Do LLM Agents Have Regret? A Case Study in Online Learning and Games

0
Sign in to get full access
Overview
- This paper explores the concept of regret in large language model (LLM) agents that learn through online interactions and games.
- It investigates whether LLM agents, which are often used in decision-making and game-playing applications, can experience regret over their past actions and decisions.
- The paper presents a case study that examines the regret-related behaviors of LLM agents in various online learning and game scenarios.
Plain English Explanation
In this paper, the researchers are interested in understanding whether large language models (LLMs) - the powerful AI systems that can understand and generate human language - can feel a sense of regret over their past actions or decisions. Regret is the feeling we get when we realize we made a mistake or wish we had done something differently.
The researchers set up different scenarios, like online learning tasks and game-playing environments, to see how LLM agents would behave. They wanted to see if the LLM agents would exhibit behaviors that suggest they are experiencing regret, like trying to correct their past mistakes or make different choices going forward. This builds on previous research on using LLMs as game agents and for policy training. It also relates to work on using LLMs to help with problem-solving and decision-making.
The key question the researchers are trying to answer is whether LLM agents, which are designed to learn and make decisions, can actually develop a sense of regret, just like humans do. Understanding this could have important implications for how we design and use these powerful AI systems, especially in high-stakes decision-making scenarios.
Technical Explanation
The paper presents a case study that examines the regret-related behaviors of LLM agents in various online learning and game scenarios. [This builds on previous work on provable interactive learning with hindsight instruction and feedback and reinforcement learning for problem-solving with large language models.]
The researchers designed experiments where LLM agents were tasked with making decisions in various interactive environments, such as multi-armed bandit problems and Markov decision processes. They then analyzed the agents' behaviors to look for signs of regret, such as:
- Changing their decision-making strategies after experiencing negative outcomes
- Expressing a desire to "undo" or "correct" their past actions
- Exhibiting heightened emotional responses (e.g., disappointment, self-criticism) when faced with suboptimal outcomes
The key findings from the case study suggest that LLM agents can indeed exhibit regret-like behaviors, particularly in scenarios where they have the opportunity to learn from their mistakes and adjust their decision-making accordingly. The researchers also identified factors, such as the degree of feedback and the complexity of the environment, that seem to influence the emergence of regret-related behaviors in the LLM agents.
Critical Analysis
The paper provides an interesting case study on the potential for regret-related behaviors in LLM agents, but it also acknowledges several limitations and areas for further research.
One limitation is that the experiments were conducted in relatively simple, controlled environments, and it's unclear how the findings would scale to more complex, real-world decision-making scenarios. The researchers suggest that further studies are needed to understand how LLM agents might exhibit regret in more realistic and challenging settings.
Additionally, the paper does not delve deeply into the underlying mechanisms or cognitive processes that might lead to regret-like behaviors in LLM agents. It would be valuable for future research to explore the specific architectural features, training approaches, or other factors that contribute to the emergence of regret in these systems.
Another potential concern is the ethical implications of LLM agents potentially experiencing regret. If these systems can indeed feel regret, it raises questions about their moral status and the responsibilities we might have in designing and deploying them, especially in high-stakes decision-making contexts.
Overall, this paper presents an important step in understanding the complex cognitive and emotional capabilities of LLM agents, and it highlights the need for continued research in this area to fully grasp the implications of these powerful AI systems.
Conclusion
This paper explores the fascinating question of whether large language model (LLM) agents, which are increasingly being used in decision-making and game-playing applications, can experience a sense of regret over their past actions and decisions. Through a case study examining LLM agents in various online learning and game scenarios, the researchers found evidence that these systems can exhibit regret-like behaviors, such as adjusting their decision-making strategies in response to negative outcomes.
While this research is an important step forward, it also raises additional questions and highlights the need for further investigation into the cognitive and emotional capabilities of LLM agents. As these powerful AI systems become more prominent in high-stakes decision-making contexts, understanding their potential for regret and other human-like experiences will be crucial for ensuring their safe and ethical deployment. This paper lays the groundwork for continued exploration of the complex inner workings of LLM agents and their implications for the future of AI-powered decision-making.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Do LLM Agents Have Regret? A Case Study in Online Learning and Games
Chanwoo Park, Xiangyu Liu, Asuman Ozdaglar, Kaiqing Zhang
Large language models (LLMs) have been increasingly employed for (interactive) decision-making, via the development of LLM-based autonomous agents. Despite their emerging successes, the performance of LLM agents in decision-making has not been fully investigated through quantitative metrics, especially in the multi-agent setting when they interact with each other, a typical scenario in real-world LLM-agent applications. To better understand the limits of LLM agents in these interactive environments, we propose to study their interactions in benchmark decision-making settings in online learning and game theory, through the performance metric of emph{regret}. We first empirically study the {no-regret} behaviors of LLMs in canonical (non-stationary) online learning problems, as well as the emergence of equilibria when LLM agents interact through playing repeated games. We then provide some theoretical insights into the no-regret behaviors of LLM agents, under certain assumptions on the supervised pre-training and the rationality model of human decision-makers who generate the data. Notably, we also identify (simple) cases where advanced LLMs such as GPT-4 fail to be no-regret. To promote the no-regret behaviors, we propose a novel emph{unsupervised} training loss of emph{regret-loss}, which, in contrast to the supervised pre-training loss, does not require the labels of (optimal) actions. We then establish the statistical guarantee of generalization bound for regret-loss minimization, followed by the optimization guarantee that minimizing such a loss may automatically lead to known no-regret learning algorithms. Our further experiments demonstrate the effectiveness of our regret-loss, especially in addressing the above ``regrettable'' cases.
Read more5/28/2024
0
How Far Are We on the Decision-Making of LLMs? Evaluating LLMs' Gaming Ability in Multi-Agent Environments
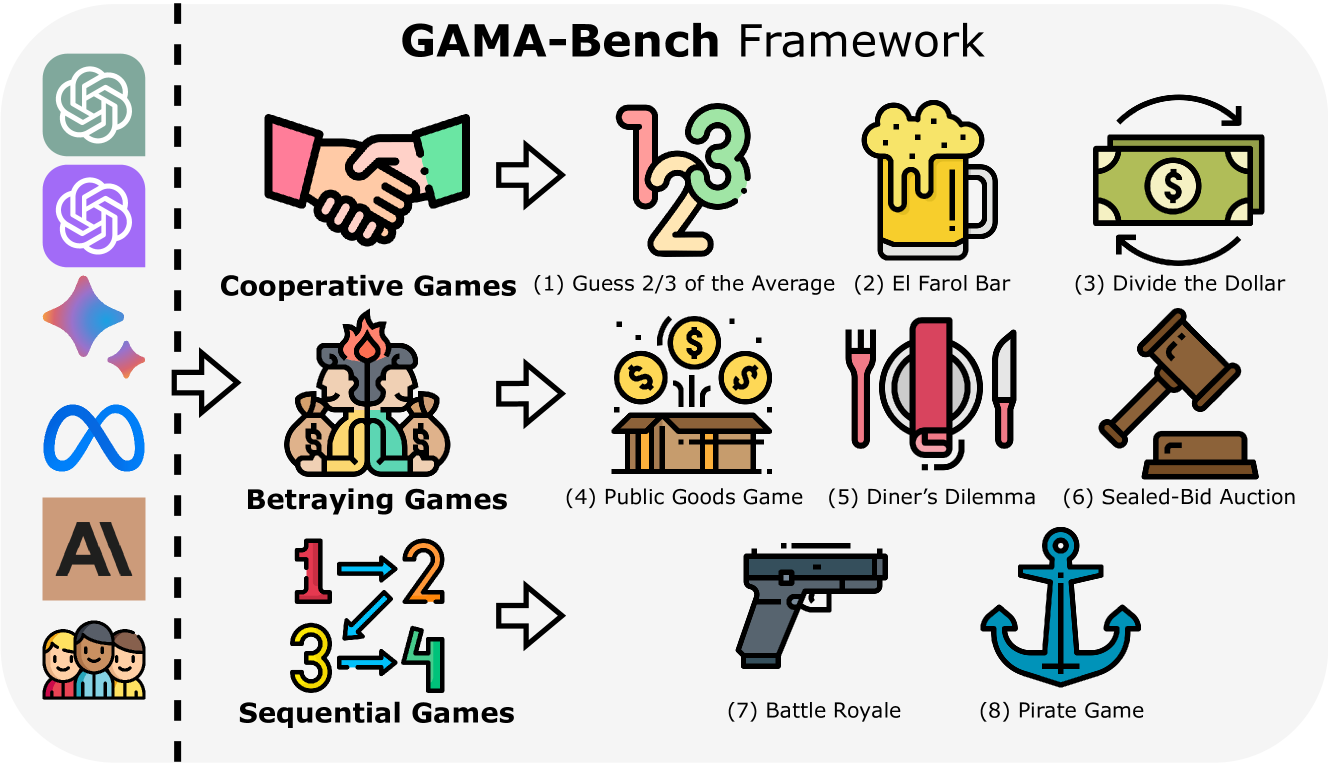
Jen-tse Huang, Eric John Li, Man Ho Lam, Tian Liang, Wenxuan Wang, Youliang Yuan, Wenxiang Jiao, Xing Wang, Zhaopeng Tu, Michael R. Lyu
Decision-making is a complex process requiring diverse abilities, making it an excellent framework for evaluating Large Language Models (LLMs). Researchers have examined LLMs' decision-making through the lens of Game Theory. However, existing evaluation mainly focus on two-player scenarios where an LLM competes against another. Additionally, previous benchmarks suffer from test set leakage due to their static design. We introduce GAMA($gamma$)-Bench, a new framework for evaluating LLMs' Gaming Ability in Multi-Agent environments. It includes eight classical game theory scenarios and a dynamic scoring scheme specially designed to quantitatively assess LLMs' performance. $gamma$-Bench allows flexible game settings and adapts the scoring system to different game parameters, enabling comprehensive evaluation of robustness, generalizability, and strategies for improvement. Our results indicate that GPT-3.5 demonstrates strong robustness but limited generalizability, which can be enhanced using methods like Chain-of-Thought. We also evaluate twelve LLMs from six model families, including GPT-3.5, GPT-4, Gemini, LLaMA-3.1, Mixtral, and Qwen-2. Gemini-1.5-Pro outperforms others, scoring of $68.1$ out of $100$, followed by LLaMA-3.1-70B ($64.5$) and Mixtral-8x22B ($61.4$). All code and experimental results are publicly available via https://github.com/CUHK-ARISE/GAMABench.
Read more10/2/2024
0
From Words to Actions: Unveiling the Theoretical Underpinnings of LLM-Driven Autonomous Systems
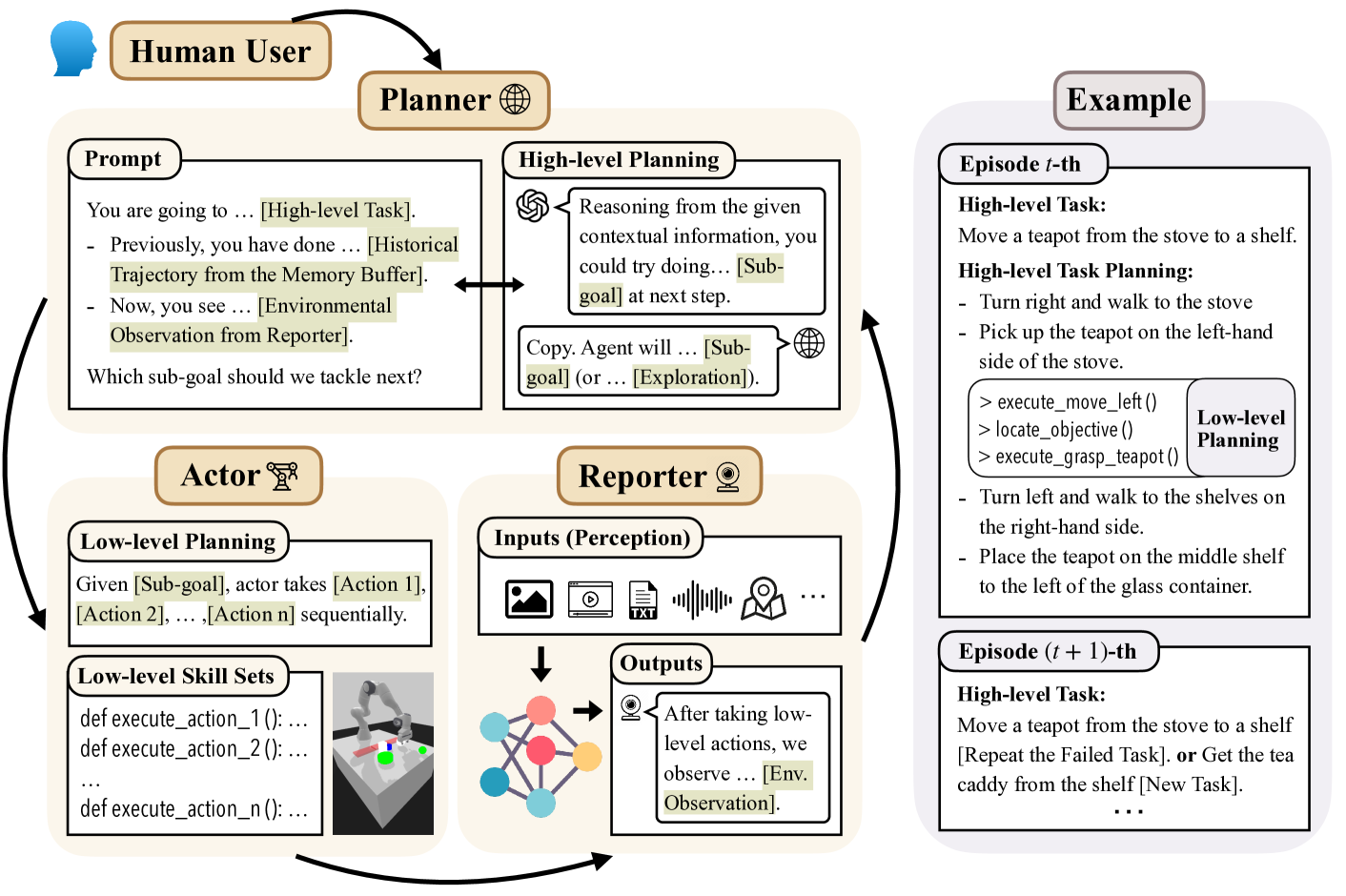
Jianliang He, Siyu Chen, Fengzhuo Zhang, Zhuoran Yang
In this work, from a theoretical lens, we aim to understand why large language model (LLM) empowered agents are able to solve decision-making problems in the physical world. To this end, consider a hierarchical reinforcement learning (RL) model where the LLM Planner and the Actor perform high-level task planning and low-level execution, respectively. Under this model, the LLM Planner navigates a partially observable Markov decision process (POMDP) by iteratively generating language-based subgoals via prompting. Under proper assumptions on the pretraining data, we prove that the pretrained LLM Planner effectively performs Bayesian aggregated imitation learning (BAIL) through in-context learning. Additionally, we highlight the necessity for exploration beyond the subgoals derived from BAIL by proving that naively executing the subgoals returned by LLM leads to a linear regret. As a remedy, we introduce an $epsilon$-greedy exploration strategy to BAIL, which is proven to incur sublinear regret when the pretraining error is small. Finally, we extend our theoretical framework to include scenarios where the LLM Planner serves as a world model for inferring the transition model of the environment and to multi-agent settings, enabling coordination among multiple Actors.
Read more7/23/2024

0
Multi-Agent Imitation Learning: Value is Easy, Regret is Hard
Jingwu Tang, Gokul Swamy, Fei Fang, Zhiwei Steven Wu
We study a multi-agent imitation learning (MAIL) problem where we take the perspective of a learner attempting to coordinate a group of agents based on demonstrations of an expert doing so. Most prior work in MAIL essentially reduces the problem to matching the behavior of the expert within the support of the demonstrations. While doing so is sufficient to drive the value gap between the learner and the expert to zero under the assumption that agents are non-strategic, it does not guarantee robustness to deviations by strategic agents. Intuitively, this is because strategic deviations can depend on a counterfactual quantity: the coordinator's recommendations outside of the state distribution their recommendations induce. In response, we initiate the study of an alternative objective for MAIL in Markov Games we term the regret gap that explicitly accounts for potential deviations by agents in the group. We first perform an in-depth exploration of the relationship between the value and regret gaps. First, we show that while the value gap can be efficiently minimized via a direct extension of single-agent IL algorithms, even value equivalence can lead to an arbitrarily large regret gap. This implies that achieving regret equivalence is harder than achieving value equivalence in MAIL. We then provide a pair of efficient reductions to no-regret online convex optimization that are capable of minimizing the regret gap (a) under a coverage assumption on the expert (MALICE) or (b) with access to a queryable expert (BLADES).
Read more6/27/2024