$texttt{MoE-RBench}$: Towards Building Reliable Language Models with Sparse Mixture-of-Experts

0

Sign in to get full access
Overview
- The paper introduces MoE-RBench, a benchmark for evaluating the reliability of Mixture-of-Experts (MoE) language models.
- MoE models are a type of large language model that use a "sparse" architecture, where only a subset of specialized "expert" networks are activated for each input.
- The goal of MoE-RBench is to assess the robustness and consistency of MoE models, as well as provide guidelines for building more reliable large language models.
Plain English Explanation
The research paper presents a new benchmark called MoE-RBench that is designed to evaluate the reliability of a type of large language model called a Mixture-of-Experts (MoE) model.
MoE models work differently from traditional large language models. Instead of having a single, monolithic neural network, MoE models have many specialized "expert" networks that each focus on a particular type of task or input. When presented with new information, the MoE model selects which expert network(s) to activate to best handle that input.
The goal of MoE-RBench is to provide a way to rigorously test how consistent and robust these MoE models are. The benchmark aims to assess things like how well the models perform across a diverse range of tasks, how their predictions vary based on different inputs, and how reliable their outputs are overall.
By developing this new evaluation framework, the researchers hope to provide guidance on how to build large language models, like those used for tasks like language translation or text generation, that are more reliable and trustworthy. The hope is that insights from MoE-RBench can lead to the development of better, more robust AI systems.
Technical Explanation
The paper introduces MoE-RBench, a new benchmark for evaluating the reliability of Mixture-of-Experts (MoE) language models. MoE models are a type of large language model that use a "sparse" architecture, where only a subset of specialized "expert" networks are activated for each input, as opposed to a single monolithic network.
The key components of MoE-RBench include:
- A diverse set of evaluation tasks spanning different domains and difficulty levels.
- Metrics to assess the models' consistency, robustness, and performance across these tasks.
- Guidelines for training and evaluating MoE models to improve their reliability.
The paper also presents experimental results using MoE-RBench to analyze several state-of-the-art MoE models, including Toward Inference-Optimal Mixture-of-Experts for Large Language Models, XMOE: Sparse Models for Fine-grained Adaptive Experts, and Uni-MoE: Scaling Unified Multimodal LLMs with Mixture-of-Experts. The analysis highlights the strengths and limitations of these models, providing insights for future research on building more reliable large language models.
Critical Analysis
The MoE-RBench benchmark presents a valuable contribution to the field of large language model development. By providing a comprehensive and rigorous evaluation framework, the researchers aim to address important concerns around the reliability and consistency of MoE models.
However, the paper does acknowledge several limitations and areas for further research. For example, the benchmark currently focuses on textual tasks, and the authors note that extending it to other modalities like vision or multimodal tasks would be an important next step. Additionally, the evaluation metrics used in MoE-RBench, while well-designed, may not capture all facets of model reliability, and there is room for further refinement and validation of these metrics.
Another potential limitation is that the benchmark may not fully account for the inherent trade-offs and design choices involved in building MoE models. For instance, the HyperMoE: Towards Better Mixture-of-Experts via Transferring paper suggests that there can be a tension between model sparsity and performance, which may not be fully reflected in the current MoE-RBench design.
Overall, the MoE-RBench benchmark represents a valuable step forward in the quest to build more reliable and trustworthy large language models. By providing a standardized evaluation framework, the researchers have laid the groundwork for further advancements in this important area of AI research.
Conclusion
The MoE-RBench benchmark introduced in this paper aims to address the critical issue of reliability in Mixture-of-Experts (MoE) language models. By providing a comprehensive evaluation framework, the researchers hope to guide the development of more robust and consistent large language models that can be trusted to perform well across a diverse range of tasks and inputs.
The insights gained from applying MoE-RBench to state-of-the-art MoE models highlight both the strengths and limitations of these approaches, laying the foundation for future research. As the field of large language models continues to evolve, frameworks like MoE-RBench will be crucial for ensuring that these powerful AI systems can be reliably deployed in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
$texttt{MoE-RBench}$: Towards Building Reliable Language Models with Sparse Mixture-of-Experts
Guanjie Chen, Xinyu Zhao, Tianlong Chen, Yu Cheng
Mixture-of-Experts (MoE) has gained increasing popularity as a promising framework for scaling up large language models (LLMs). However, the reliability assessment of MoE lags behind its surging applications. Moreover, when transferred to new domains such as in fine-tuning MoE models sometimes underperform their dense counterparts. Motivated by the research gap and counter-intuitive phenomenon, we propose $texttt{MoE-RBench}$, the first comprehensive assessment of SMoE reliability from three aspects: $textit{(i)}$ safety and hallucination, $textit{(ii)}$ resilience to adversarial attacks, and $textit{(iii)}$ out-of-distribution robustness. Extensive models and datasets are tested to compare the MoE to dense networks from these reliability dimensions. Our empirical observations suggest that with appropriate hyperparameters, training recipes, and inference techniques, we can build the MoE model more reliably than the dense LLM. In particular, we find that the robustness of SMoE is sensitive to the basic training settings. We hope that this study can provide deeper insights into how to adapt the pre-trained MoE model to other tasks with higher-generation security, quality, and stability. Codes are available at https://github.com/UNITES-Lab/MoE-RBench
Read more6/18/2024
0
Dense Training, Sparse Inference: Rethinking Training of Mixture-of-Experts Language Models
Bowen Pan, Yikang Shen, Haokun Liu, Mayank Mishra, Gaoyuan Zhang, Aude Oliva, Colin Raffel, Rameswar Panda
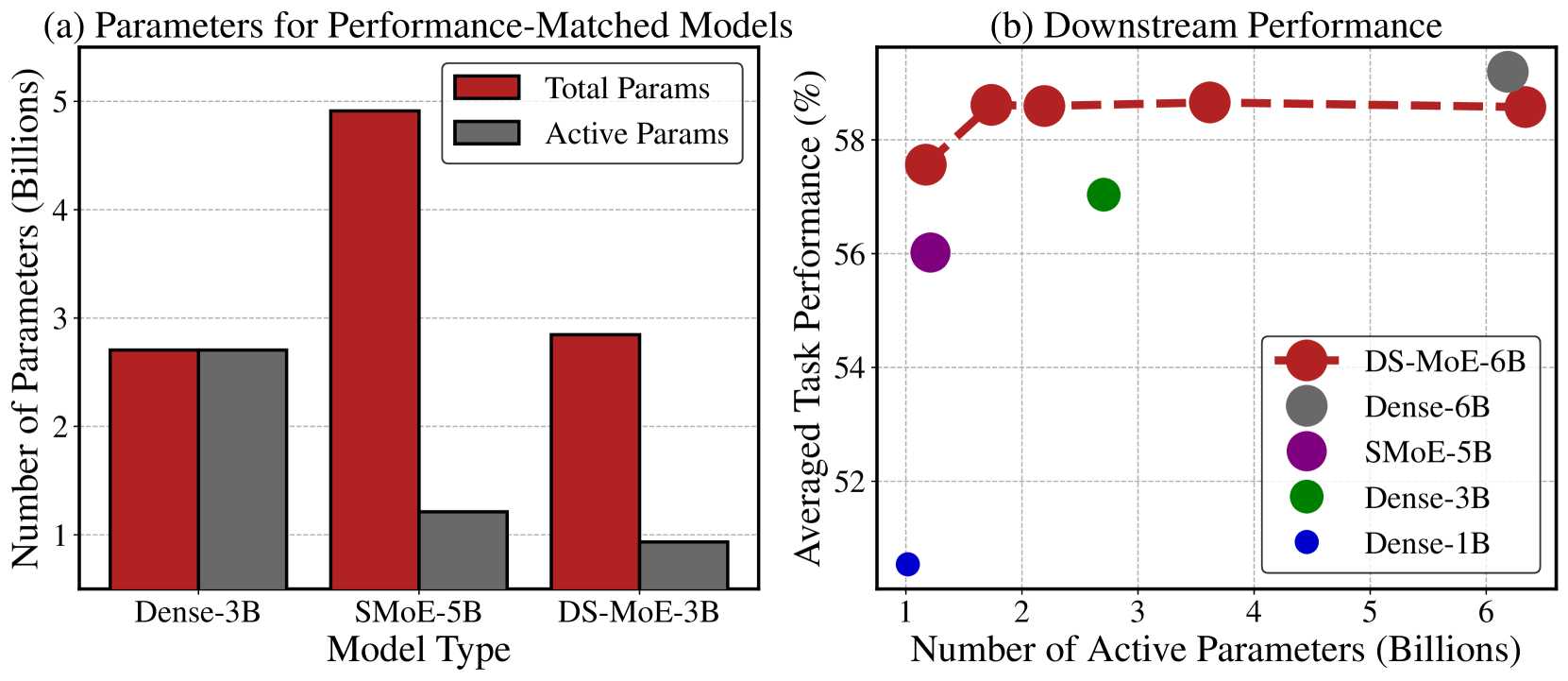
Mixture-of-Experts (MoE) language models can reduce computational costs by 2-4$times$ compared to dense models without sacrificing performance, making them more efficient in computation-bounded scenarios. However, MoE models generally require 2-4$times$ times more parameters to achieve comparable performance to a dense model, which incurs larger GPU memory requirements and makes MoE models less efficient in I/O-bounded scenarios like autoregressive generation. In this work, we propose a hybrid dense training and sparse inference framework for MoE models (DS-MoE) which achieves strong computation and parameter efficiency by employing dense computation across all experts during training and sparse computation during inference. Our experiments on training LLMs demonstrate that our DS-MoE models are more parameter-efficient than standard sparse MoEs and are on par with dense models in terms of total parameter size and performance while being computationally cheaper (activating 30-40% of the model's parameters). Performance tests using vLLM show that our DS-MoE-6B model runs up to $1.86times$ faster than similar dense models like Mistral-7B, and between $1.50times$ and $1.71times$ faster than comparable MoEs, such as DeepSeekMoE-16B and Qwen1.5-MoE-A2.7B.
Read more4/9/2024

0
A Closer Look into Mixture-of-Experts in Large Language Models
Ka Man Lo, Zeyu Huang, Zihan Qiu, Zili Wang, Jie Fu
Mixture-of-experts (MoE) is gaining increasing attention due to its unique properties and remarkable performance, especially for language tasks. By sparsely activating a subset of parameters for each token, MoE architecture could increase the model size without sacrificing computational efficiency, achieving a better trade-off between performance and training costs. However, the underlying mechanism of MoE still lacks further exploration, and its modularization degree remains questionable. In this paper, we make an initial attempt to understand the inner workings of MoE-based large language models. Concretely, we comprehensively study the parametric and behavioral features of three recent MoE-based models and reveal some intriguing observations, including (1) Neurons act like fine-grained experts. (2) The router of MoE usually selects experts with larger output norms. (3) The expert diversity increases as the layer increases, while the last layer is an outlier. Based on the observations, we also provide suggestions for a broad spectrum of MoE practitioners, such as router design and expert allocation. We hope this work could shed light on future research on the MoE framework and other modular architectures. Code is available at https://github.com/kamanphoebe/Look-into-MoEs.
Read more6/27/2024

0
A Survey on Mixture of Experts
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, Jiayi Huang
Large language models (LLMs) have garnered unprecedented advancements across diverse fields, ranging from natural language processing to computer vision and beyond. The prowess of LLMs is underpinned by their substantial model size, extensive and diverse datasets, and the vast computational power harnessed during training, all of which contribute to the emergent abilities of LLMs (e.g., in-context learning) that are not present in small models. Within this context, the mixture of experts (MoE) has emerged as an effective method for substantially scaling up model capacity with minimal computation overhead, gaining significant attention from academia and industry. Despite its growing prevalence, there lacks a systematic and comprehensive review of the literature on MoE. This survey seeks to bridge that gap, serving as an essential resource for researchers delving into the intricacies of MoE. We first briefly introduce the structure of the MoE layer, followed by proposing a new taxonomy of MoE. Next, we overview the core designs for various MoE models including both algorithmic and systemic aspects, alongside collections of available open-source implementations, hyperparameter configurations and empirical evaluations. Furthermore, we delineate the multifaceted applications of MoE in practice, and outline some potential directions for future research. To facilitate ongoing updates and the sharing of cutting-edge developments in MoE research, we have established a resource repository accessible at https://github.com/withinmiaov/A-Survey-on-Mixture-of-Experts.
Read more7/10/2024