CLIP3D-AD: Extending CLIP for 3D Few-Shot Anomaly Detection with Multi-View Images Generation

0
Sign in to get full access
Overview
- This paper presents CLIP3D-AD, a novel approach for 3D few-shot anomaly detection that extends the popular CLIP (Contrastive Language-Image Pre-training) model.
- CLIP3D-AD leverages multi-view images generated from 3D models to enable few-shot learning for anomaly detection in industrial manufacturing settings.
- The proposed method outperforms existing 3D anomaly detection techniques, particularly in scenarios with limited training data.
Plain English Explanation
The paper describes a new technique called CLIP3D-AD that aims to improve the detection of anomalies or problems in 3D industrial objects, even when there is limited training data available. Anomaly detection is important in manufacturing, where defects or issues need to be identified quickly.
CLIP3D-AD builds on the success of the CLIP model, which has shown impressive abilities to understand the relationship between images and text. The researchers extend CLIP to work with 3D objects by generating multiple 2D views of the 3D models. This allows the model to learn from a small number of examples, rather than needing a large dataset of 3D scans.
The key innovation is that CLIP3D-AD can generate new 2D views of 3D objects, which helps the model learn more from the limited training data available. This makes it more effective at detecting anomalies in 3D industrial parts compared to previous methods, especially when there are only a few examples to learn from.
Technical Explanation
The paper introduces CLIP3D-AD, which extends the popular CLIP model to enable few-shot 3D anomaly detection. CLIP3D-AD leverages multi-view image generation from 3D models to facilitate learning from limited training data, as is common in industrial manufacturing settings.
The authors first pre-train CLIP3D-AD on a large dataset of 3D CAD models and their corresponding multi-view images. This allows the model to learn a joint embedding space that can relate 3D shapes to their visual appearance. During fine-tuning for anomaly detection, the model is trained on a small number of examples of normal and anomalous 3D parts, along with their generated multi-view images.
CLIP3D-AD is evaluated on several 3D anomaly detection benchmarks, including the recently proposed Dual-Image-Enhanced CLIP and DuoDuo-CLIP datasets. The results demonstrate that CLIP3D-AD outperforms existing 3D anomaly detection techniques, particularly in few-shot learning scenarios where only a small number of training examples are available.
The authors also show that CLIP3D-AD can be further improved by leveraging 3D shape information, as explored in related work like Can CLIP Help CLIP and DiffCLIP.
Critical Analysis
The paper presents a promising approach for few-shot 3D anomaly detection, which is an important problem in industrial manufacturing. The key strength of CLIP3D-AD is its ability to learn from limited training data by leveraging multi-view image generation from 3D models.
However, the paper does not address potential limitations of the approach, such as the reliance on having access to high-quality 3D CAD models for pre-training. In many real-world scenarios, such 3D data may not be readily available, which could limit the practicality of CLIP3D-AD.
Additionally, the paper does not provide a detailed analysis of the types of anomalies the model is able to detect or the specific challenges it faces. Further research is needed to understand the limitations and failure modes of CLIP3D-AD, as well as its robustness to different types of 3D defects and manufacturing processes.
Conclusion
The CLIP3D-AD model presents a novel approach to 3D few-shot anomaly detection that builds upon the success of the CLIP model. By leveraging multi-view image generation, the technique can effectively learn from limited training data, making it a promising solution for industrial manufacturing applications.
While the paper demonstrates strong performance on benchmark datasets, further research is needed to address potential limitations and expand the applicability of CLIP3D-AD to more diverse real-world scenarios. Nonetheless, this work represents an important step forward in the field of 3D anomaly detection and highlights the potential of vision-language models like CLIP to tackle challenging industrial problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CLIP3D-AD: Extending CLIP for 3D Few-Shot Anomaly Detection with Multi-View Images Generation
Zuo Zuo, Jiahao Dong, Yao Wu, Yanyun Qu, Zongze Wu
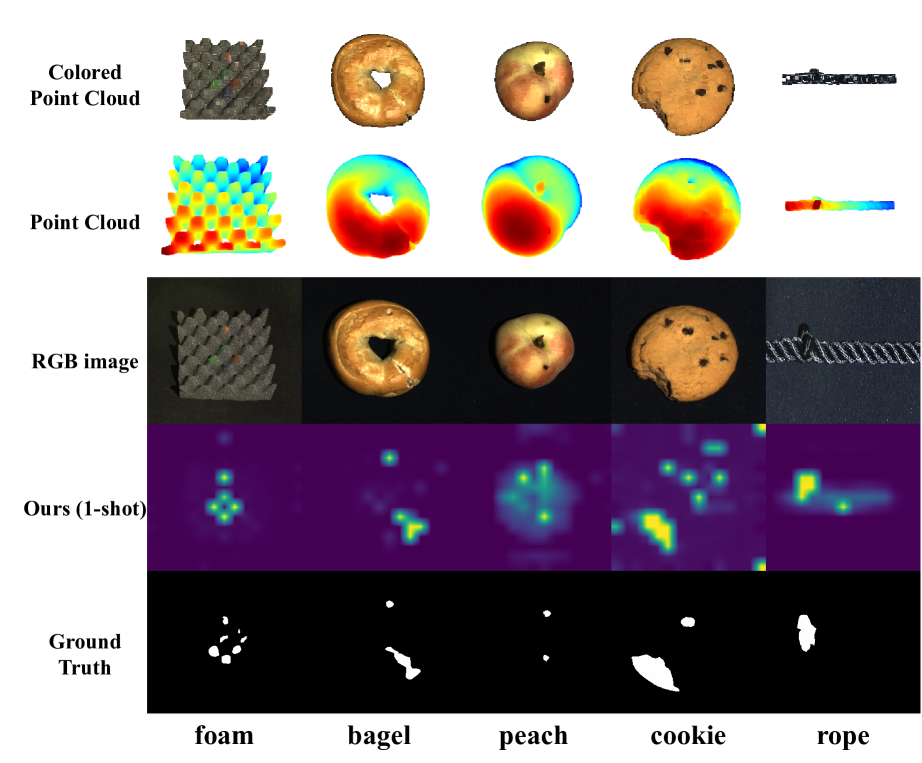
Few-shot anomaly detection methods can effectively address data collecting difficulty in industrial scenarios. Compared to 2D few-shot anomaly detection (2D-FSAD), 3D few-shot anomaly detection (3D-FSAD) is still an unexplored but essential task. In this paper, we propose CLIP3D-AD, an efficient 3D-FSAD method extended on CLIP. We successfully transfer strong generalization ability of CLIP into 3D-FSAD. Specifically, we synthesize anomalous images on given normal images as sample pairs to adapt CLIP for 3D anomaly classification and segmentation. For classification, we introduce an image adapter and a text adapter to fine-tune global visual features and text features. Meanwhile, we propose a coarse-to-fine decoder to fuse and facilitate intermediate multi-layer visual representations of CLIP. To benefit from geometry information of point cloud and eliminate modality and data discrepancy when processed by CLIP, we project and render point cloud to multi-view normal and anomalous images. Then we design multi-view fusion module to fuse features of multi-view images extracted by CLIP which are used to facilitate visual representations for further enhancing vision-language correlation. Extensive experiments demonstrate that our method has a competitive performance of 3D few-shot anomaly classification and segmentation on MVTec-3D AD dataset.
Read more6/28/2024

0
MediCLIP: Adapting CLIP for Few-shot Medical Image Anomaly Detection
Ximiao Zhang, Min Xu, Dehui Qiu, Ruixin Yan, Ning Lang, Xiuzhuang Zhou
In the field of medical decision-making, precise anomaly detection in medical imaging plays a pivotal role in aiding clinicians. However, previous work is reliant on large-scale datasets for training anomaly detection models, which increases the development cost. This paper first focuses on the task of medical image anomaly detection in the few-shot setting, which is critically significant for the medical field where data collection and annotation are both very expensive. We propose an innovative approach, MediCLIP, which adapts the CLIP model to few-shot medical image anomaly detection through self-supervised fine-tuning. Although CLIP, as a vision-language model, demonstrates outstanding zero-/fewshot performance on various downstream tasks, it still falls short in the anomaly detection of medical images. To address this, we design a series of medical image anomaly synthesis tasks to simulate common disease patterns in medical imaging, transferring the powerful generalization capabilities of CLIP to the task of medical image anomaly detection. When only few-shot normal medical images are provided, MediCLIP achieves state-of-the-art performance in anomaly detection and location compared to other methods. Extensive experiments on three distinct medical anomaly detection tasks have demonstrated the superiority of our approach. The code is available at https://github.com/cnulab/MediCLIP.
Read more5/21/2024
0
Dual-Image Enhanced CLIP for Zero-Shot Anomaly Detection
Zhaoxiang Zhang, Hanqiu Deng, Jinan Bao, Xingyu Li
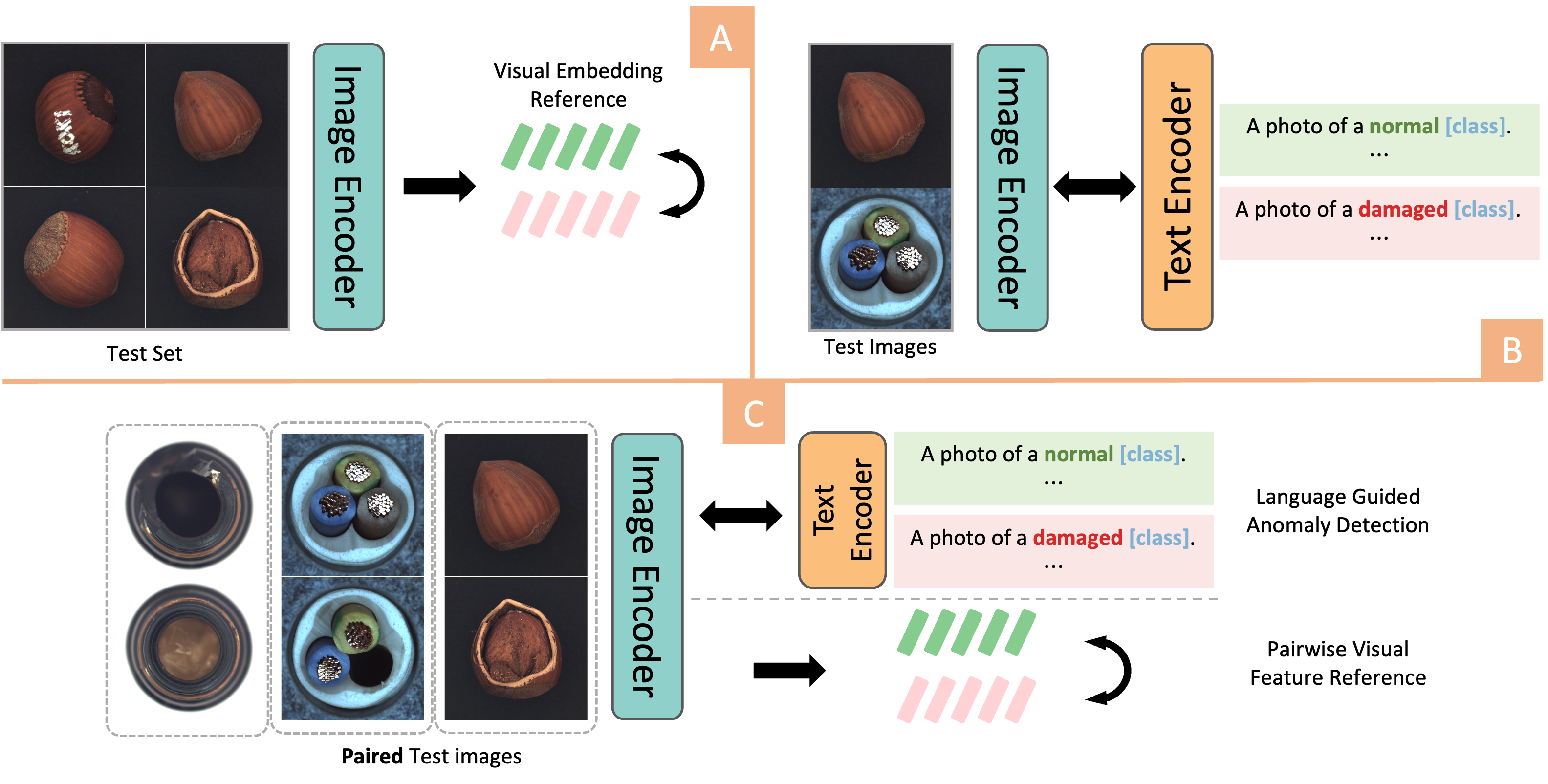
Image Anomaly Detection has been a challenging task in Computer Vision field. The advent of Vision-Language models, particularly the rise of CLIP-based frameworks, has opened new avenues for zero-shot anomaly detection. Recent studies have explored the use of CLIP by aligning images with normal and prompt descriptions. However, the exclusive dependence on textual guidance often falls short, highlighting the critical importance of additional visual references. In this work, we introduce a Dual-Image Enhanced CLIP approach, leveraging a joint vision-language scoring system. Our methods process pairs of images, utilizing each as a visual reference for the other, thereby enriching the inference process with visual context. This dual-image strategy markedly enhanced both anomaly classification and localization performances. Furthermore, we have strengthened our model with a test-time adaptation module that incorporates synthesized anomalies to refine localization capabilities. Our approach significantly exploits the potential of vision-language joint anomaly detection and demonstrates comparable performance with current SOTA methods across various datasets.
Read more5/9/2024

0
AdaCLIP: Adapting CLIP with Hybrid Learnable Prompts for Zero-Shot Anomaly Detection
Yunkang Cao, Jiangning Zhang, Luca Frittoli, Yuqi Cheng, Weiming Shen, Giacomo Boracchi
Zero-shot anomaly detection (ZSAD) targets the identification of anomalies within images from arbitrary novel categories. This study introduces AdaCLIP for the ZSAD task, leveraging a pre-trained vision-language model (VLM), CLIP. AdaCLIP incorporates learnable prompts into CLIP and optimizes them through training on auxiliary annotated anomaly detection data. Two types of learnable prompts are proposed: static and dynamic. Static prompts are shared across all images, serving to preliminarily adapt CLIP for ZSAD. In contrast, dynamic prompts are generated for each test image, providing CLIP with dynamic adaptation capabilities. The combination of static and dynamic prompts is referred to as hybrid prompts, and yields enhanced ZSAD performance. Extensive experiments conducted across 14 real-world anomaly detection datasets from industrial and medical domains indicate that AdaCLIP outperforms other ZSAD methods and can generalize better to different categories and even domains. Finally, our analysis highlights the importance of diverse auxiliary data and optimized prompts for enhanced generalization capacity. Code is available at https://github.com/caoyunkang/AdaCLIP.
Read more7/23/2024