Early-Stage Anomaly Detection: A Study of Model Performance on Complete vs. Partial Flows

0
Sign in to get full access
Overview
- This paper explores the performance of early-stage anomaly detection models when using complete flow information versus partial flow information.
- The researchers investigate the impact of having access to the full sequence of network traffic data (complete flows) versus only the initial portion of the flows (partial flows).
- The study aims to understand how model performance is affected by the availability of partial versus complete flow information in the context of cybersecurity applications.
Plain English Explanation
When it comes to detecting unusual or suspicious activity on computer networks, researchers often use machine learning models to identify potential anomalies. These models can be trained on network traffic data, which consists of "flows" - the sequence of data packets that make up a single communication between devices.
In this paper, the researchers wanted to see how well these anomaly detection models perform when they only have access to the beginning of a flow, rather than the full sequence. This is an important question because, in real-world scenarios, network security teams may not always have the luxury of waiting for a complete flow to be captured before analyzing the data.
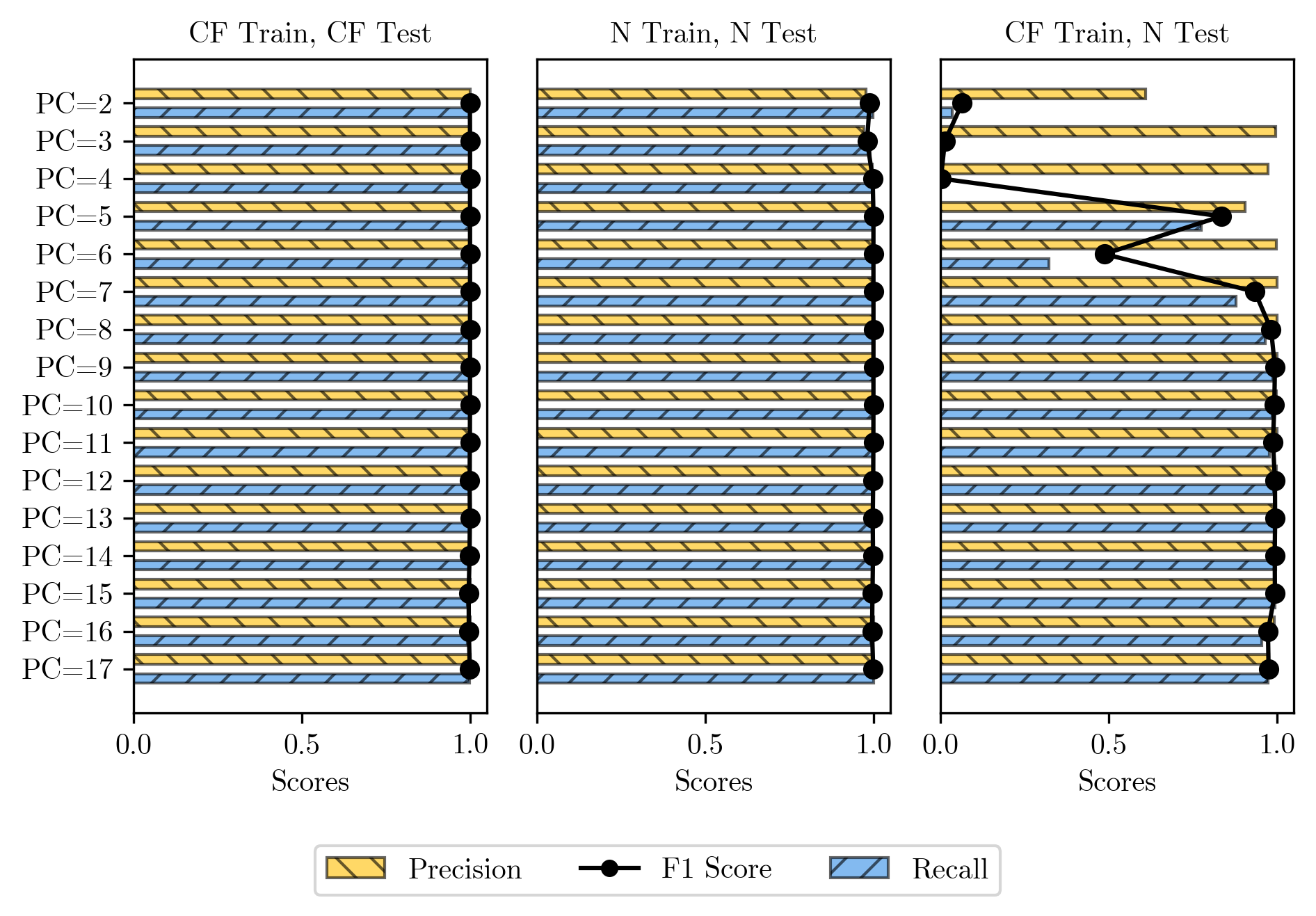
The researchers compared the performance of anomaly detection models when they were trained and tested using either complete flow information or only the initial portion of the flows. They found that the models performed reasonably well even with partial flow data, but there were some significant differences in their ability to accurately identify anomalies compared to when they had access to the full flow information.
This research helps us understand the trade-offs involved in using partial versus complete flow data for early-stage anomaly detection. It suggests that network security teams may need to adjust their models or strategies depending on the type of flow data available to them, in order to maintain effective anomaly detection capabilities.
Technical Explanation
The researchers in this paper evaluated the performance of early-stage anomaly detection models when using complete flow information versus partial flow information. They conducted experiments using the FlowBench dataset, which contains network traffic data labeled with known anomalies.
The researchers trained and tested two types of anomaly detection models: a Mallows-like criterion-based random forest model and a deep learning-based time series model. They compared the models' performance when using the complete flow information versus only the initial portion of the flows (e.g., the first 25% or 50% of the flow data).
The results showed that the models were able to maintain reasonable anomaly detection accuracy even with partial flow information, but their performance was generally better when using the complete flow data. The researchers observed differences in the models' ability to correctly identify anomalies, with the complete flow information leading to higher precision and recall.
The researchers also investigated the impact of the partial flow length on model performance, finding that longer partial flows (e.g., 50% of the full flow) generally resulted in better anomaly detection than shorter partial flows (e.g., 25% of the full flow).
Critical Analysis
The researchers acknowledge several limitations in their study. First, they only evaluated the models on a single dataset (FlowBench), which may not be representative of all real-world network traffic scenarios. Additionally, the researchers did not explore the impact of different types of anomalies or the trade-off between early detection and accuracy.
It would be valuable for future research to expand the evaluation to a wider range of datasets and anomaly types, as well as investigate the optimal balance between early detection and accuracy for different cybersecurity applications. The researchers could also explore techniques for adapting anomaly detection models to work effectively with partial flow information, beyond simply training on the initial portion of the flows.
Overall, this study provides valuable insights into the challenges of early-stage anomaly detection and highlights the importance of considering the availability and quality of network flow data when designing and deploying anomaly detection systems.
Conclusion
This paper examined the performance of early-stage anomaly detection models when using complete flow information versus partial flow information. The researchers found that the models were able to maintain reasonable anomaly detection accuracy even with partial flow data, but their performance was generally better when using the complete flow information.
These findings have important implications for the deployment of anomaly detection systems in real-world cybersecurity scenarios, where network security teams may not always have access to the full sequence of network traffic data. The research suggests that network security teams may need to adapt their anomaly detection strategies based on the type of flow data available to them, in order to maintain effective early-stage anomaly detection capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Early-Stage Anomaly Detection: A Study of Model Performance on Complete vs. Partial Flows
Adrian Pekar, Richard Jozsa
This study investigates the efficacy of machine learning models, specifically Random Forest, in anomaly detection systems when trained on complete flow records and tested on partial flow data. We explore the performance disparity that arises when models are applied to incomplete data typical in real-world, real-time network environments. Our findings demonstrate a significant decline in model performance, with precision and recall dropping by up to 30% under certain conditions when models trained on complete flows are tested against partial flows. Conversely, models trained and tested on consistently complete or partial datasets maintain robustness, highlighting the importance of dataset consistency in training. The study reveals that a minimum of 7 packets in the test set is required for maintaining reliable detection rates. These results underscore the need for tailored training strategies that can effectively adapt to the dynamics of partial data, enhancing the practical applicability of anomaly detection systems in operational settings.
Read more7/4/2024

0
Anomaly Detection Within Mission-Critical Call Processing
Sean Doris, Iosif Salem, Stefan Schmid
With increasingly larger and more complex telecommunication networks, there is a need for improved monitoring and reliability. Requirements increase further when working with mission-critical systems requiring stable operations to meet precise design and client requirements while maintaining high availability. This paper proposes a novel methodology for developing a machine learning model that can assist in maintaining availability (through anomaly detection) for client-server communications in mission-critical systems. To that end, we validate our methodology for training models based on data classified according to client performance. The proposed methodology evaluates the use of machine learning to perform anomaly detection of a single virtualized server loaded with simulated network traffic (using SIPp) with media calls. The collected data for the models are classified based on the round trip time performance experienced on the client side to determine if the trained models can detect anomalous client side performance only using key performance indicators available on the server. We compared the performance of seven different machine learning models by testing different trained and untrained test stressor scenarios. In the comparison, five models achieved an F1-score above 0.99 for the trained test scenarios. Random Forest was the only model able to attain an F1-score above 0.9 for all untrained test scenarios with the lowest being 0.980. The results suggest that it is possible to generate accurate anomaly detection to evaluate degraded client-side performance.
Read more8/28/2024

0
New!Adaptive Anomaly Detection in Network Flows with Low-Rank Tensor Decompositions and Deep Unrolling
Lukas Schynol, Marius Pesavento
Anomaly detection (AD) is increasingly recognized as a key component for ensuring the resilience of future communication systems. While deep learning has shown state-of-the-art AD performance, its application in critical systems is hindered by concerns regarding training data efficiency, domain adaptation and interpretability. This work considers AD in network flows using incomplete measurements, leveraging a robust tensor decomposition approach and deep unrolling techniques to address these challenges. We first propose a novel block-successive convex approximation algorithm based on a regularized model-fitting objective where the normal flows are modeled as low-rank tensors and anomalies as sparse. An augmentation of the objective is introduced to decrease the computational cost. We apply deep unrolling to derive a novel deep network architecture based on our proposed algorithm, treating the regularization parameters as learnable weights. Inspired by Bayesian approaches, we extend the model architecture to perform online adaptation to per-flow and per-time-step statistics, improving AD performance while maintaining a low parameter count and preserving the problem's permutation equivariances. To optimize the deep network weights for detection performance, we employ a homotopy optimization approach based on an efficient approximation of the area under the receiver operating characteristic curve. Extensive experiments on synthetic and real-world data demonstrate that our proposed deep network architecture exhibits a high training data efficiency, outperforms reference methods, and adapts seamlessly to varying network topologies.
Read more9/19/2024

0
Early Detection of Network Service Degradation: An Intra-Flow Approach
Balint Bicski, Adrian Pekar
This research presents a novel method for predicting service degradation (SD) in computer networks by leveraging early flow features. Our approach focuses on the observable (O) segments of network flows, particularly analyzing Packet Inter-Arrival Time (PIAT) values and other derived metrics, to infer the behavior of non-observable (NO) segments. Through a comprehensive evaluation, we identify an optimal O/NO split threshold of 10 observed delay samples, balancing prediction accuracy and resource utilization. Evaluating models including Logistic Regression, XGBoost, and Multi-Layer Perceptron, we find XGBoost outperforms others, achieving an F1-score of 0.74, balanced accuracy of 0.84, and AUROC of 0.97. Our findings highlight the effectiveness of incorporating comprehensive early flow features and the potential of our method to offer a practical solution for monitoring network traffic in resource-constrained environments. This approach ensures enhanced user experience and network performance by preemptively addressing potential SD, providing the basis for a robust framework for maintaining high-quality network services.
Read more9/17/2024