Dual Thinking and Perceptual Analysis of Deep Learning Models using Human Adversarial Examples

0

Sign in to get full access
Overview
- This paper explores the use of "human adversarial examples" to analyze the inner workings of deep learning models and their perceptual processes.
- The researchers investigate how deep learning models respond to inputs that humans perceive as natural but that confuse the models, revealing insights about their decision-making.
- The paper builds on previous research on adversarial examples and active vision systems, and proposes a "dual thinking" approach to study the divergence between human and machine perception.
Plain English Explanation
Deep learning models, like the ones used in many modern AI systems, can sometimes make mistakes that seem bizarre or counterintuitive to humans. For example, a model trained to recognize images might misidentify a picture that looks completely normal to us.
The researchers in this paper wanted to explore this phenomenon more deeply. They created "human adversarial examples" - images that look natural to people but confuse deep learning models. By studying how the models respond to these examples, the researchers hoped to gain insights into the internal decision-making processes of the models and how they differ from human perception.
This builds on previous work on adversarial examples and active vision systems that has shown how small, imperceptible changes to inputs can dramatically alter a model's predictions. The researchers here add a "dual thinking" approach, comparing the model's responses to what a human would perceive.
By understanding these divergences between human and machine perception, the researchers aim to shed light on the inner workings of deep learning models and potentially improve their robustness and reliability. This could have important implications for applications like computer vision and active vision systems.
Technical Explanation
The paper proposes a "dual thinking" framework for analyzing deep learning models using human adversarial examples. The researchers first collected a dataset of images that humans perceive as natural but that confuse state-of-the-art image classification models.
They then conducted a series of experiments to study how these human adversarial examples affect the internal representations and decision-making processes of the deep learning models. This included probing the models' attention maps, feature activations, and confidence scores to understand what cues the models were using to make their classifications.
The results showed significant divergences between human and machine perception, with the models often focusing on subtle low-level features that humans do not consciously perceive as salient. The researchers argue that this "dual thinking" approach reveals important insights about the inner workings of deep learning and can inform efforts to improve model robustness and interpretability.
Critical Analysis
The researchers acknowledge several limitations of their work. First, the dataset of human adversarial examples is relatively small, and more extensive testing would be needed to fully generalize the findings. Additionally, the analysis is focused on image classification models, and it's unclear how the insights would translate to other deep learning applications.
Furthermore, the paper does not delve into the broader ethical and societal implications of these divergences between human and machine perception. As deep learning systems become more ubiquitous, it will be crucial to understand the potential biases and blindspots they may exhibit compared to human decision-making.
Additional research is also needed to explore how these insights could be leveraged to improve model robustness and transparency. The "dual thinking" framework proposed in the paper is a promising step, but more work is needed to develop practical techniques for enhancing the reliability and interpretability of deep learning systems.
Conclusion
This paper presents a novel approach for analyzing deep learning models by studying their responses to "human adversarial examples" - inputs that confuse the models but appear natural to humans. The researchers' "dual thinking" framework reveals significant divergences between machine and human perception, shedding light on the inner workings of these models and the potential limitations of their decision-making processes.
While further research is needed to fully explore the implications of these findings, this work represents an important step towards enhancing the robustness, transparency, and trustworthiness of deep learning systems. As AI continues to pervade more aspects of our lives, understanding and addressing these human-machine perceptual gaps will be crucial for ensuring the responsible and ethical development of these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dual Thinking and Perceptual Analysis of Deep Learning Models using Human Adversarial Examples
Kailas Dayanandan, Anand Sinha, Brejesh Lall
The dual thinking framework considers fast, intuitive processing and slower, logical processing. The perception of dual thinking in vision requires images where inferences from intuitive and logical processing differ. We introduce an adversarial dataset to provide evidence for the dual thinking framework in human vision, which also aids in studying the qualitative behavior of deep learning models. Our study also addresses a major criticism of using classification models as computational models of human vision by using instance segmentation models that localize objects. The evidence underscores the importance of shape in identifying instances in human vision and shows that deep learning models lack an understanding of sub-structures, as indicated by errors related to the position and number of sub-components. Additionally, the similarity in errors made by models and intuitive human processing indicates that models only address intuitive thinking in human vision.
Read more6/12/2024
🤿
0
On the Similarity of Deep Learning Representations Across Didactic and Adversarial Examples
Pk Douglas, Farzad Vasheghani Farahani
The increasing use of deep neural networks (DNNs) has motivated a parallel endeavor: the design of adversaries that profit from successful misclassifications. However, not all adversarial examples are crafted for malicious purposes. For example, real world systems often contain physical, temporal, and sampling variability across instrumentation. Adversarial examples in the wild may inadvertently prove deleterious for accurate predictive modeling. Conversely, naturally occurring covariance of image features may serve didactic purposes. Here, we studied the stability of deep learning representations for neuroimaging classification across didactic and adversarial conditions characteristic of MRI acquisition variability. We show that representational similarity and performance vary according to the frequency of adversarial examples in the input space.
Read more9/18/2024

0
Having Second Thoughts? Let's hear it
Jung H. Lee, Sujith Vijayan
Deep learning models loosely mimic bottom-up signal pathways from low-order sensory areas to high-order cognitive areas. After training, DL models can outperform humans on some domain-specific tasks, but their decision-making process has been known to be easily disrupted. Since the human brain consists of multiple functional areas highly connected to one another and relies on intricate interplays between bottom-up and top-down (from high-order to low-order areas) processing, we hypothesize that incorporating top-down signal processing may make DL models more robust. To address this hypothesis, we propose a certification process mimicking selective attention and test if it could make DL models more robust. Our empirical evaluations suggest that this newly proposed certification can improve DL models' accuracy and help us build safety measures to alleviate their vulnerabilities with both artificial and natural adversarial examples.
Read more6/3/2024
0
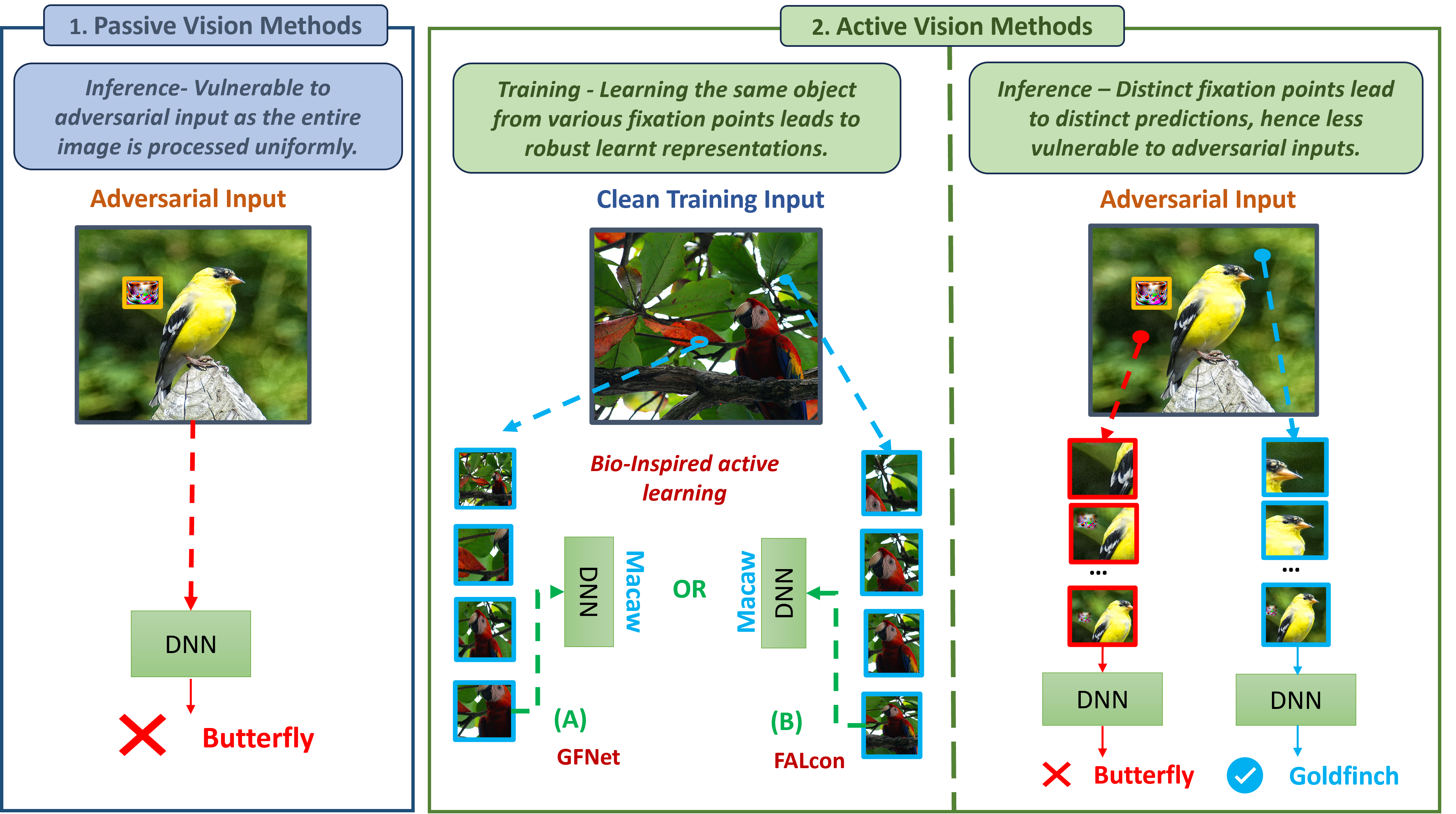
On Inherent Adversarial Robustness of Active Vision Systems
Amitangshu Mukherjee, Timur Ibrayev, Kaushik Roy
Current Deep Neural Networks are vulnerable to adversarial examples, which alter their predictions by adding carefully crafted noise. Since human eyes are robust to such inputs, it is possible that the vulnerability stems from the standard way of processing inputs in one shot by processing every pixel with the same importance. In contrast, neuroscience suggests that the human vision system can differentiate salient features by (1) switching between multiple fixation points (saccades) and (2) processing the surrounding with a non-uniform external resolution (foveation). In this work, we advocate that the integration of such active vision mechanisms into current deep learning systems can offer robustness benefits. Specifically, we empirically demonstrate the inherent robustness of two active vision methods - GFNet and FALcon - under a black box threat model. By learning and inferencing based on downsampled glimpses obtained from multiple distinct fixation points within an input, we show that these active methods achieve (2-3) times greater robustness compared to a standard passive convolutional network under state-of-the-art adversarial attacks. More importantly, we provide illustrative and interpretable visualization analysis that demonstrates how performing inference from distinct fixation points makes active vision methods less vulnerable to malicious inputs.
Read more4/8/2024