scientific, societal, and business domains.
Critical Analysis
• The report acknowledges the challenge of sustaining the creation and maintenance of high-quality public datasets over the long term, given the resource and coordination requirements. • While the importance of community engagement and infrastructure development is highlighted, the report could have provided more specific details on the practical steps and mechanisms needed to achieve these goals. • Additionally, the report could have addressed potential risks or limitations associated with the widespread use of public datasets, such as biases or the need for ethical considerations in dataset development and usage.
Conclusion
• This report emphasizes the critical role of public datasets in advancing machine learning research and unlocking new applications with societal and business benefits. • To sustain the creation and maintenance of these valuable resources, the report calls for a collaborative, community-driven approach supported by robust infrastructure and processes. • Implementing this vision will require the concerted efforts of researchers, data providers, and other stakeholders, but the potential rewards in terms of scientific, societal, and economic impact make it a worthwhile endeavor.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
0
DMLR: Data-centric Machine Learning Research -- Past, Present and Future
Luis Oala, Manil Maskey, Lilith Bat-Leah, Alicia Parrish, Nezihe Merve Gurel, Tzu-Sheng Kuo, Yang Liu, Rotem Dror, Danilo Brajovic, Xiaozhe Yao, Max Bartolo, William A Gaviria Rojas, Ryan Hileman, Rainier Aliment, Michael W. Mahoney, Meg Risdal, Matthew Lease, Wojciech Samek, Debojyoti Dutta, Curtis G Northcutt, Cody Coleman, Braden Hancock, Bernard Koch, Girmaw Abebe Tadesse, Bojan Karlav{s}, Ahmed Alaa, Adji Bousso Dieng, Natasha Noy, Vijay Janapa Reddi, James Zou, Praveen Paritosh, Mihaela van der Schaar, Kurt Bollacker, Lora Aroyo, Ce Zhang, Joaquin Vanschoren, Isabelle Guyon, Peter Mattson
Drawing from discussions at the inaugural DMLR workshop at ICML 2023 and meetings prior, in this report we outline the relevance of community engagement and infrastructure development for the creation of next-generation public datasets that will advance machine learning science. We chart a path forward as a collective effort to sustain the creation and maintenance of these datasets and methods towards positive scientific, societal and business impact.
Read more6/4/2024

0
AI Competitions and Benchmarks: Dataset Development
Romain Egele, Julio C. S. Jacques Junior, Jan N. van Rijn, Isabelle Guyon, Xavier Bar'o, Albert Clap'es, Prasanna Balaprakash, Sergio Escalera, Thomas Moeslund, Jun Wan
Machine learning is now used in many applications thanks to its ability to predict, generate, or discover patterns from large quantities of data. However, the process of collecting and transforming data for practical use is intricate. Even in today's digital era, where substantial data is generated daily, it is uncommon for it to be readily usable; most often, it necessitates meticulous manual data preparation. The haste in developing new models can frequently result in various shortcomings, potentially posing risks when deployed in real-world scenarios (eg social discrimination, critical failures), leading to the failure or substantial escalation of costs in AI-based projects. This chapter provides a comprehensive overview of established methodological tools, enriched by our practical experience, in the development of datasets for machine learning. Initially, we develop the tasks involved in dataset development and offer insights into their effective management (including requirements, design, implementation, evaluation, distribution, and maintenance). Then, we provide more details about the implementation process which includes data collection, transformation, and quality evaluation. Finally, we address practical considerations regarding dataset distribution and maintenance.
Read more4/16/2024
0
Towards Data-Centric Automatic R&D
Haotian Chen, Xinjie Shen, Zeqi Ye, Wenjun Feng, Haoxue Wang, Xiao Yang, Xu Yang, Weiqing Liu, Jiang Bian
The progress of humanity is driven by those successful discoveries accompanied by countless failed experiments. Researchers often seek the potential research directions by reading and then verifying them through experiments. The process imposes a significant burden on researchers. In the past decade, the data-driven black-box deep learning method has demonstrated its effectiveness in a wide range of real-world scenarios, which exacerbates the experimental burden of researchers and thus renders the potential successful discoveries veiled. Therefore, automating such a research and development (R&D) process is an urgent need. In this paper, we serve as the first effort to formalize the goal by proposing a Real-world Data-centric automatic R&D Benchmark, namely RD2Bench. RD2Bench benchmarks all the operations in data-centric automatic R&D (D-CARD) as a whole to navigate future work toward our goal directly. We focus on evaluating the interaction and synergistic effects of various model capabilities and aiding in selecting well-performing trustworthy models. Although RD2Bench is very challenging to the state-of-the-art (SOTA) large language model (LLM) named GPT-4, indicating ample research opportunities and more research efforts, LLMs possess promising potential to bring more significant development to D-CARD: They are able to implement some simple methods without adopting any additional techniques. We appeal to future work to take developing techniques for tackling automatic R&D into consideration, thus bringing the opportunities of the potential revolutionary upgrade to human productivity.
Read more7/31/2024
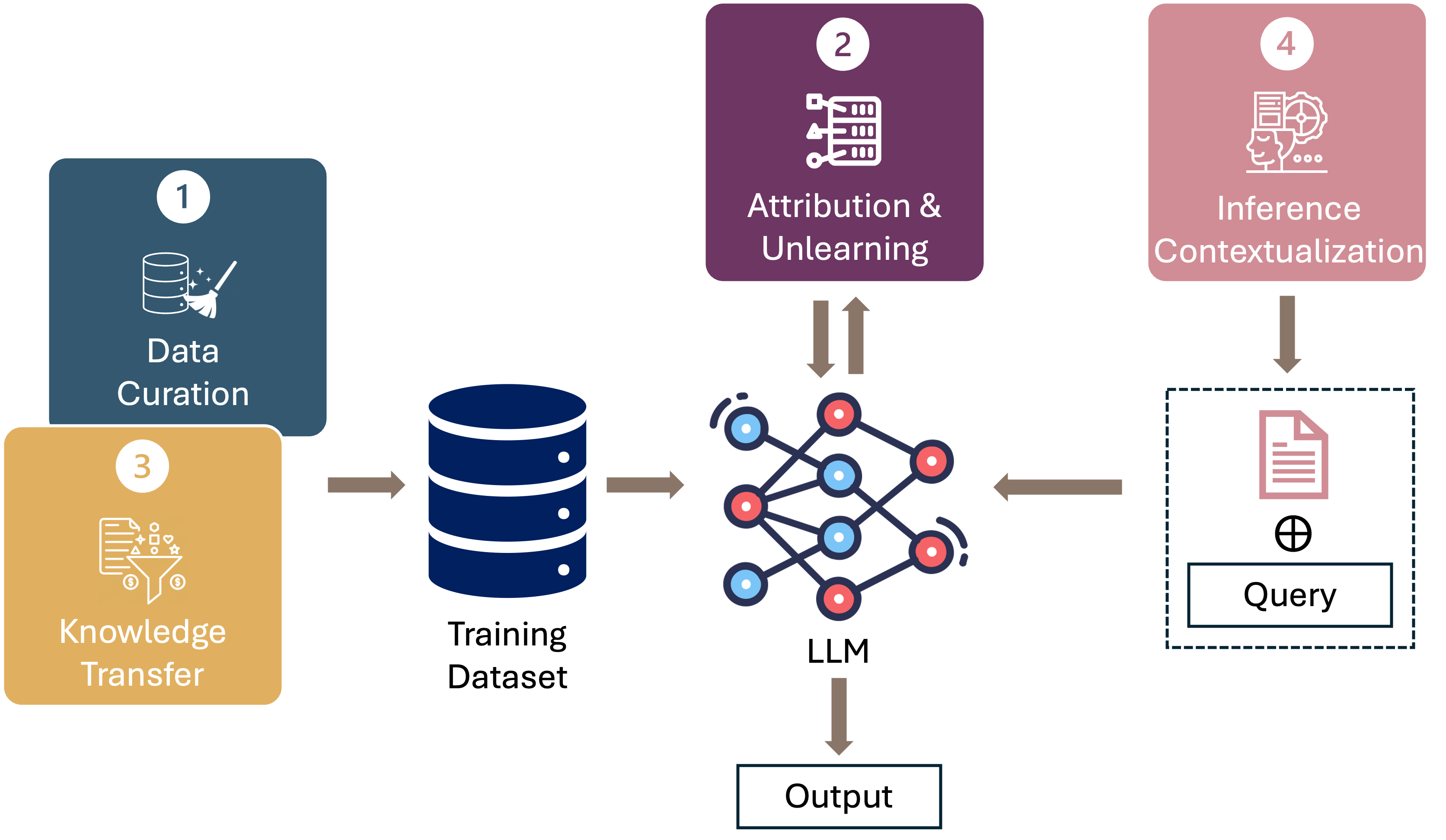
0
Data-Centric AI in the Age of Large Language Models
Xinyi Xu, Zhaoxuan Wu, Rui Qiao, Arun Verma, Yao Shu, Jingtan Wang, Xinyuan Niu, Zhenfeng He, Jiangwei Chen, Zijian Zhou, Gregory Kang Ruey Lau, Hieu Dao, Lucas Agussurja, Rachael Hwee Ling Sim, Xiaoqiang Lin, Wenyang Hu, Zhongxiang Dai, Pang Wei Koh, Bryan Kian Hsiang Low
This position paper proposes a data-centric viewpoint of AI research, focusing on large language models (LLMs). We start by making the key observation that data is instrumental in the developmental (e.g., pretraining and fine-tuning) and inferential stages (e.g., in-context learning) of LLMs, and yet it receives disproportionally low attention from the research community. We identify four specific scenarios centered around data, covering data-centric benchmarks and data curation, data attribution, knowledge transfer, and inference contextualization. In each scenario, we underscore the importance of data, highlight promising research directions, and articulate the potential impacts on the research community and, where applicable, the society as a whole. For instance, we advocate for a suite of data-centric benchmarks tailored to the scale and complexity of data for LLMs. These benchmarks can be used to develop new data curation methods and document research efforts and results, which can help promote openness and transparency in AI and LLM research.
Read more6/21/2024