Do Large Language Models Understand Conversational Implicature -- A case study with a chinese sitcom

0
💬
Sign in to get full access
Overview
- Introduces SwordsmanImp, a new Chinese multi-turn dialogue dataset focused on conversational implicature
- Tests the ability of large language models (LLMs) to understand and explain implicatures
- Finds that GPT-4 achieves human-level accuracy on multiple-choice questions about implicatures, while other models perform worse
- Reveals that most LLMs struggle to provide satisfactory explanations of the implicatures, except for GPT-4
Plain English Explanation
Conversations involve more than just the literal meaning of the words used. People often imply or suggest things without directly stating them. This concept, known as "conversational implicature," is an important aspect of human-like communication that large language models need to master.
In this study, the researchers created a new dataset called SwordsmanImp, which contains 200 dialogues from a Chinese sitcom. Each dialogue includes a question about the implicature, and the researchers annotated which of the Gricean maxims were violated to create the implicature.
The researchers then tested several popular LLMs, including GPT-4 and GPT-3.5, on two tasks: multiple-choice questions about the implicatures and generating explanations for the implicatures. The results showed that GPT-4 achieved human-level accuracy on the multiple-choice task, while other models performed significantly worse.
However, when it came to explaining the implicatures, most LLMs struggled to provide satisfactory explanations, except for GPT-4. This suggests that while some LLMs can identify implicatures, they have difficulty understanding and articulating the reasoning behind them.
The researchers also found that the LLMs' performance did not vary significantly based on the specific Gricean maxim violated, indicating that they do not seem to process implicatures derived from different maxims differently.
Technical Explanation
The researchers introduced SwordsmanImp, a new Chinese multi-turn dialogue dataset focused on conversational implicature. The dataset was sourced from dialogues in the Chinese sitcom "My Own Swordsman" and includes 200 carefully handcrafted questions, all annotated with the Gricean maxims that were violated to create the implicatures.
The researchers tested eight close-source and open-source LLMs on two tasks: a multiple-choice question task and an implicature explanation task. In the multiple-choice task, the models were asked to select the correct implicature from a set of options. In the explanation task, human raters were asked to evaluate the reasonability, logic, and fluency of the explanations generated by the LLMs.
The results showed that GPT-4 attained human-level accuracy (94%) on the multiple-choice task, while CausalLM demonstrated a 78.5% accuracy, following GPT-4. Other models, including GPT-3.5 and several open-source models, performed significantly worse, with accuracies ranging from 20% to 60%.
However, when it came to generating explanations for the implicatures, the researchers found that while all models produced largely fluent and self-consistent text, their explanations scored low on reasonability, except for GPT-4. This suggests that most LLMs cannot produce satisfactory explanations of the implicatures in the conversational context.
Furthermore, the researchers observed that the LLMs' performance did not vary significantly based on the specific Gricean maxim violated, indicating that the models do not seem to process implicatures derived from different maxims differently.
Critical Analysis
The researchers acknowledge several limitations of their study. First, the dataset is limited to a specific domain (Chinese sitcom dialogues) and may not generalize well to other types of conversations. Additionally, the dataset is relatively small, with only 200 questions, which may not be sufficient to fully capture the complexity of conversational implicature.
Another potential concern is the reliance on human raters to evaluate the quality of the LLMs' explanations. While the researchers attempted to ensure consistency by using multiple raters, human evaluation is inherently subjective and may not provide a completely objective assessment of the models' capabilities.
Furthermore, the study focuses on the performance of LLMs in understanding and explaining implicatures but does not explore their ability to generate implicatures themselves. This could be an important area for future research, as the ability to use implicatures effectively is a key aspect of human-like communication.
Conclusion
This study highlights the importance of understanding conversational implicature for LLMs to become more human-like social communicators. The introduction of the SwordsmanImp dataset and the evaluation of several LLMs on implicature tasks provide valuable insights into the current capabilities and limitations of these models.
The findings suggest that while some LLMs, like GPT-4, can achieve human-level accuracy in identifying implicatures, most struggle to provide satisfactory explanations for the underlying reasoning. This suggests that there is still room for improvement in the field of pragmatic reasoning for large language models.
As the development of LLMs continues, it will be important to focus on enhancing their ability to understand and reason about the nuanced and implicit aspects of human communication, such as conversational implicature. This could lead to more natural and effective interactions between humans and AI systems in a variety of applications, from chatbots to virtual assistants.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Do Large Language Models Understand Conversational Implicature -- A case study with a chinese sitcom
Shisen Yue, Siyuan Song, Xinyuan Cheng, Hai Hu
Understanding the non-literal meaning of an utterance is critical for large language models (LLMs) to become human-like social communicators. In this work, we introduce SwordsmanImp, the first Chinese multi-turn-dialogue-based dataset aimed at conversational implicature, sourced from dialogues in the Chinese sitcom $textit{My Own Swordsman}$. It includes 200 carefully handcrafted questions, all annotated on which Gricean maxims have been violated. We test eight close-source and open-source LLMs under two tasks: a multiple-choice question task and an implicature explanation task. Our results show that GPT-4 attains human-level accuracy (94%) on multiple-choice questions. CausalLM demonstrates a 78.5% accuracy following GPT-4. Other models, including GPT-3.5 and several open-source models, demonstrate a lower accuracy ranging from 20% to 60% on multiple-choice questions. Human raters were asked to rate the explanation of the implicatures generated by LLMs on their reasonability, logic and fluency. While all models generate largely fluent and self-consistent text, their explanations score low on reasonability except for GPT-4, suggesting that most LLMs cannot produce satisfactory explanations of the implicatures in the conversation. Moreover, we find LLMs' performance does not vary significantly by Gricean maxims, suggesting that LLMs do not seem to process implicatures derived from different maxims differently. Our data and code are available at https://github.com/sjtu-compling/llm-pragmatics.
Read more8/1/2024
🤯
0
Pragmatic inference of scalar implicature by LLMs
Ye-eun Cho, Seong mook Kim
This study investigates how Large Language Models (LLMs), particularly BERT (Devlin et al., 2019) and GPT-2 (Radford et al., 2019), engage in pragmatic inference of scalar implicature, such as some. Two sets of experiments were conducted using cosine similarity and next sentence/token prediction as experimental methods. The results in experiment 1 showed that, both models interpret some as pragmatic implicature not all in the absence of context, aligning with human language processing. In experiment 2, in which Question Under Discussion (QUD) was presented as a contextual cue, BERT showed consistent performance regardless of types of QUDs, while GPT-2 encountered processing difficulties since a certain type of QUD required pragmatic inference for implicature. The findings revealed that, in terms of theoretical approaches, BERT inherently incorporates pragmatic implicature not all within the term some, adhering to Default model (Levinson, 2000). In contrast, GPT-2 seems to encounter processing difficulties in inferring pragmatic implicature within context, consistent with Context-driven model (Sperber and Wilson, 2002).
Read more8/14/2024
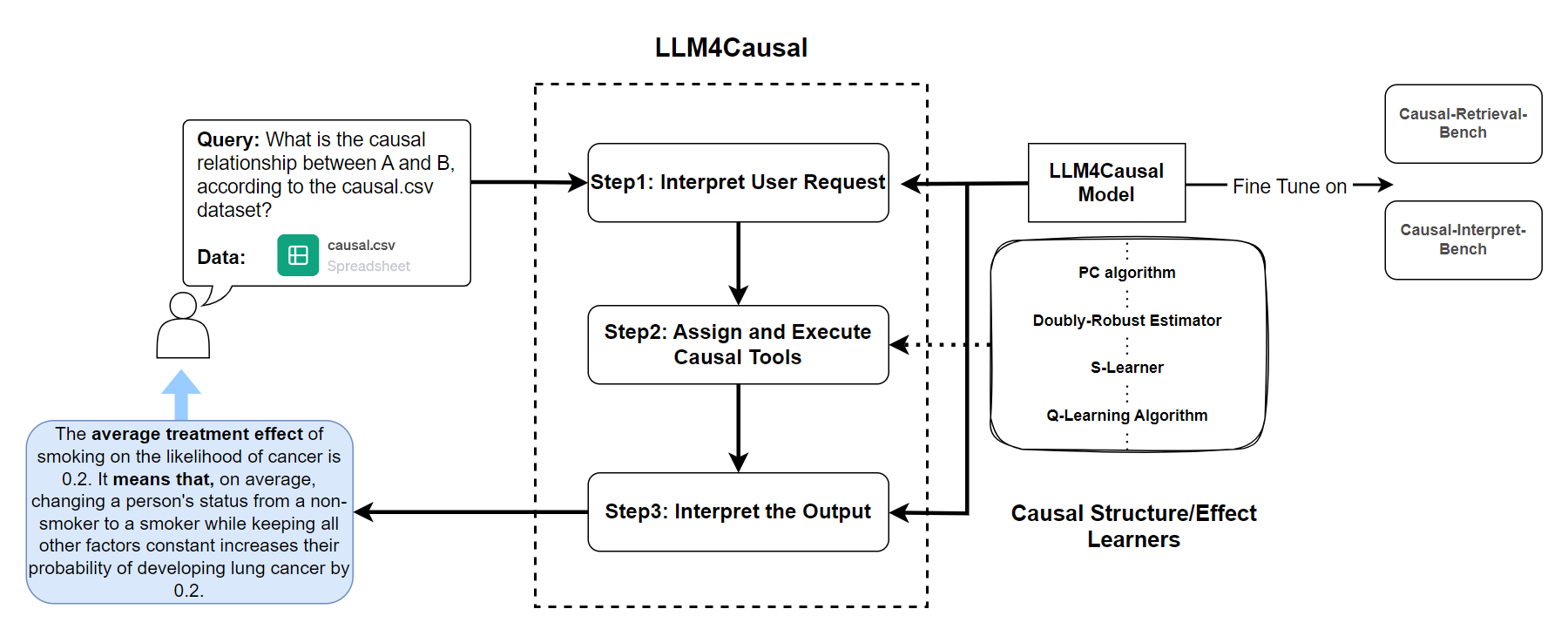
0
Large Language Model for Causal Decision Making
Haitao Jiang, Lin Ge, Yuhe Gao, Jianian Wang, Rui Song
Large Language Models (LLMs) have shown their success in language understanding and reasoning on general topics. However, their capability to perform inference based on user-specified structured data and knowledge in corpus-rare concepts, such as causal decision-making is still limited. In this work, we explore the possibility of fine-tuning an open-sourced LLM into LLM4Causal, which can identify the causal task, execute a corresponding function, and interpret its numerical results based on users' queries and the provided dataset. Meanwhile, we propose a data generation process for more controllable GPT prompting and present two instruction-tuning datasets: (1) Causal-Retrieval-Bench for causal problem identification and input parameter extraction for causal function calling and (2) Causal-Interpret-Bench for in-context causal interpretation. By conducting end-to-end evaluations and two ablation studies, we showed that LLM4Causal can deliver end-to-end solutions for causal problems and provide easy-to-understand answers, which significantly outperforms the baselines.
Read more4/15/2024

0
Can large language models understand uncommon meanings of common words?
Jinyang Wu, Feihu Che, Xinxin Zheng, Shuai Zhang, Ruihan Jin, Shuai Nie, Pengpeng Shao, Jianhua Tao
Large language models (LLMs) like ChatGPT have shown significant advancements across diverse natural language understanding (NLU) tasks, including intelligent dialogue and autonomous agents. Yet, lacking widely acknowledged testing mechanisms, answering `whether LLMs are stochastic parrots or genuinely comprehend the world' remains unclear, fostering numerous studies and sparking heated debates. Prevailing research mainly focuses on surface-level NLU, neglecting fine-grained explorations. However, such explorations are crucial for understanding their unique comprehension mechanisms, aligning with human cognition, and finally enhancing LLMs' general NLU capacities. To address this gap, our study delves into LLMs' nuanced semantic comprehension capabilities, particularly regarding common words with uncommon meanings. The idea stems from foundational principles of human communication within psychology, which underscore accurate shared understandings of word semantics. Specifically, this paper presents the innovative construction of a Lexical Semantic Comprehension (LeSC) dataset with novel evaluation metrics, the first benchmark encompassing both fine-grained and cross-lingual dimensions. Introducing models of both open-source and closed-source, varied scales and architectures, our extensive empirical experiments demonstrate the inferior performance of existing models in this basic lexical-meaning understanding task. Notably, even the state-of-the-art LLMs GPT-4 and GPT-3.5 lag behind 16-year-old humans by 3.9% and 22.3%, respectively. Additionally, multiple advanced prompting techniques and retrieval-augmented generation are also introduced to help alleviate this trouble, yet limitations persist. By highlighting the above critical shortcomings, this research motivates further investigation and offers novel insights for developing more intelligent LLMs.
Read more5/10/2024