Learning Robust 3D Representation from CLIP via Dual Denoising

0

Sign in to get full access
Overview
- This paper presents a method called "Dual Denoising" that learns a robust 3D representation from the CLIP (Contrastive Language-Image Pre-training) model.
- The key idea is to use two denoising tasks - one for visual and one for language modalities - to jointly train the model, leading to more robust 3D representation learning.
- The approach is evaluated on various 3D understanding tasks and shows improvements over prior CLIP-based methods, such as DuoDuo, DiffCLIP, and Can-CLIP.
Plain English Explanation
The paper introduces a new way to train AI models to understand 3D shapes and objects. The key idea is to use two "denoising" tasks - one for images and one for text - to jointly train the model. This joint training helps the model learn a more robust and reliable 3D representation.
The model is based on the CLIP (Contrastive Language-Image Pre-training) system, which is a powerful AI that can match images and text. The authors' approach, called "Dual Denoising", builds on CLIP by adding these two denoising tasks during training.
The denoising tasks involve taking corrupted or "noisy" data (either images or text) and training the model to reconstruct the original, clean data. By learning to denoise both images and text simultaneously, the model develops a deeper, more reliable understanding of the 3D world.
The paper shows that this Dual Denoising approach outperforms previous CLIP-based methods, such as DuoDuo, DiffCLIP, and Can-CLIP, on various 3D understanding tasks. This suggests that the joint denoising approach is an effective way to extract more robust 3D knowledge from the CLIP model.
Technical Explanation
The key contribution of this paper is the "Dual Denoising" approach for learning robust 3D representations from the CLIP model. The authors hypothesize that by incorporating two denoising tasks - one for visual and one for language modalities - the model can develop a more reliable understanding of 3D shapes and objects.
The visual denoising task involves taking an image and training the model to reconstruct the original, clean image from a corrupted or "noisy" version. The language denoising task does the same thing but for text - the model must reconstruct clean text from noisy text. By learning these two denoising tasks simultaneously, the model is encouraged to develop a deeper, more robust multimodal understanding.
The authors integrate these denoising tasks into the CLIP architecture, which is a powerful pre-trained model for aligning images and text. They show that this Dual Denoising approach outperforms prior CLIP-based methods, such as DuoDuo, DiffCLIP, and Can-CLIP, on a variety of 3D understanding tasks.
Critical Analysis
The paper provides a novel and promising approach for learning robust 3D representations from the CLIP model. The key strength is the joint training of visual and language denoising tasks, which seems to imbue the model with a more reliable multimodal understanding of the 3D world.
However, the paper does not extensively explore the limitations of this approach. For example, it would be valuable to understand how the model's performance scales with the amount of training data, or how it might be affected by biases in the pre-trained CLIP model. Additionally, the authors could have compared their method to a broader range of baselines, such as Dual Image Enhanced CLIP or Robust CLIP, to more comprehensively evaluate its strengths and weaknesses.
Overall, the Dual Denoising approach is a promising step forward in leveraging CLIP for robust 3D understanding, but further research is needed to fully understand its capabilities and limitations.
Conclusion
This paper presents a novel method called "Dual Denoising" that learns robust 3D representations from the CLIP model. The key idea is to jointly train the model on two denoising tasks - one for visual and one for language modalities - which helps the model develop a more reliable multimodal understanding of 3D shapes and objects.
The authors show that this Dual Denoising approach outperforms previous CLIP-based methods on various 3D understanding tasks, suggesting it is an effective way to extract more robust 3D knowledge from the CLIP model. While the paper provides a valuable contribution, further research is needed to fully explore the capabilities and limitations of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Robust 3D Representation from CLIP via Dual Denoising
Shuqing Luo, Bowen Qu, Wei Gao
In this paper, we explore a critical yet under-investigated issue: how to learn robust and well-generalized 3D representation from pre-trained vision language models such as CLIP. Previous works have demonstrated that cross-modal distillation can provide rich and useful knowledge for 3D data. However, like most deep learning models, the resultant 3D learning network is still vulnerable to adversarial attacks especially the iterative attack. In this work, we propose Dual Denoising, a novel framework for learning robust and well-generalized 3D representations from CLIP. It combines a denoising-based proxy task with a novel feature denoising network for 3D pre-training. Additionally, we propose utilizing parallel noise inference to enhance the generalization of point cloud features under cross domain settings. Experiments show that our model can effectively improve the representation learning performance and adversarial robustness of the 3D learning network under zero-shot settings without adversarial training. Our code is available at https://github.com/luoshuqing2001/Dual_Denoising.
Read more7/2/2024
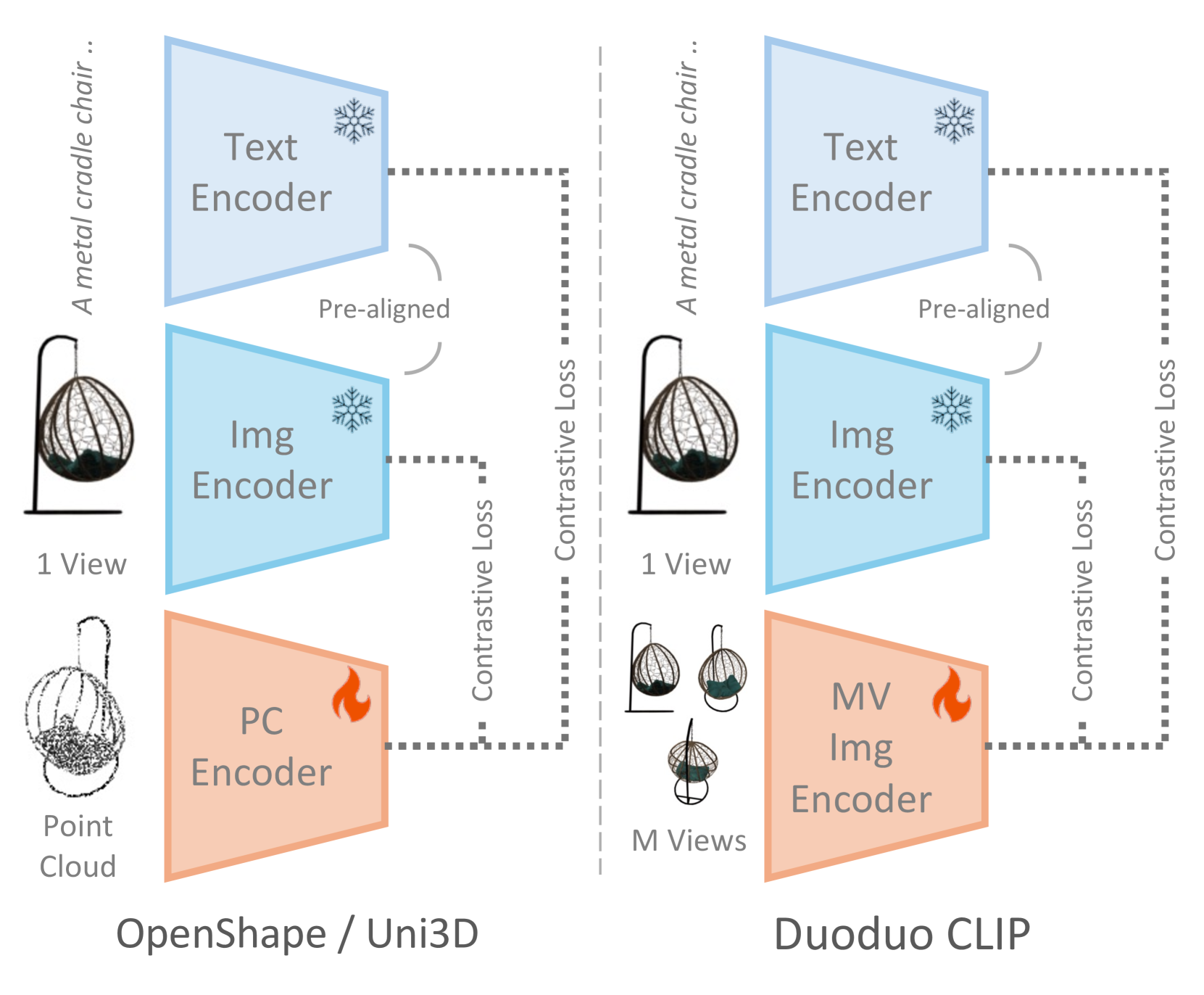
0
Duoduo CLIP: Efficient 3D Understanding with Multi-View Images
Han-Hung Lee, Yiming Zhang, Angel X. Chang
We introduce Duoduo CLIP, a model for 3D representation learning that learns shape encodings from multi-view images instead of point-clouds. The choice of multi-view images allows us to leverage 2D priors from off-the-shelf CLIP models to facilitate fine-tuning with 3D data. Our approach not only shows better generalization compared to existing point cloud methods, but also reduces GPU requirements and training time. In addition, we modify the model with cross-view attention to leverage information across multiple frames of the object which further boosts performance. Compared to the current SOTA point cloud method that requires 480 A100 hours to train 1 billion model parameters we only require 57 A5000 hours and 87 million parameters. Multi-view images also provide more flexibility in use cases compared to point clouds. This includes being able to encode objects with a variable number of images, with better performance when more views are used. This is in contrast to point cloud based methods, where an entire scan or model of an object is required. We showcase this flexibility with object retrieval from images of real-world objects. Our model also achieves better performance in more fine-grained text to shape retrieval, demonstrating better text-and-shape alignment than point cloud based models.
Read more6/18/2024
💬
0
DiffCLIP: Leveraging Stable Diffusion for Language Grounded 3D Classification
Sitian Shen, Zilin Zhu, Linqian Fan, Harry Zhang, Xinxiao Wu
Large pre-trained models have had a significant impact on computer vision by enabling multi-modal learning, where the CLIP model has achieved impressive results in image classification, object detection, and semantic segmentation. However, the model's performance on 3D point cloud processing tasks is limited due to the domain gap between depth maps from 3D projection and training images of CLIP. This paper proposes DiffCLIP, a new pre-training framework that incorporates stable diffusion with ControlNet to minimize the domain gap in the visual branch. Additionally, a style-prompt generation module is introduced for few-shot tasks in the textual branch. Extensive experiments on the ModelNet10, ModelNet40, and ScanObjectNN datasets show that DiffCLIP has strong abilities for 3D understanding. By using stable diffusion and style-prompt generation, DiffCLIP achieves an accuracy of 43.2% for zero-shot classification on OBJ_BG of ScanObjectNN, which is state-of-the-art performance, and an accuracy of 80.6% for zero-shot classification on ModelNet10, which is comparable to state-of-the-art performance.
Read more5/7/2024

0
Can CLIP help CLIP in learning 3D?
Cristian Sbrolli, Matteo Matteucci
In this study, we explore an alternative approach to enhance contrastive text-image-3D alignment in the absence of textual descriptions for 3D objects. We introduce two unsupervised methods, $I2I$ and $(I2L)^2$, which leverage CLIP knowledge about textual and 2D data to compute the neural perceived similarity between two 3D samples. We employ the proposed methods to mine 3D hard negatives, establishing a multimodal contrastive pipeline with hard negative weighting via a custom loss function. We train on different configurations of the proposed hard negative mining approach, and we evaluate the accuracy of our models in 3D classification and on the cross-modal retrieval benchmark, testing image-to-shape and shape-to-image retrieval. Results demonstrate that our approach, even without explicit text alignment, achieves comparable or superior performance on zero-shot and standard 3D classification, while significantly improving both image-to-shape and shape-to-image retrieval compared to previous methods.
Read more9/10/2024