DMoERM: Recipes of Mixture-of-Experts for Effective Reward Modeling

0

Sign in to get full access
Overview
- This paper proposes a novel approach called DMoERM (Disentangled Mixture-of-Experts for Reward Modeling) to effectively model rewards in reinforcement learning environments.
- The key idea is to use a mixture-of-experts architecture, where each expert specializes in modeling a different aspect of the reward function.
- The experts are trained to be disentangled, meaning they capture distinct reward components, which can improve the overall reward modeling performance.
Plain English Explanation
In reinforcement learning, accurately modeling the reward function is crucial for an agent to learn the right behavior. The DMoERM approach introduced in this paper aims to make that modeling more effective.
The core concept is to use a "mixture-of-experts" model, where instead of a single neural network trying to capture the entire reward function, the model is divided into multiple "experts" - each one specializing in a different aspect of the reward. For example, one expert might focus on tracking the agent's score, while another expert monitors the agent's energy usage.
By training these experts to be "disentangled" - meaning they capture distinct and non-overlapping reward components - the overall model can more accurately represent the full reward function. This is analogous to how a group of specialists can often solve a complex problem better than a single generalist.
The paper shows that this DMoERM approach outperforms standard reward modeling techniques in several benchmark environments, highlighting its effectiveness.
Technical Explanation
The key innovation of the DMoERM approach is its mixture-of-experts architecture for reward modeling. Instead of a single neural network trying to capture the entire reward function, DMoERM has multiple "expert" networks, each specializing in modeling a different aspect of the reward.
To train these experts to be disentangled and capture distinct reward components, the authors propose a novel training objective that encourages the experts to specialize. This is combined with techniques like sparse expert regularization and dense training with sparse inference to further improve the model's efficiency and performance.
Experiments on a range of reinforcement learning environments, including multi-head mixture-of-experts tasks, demonstrate that DMoERM outperforms standard reward modeling baselines. The disentangled experts are shown to capture distinct reward components, leading to more accurate overall reward prediction.
Critical Analysis
The DMoERM approach presents a promising direction for improving reward modeling in reinforcement learning, but the paper also acknowledges several limitations and areas for future work.
One key limitation is that the disentanglement of experts is not guaranteed, and the authors note that further research is needed to ensure robust and reliable disentanglement. Additionally, the performance of DMoERM may be sensitive to the specific task and environment, and more extensive evaluation across a broader range of domains would be valuable.
Another potential concern is the computational overhead of the mixture-of-experts architecture, which may limit its scalability to large-scale problems. The authors touch on techniques like sparse expert selection to mitigate this, but further optimization and efficiency improvements could be explored.
Overall, the DMoERM approach is a compelling contribution to the field of reinforcement learning, offering a novel and effective way to model complex reward functions. However, as with any research, continued investigation and refinement will be necessary to fully realize its potential.
Conclusion
The DMoERM paper presents a promising new method for reward modeling in reinforcement learning environments. By leveraging a mixture-of-experts architecture with disentangled experts, the approach can more accurately capture the nuances of complex reward functions, leading to improved agent performance.
While the paper demonstrates the effectiveness of DMoERM on several benchmark tasks, further research is needed to address the limitations and explore its applicability to a wider range of real-world reinforcement learning problems. Continued advancements in this area could have significant implications for the development of more capable and reliable reinforcement learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DMoERM: Recipes of Mixture-of-Experts for Effective Reward Modeling
Shanghaoran Quan
The performance of the reward model (RM) is a critical factor in improving the effectiveness of the large language model (LLM) during alignment fine-tuning. There remain two challenges in RM training: 1) training the same RM using various categories of data may cause its generalization performance to suffer from multi-task disturbance, and 2) the human annotation consistency rate is generally only $60%$ to $75%$, causing training data to contain a lot of noise. To tackle these two challenges, we introduced the idea of Mixture-of-Experts (MoE) into the field of RM for the first time. We propose the Double-Layer MoE RM (DMoERM). The outer layer MoE is a sparse model. After classifying an input into task categories, we route it to the corresponding inner layer task-specific model. The inner layer MoE is a dense model. We decompose the specific task into multiple capability dimensions and individually fine-tune a LoRA expert on each one. Their outputs are then synthesized by an MLP to compute the final rewards. To minimize costs, we call a public LLM API to obtain the capability preference labels. The validation on manually labeled datasets confirms that our model attains superior consistency with human preference and outstrips advanced generative approaches. Meanwhile, through BoN sampling and RL experiments, we demonstrate that our model outperforms state-of-the-art ensemble methods of RM and mitigates the overoptimization problem. Our code and dataset are available at: https://github.com/quanshr/DMoERM-v1.
Read more4/30/2024

0
A Survey on Mixture of Experts
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, Jiayi Huang
Large language models (LLMs) have garnered unprecedented advancements across diverse fields, ranging from natural language processing to computer vision and beyond. The prowess of LLMs is underpinned by their substantial model size, extensive and diverse datasets, and the vast computational power harnessed during training, all of which contribute to the emergent abilities of LLMs (e.g., in-context learning) that are not present in small models. Within this context, the mixture of experts (MoE) has emerged as an effective method for substantially scaling up model capacity with minimal computation overhead, gaining significant attention from academia and industry. Despite its growing prevalence, there lacks a systematic and comprehensive review of the literature on MoE. This survey seeks to bridge that gap, serving as an essential resource for researchers delving into the intricacies of MoE. We first briefly introduce the structure of the MoE layer, followed by proposing a new taxonomy of MoE. Next, we overview the core designs for various MoE models including both algorithmic and systemic aspects, alongside collections of available open-source implementations, hyperparameter configurations and empirical evaluations. Furthermore, we delineate the multifaceted applications of MoE in practice, and outline some potential directions for future research. To facilitate ongoing updates and the sharing of cutting-edge developments in MoE research, we have established a resource repository accessible at https://github.com/withinmiaov/A-Survey-on-Mixture-of-Experts.
Read more7/10/2024

0
$texttt{MoE-RBench}$: Towards Building Reliable Language Models with Sparse Mixture-of-Experts
Guanjie Chen, Xinyu Zhao, Tianlong Chen, Yu Cheng
Mixture-of-Experts (MoE) has gained increasing popularity as a promising framework for scaling up large language models (LLMs). However, the reliability assessment of MoE lags behind its surging applications. Moreover, when transferred to new domains such as in fine-tuning MoE models sometimes underperform their dense counterparts. Motivated by the research gap and counter-intuitive phenomenon, we propose $texttt{MoE-RBench}$, the first comprehensive assessment of SMoE reliability from three aspects: $textit{(i)}$ safety and hallucination, $textit{(ii)}$ resilience to adversarial attacks, and $textit{(iii)}$ out-of-distribution robustness. Extensive models and datasets are tested to compare the MoE to dense networks from these reliability dimensions. Our empirical observations suggest that with appropriate hyperparameters, training recipes, and inference techniques, we can build the MoE model more reliably than the dense LLM. In particular, we find that the robustness of SMoE is sensitive to the basic training settings. We hope that this study can provide deeper insights into how to adapt the pre-trained MoE model to other tasks with higher-generation security, quality, and stability. Codes are available at https://github.com/UNITES-Lab/MoE-RBench
Read more6/18/2024
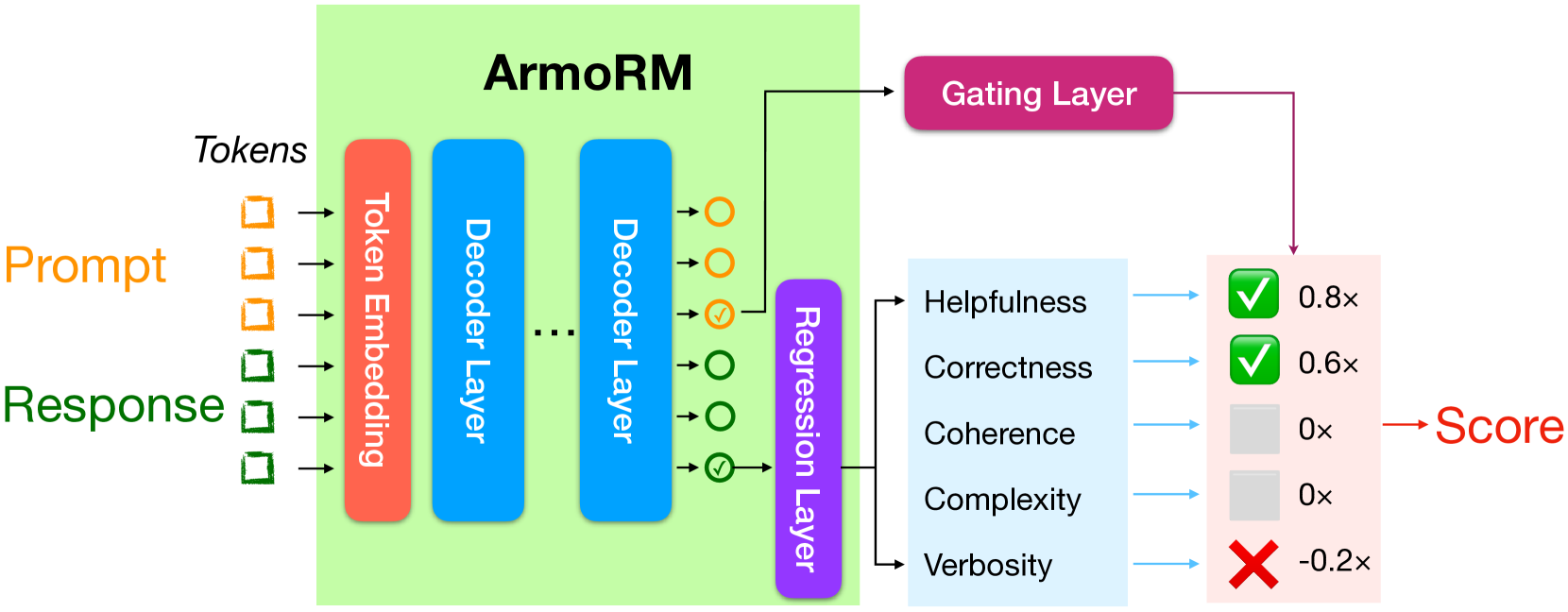
0
Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts
Haoxiang Wang, Wei Xiong, Tengyang Xie, Han Zhao, Tong Zhang
Reinforcement learning from human feedback (RLHF) has emerged as the primary method for aligning large language models (LLMs) with human preferences. The RLHF process typically starts by training a reward model (RM) using human preference data. Conventional RMs are trained on pairwise responses to the same user request, with relative ratings indicating which response humans prefer. The trained RM serves as a proxy for human preferences. However, due to the black-box nature of RMs, their outputs lack interpretability, as humans cannot intuitively understand why an RM thinks a response is good or not. As RMs act as human preference proxies, we believe they should be human-interpretable to ensure that their internal decision processes are consistent with human preferences and to prevent reward hacking in LLM alignment. To build RMs with interpretable preferences, we propose a two-stage approach: i) train an Absolute-Rating Multi-Objective Reward Model (ArmoRM) with multi-dimensional absolute-rating data, each dimension corresponding to a human-interpretable objective (e.g., honesty, verbosity, safety); ii) employ a Mixture-of-Experts (MoE) strategy with a gating network that automatically selects the most suitable reward objectives based on the context. We efficiently trained an ArmoRM with Llama-3 8B and a gating network consisting of a shallow MLP on top of the ArmoRM. Our trained model, ArmoRM-Llama3-8B, obtains state-of-the-art performance on RewardBench, a benchmark evaluating RMs for language modeling. Notably, the performance of our model surpasses the LLM-as-a-judge method with GPT-4 judges by a margin, and approaches the performance of the much larger Nemotron-4 340B reward model.
Read more6/19/2024