Flow-Bench: A Dataset for Computational Workflow Anomaly Detection

0

Sign in to get full access
Overview
- This paper introduces Flow-Bench, a new dataset for computational workflow anomaly detection.
- The dataset aims to support the development and evaluation of machine learning models for identifying anomalies in complex workflow systems.
- Flow-Bench includes a diverse set of workflow structures, anomaly types, and real-world workflow execution traces.
Plain English Explanation
The paper describes a new dataset called Flow-Bench that is designed to help researchers and developers improve the ability of AI systems to detect problems or unusual behavior in complex computational workflows. Workflows are sequences of interconnected steps that are often used in areas like data analysis, scientific computing, and business processes.
Advancing Anomaly Detection in Computational Workflows with Active Learning and A System for Quantifying the Provenance of Data-Science Workflows at Fine-Grained Levels have highlighted the importance of being able to automatically identify anomalies in workflows, as this can help catch errors, inefficiencies, and security issues.
The Flow-Bench dataset provides a diverse set of example workflows, along with examples of different types of anomalies that can occur. This is meant to serve as a benchmark to train and evaluate machine learning models for anomaly detection in workflows. By having a standardized dataset to work with, researchers can more easily compare and improve these types of AI systems.
The goal is to advance the state-of-the-art in using AI to monitor and maintain the reliability and security of complex computational systems, which are becoming increasingly important as workflows are used in more high-stakes applications.
Technical Explanation
The Flow-Bench dataset contains a variety of computational workflow structures, including those inspired by real-world use cases like MASSW: A New Dataset and Benchmark Tasks for AI-Assisted Data Science Workflows and Workbench: A Benchmark Dataset for Agents in Realistic Workplace Settings. It also includes different types of anomalies, such as missing steps, task failures, and unexpected control flow changes.
The dataset was constructed by first generating a set of realistic workflow templates. These templates were then used to produce workflow execution traces, some of which were injected with various anomalies. The anomalies were introduced in a controlled manner to enable evaluation of anomaly detection performance.
The dataset is structured in a format compatible with the MARDIFLOW-CSE workflow framework, allowing it to be easily integrated into existing workflow management and analysis systems. The authors provide baseline anomaly detection models as a starting point for further research and development.
Critical Analysis
The Flow-Bench dataset represents a valuable contribution to the field of computational workflow anomaly detection. By providing a standardized and diverse benchmark, it enables more rigorous evaluation and comparison of different anomaly detection approaches.
One potential limitation is that the dataset, while inspired by real-world use cases, may not fully capture the complexity and idiosyncrasies of workflows encountered in practice. Additionally, the anomalies introduced are controlled and may not reflect the full range of unexpected behaviors that can arise in operational settings.
Further research could explore techniques for automatically generating more realistic workflow structures and anomalies, potentially by learning from actual workflow execution logs. Incorporating feedback from domain experts and end-users could also help ensure the dataset better reflects real-world challenges.
Conclusion
The Flow-Bench dataset represents an important step forward in supporting the development of advanced anomaly detection systems for computational workflows. By providing a standardized benchmark, it can accelerate research in this area and help drive progress towards more reliable and secure workflow-based applications. As computational workflows become increasingly prevalent, the ability to automatically identify and mitigate anomalies will be crucial for ensuring the robustness and trustworthiness of these complex systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Flow-Bench: A Dataset for Computational Workflow Anomaly Detection
George Papadimitriou, Hongwei Jin, Cong Wang, Rajiv Mayani, Krishnan Raghavan, Anirban Mandal, Prasanna Balaprakash, Ewa Deelman
A computational workflow, also known as workflow, consists of tasks that must be executed in a specific order to attain a specific goal. Often, in fields such as biology, chemistry, physics, and data science, among others, these workflows are complex and are executed in large-scale, distributed, and heterogeneous computing environments prone to failures and performance degradation. Therefore, anomaly detection for workflows is an important paradigm that aims to identify unexpected behavior or errors in workflow execution. This crucial task to improve the reliability of workflow executions can be further assisted by machine learning-based techniques. However, such application is limited, in large part, due to the lack of open datasets and benchmarking. To address this gap, we make the following contributions in this paper: (1) we systematically inject anomalies and collect raw execution logs from workflows executing on distributed infrastructures; (2) we summarize the statistics of new datasets, and provide insightful analyses; (3) we convert workflows into tabular, graph and text data, and benchmark with supervised and unsupervised anomaly detection techniques correspondingly. The presented dataset and benchmarks allow examining the effectiveness and efficiency of scientific computational workflows and identifying potential research opportunities for improvement and generalization. The dataset and benchmark code are publicly available url{https://poseidon-workflows.github.io/FlowBench/} under the MIT License.
Read more6/14/2024
0
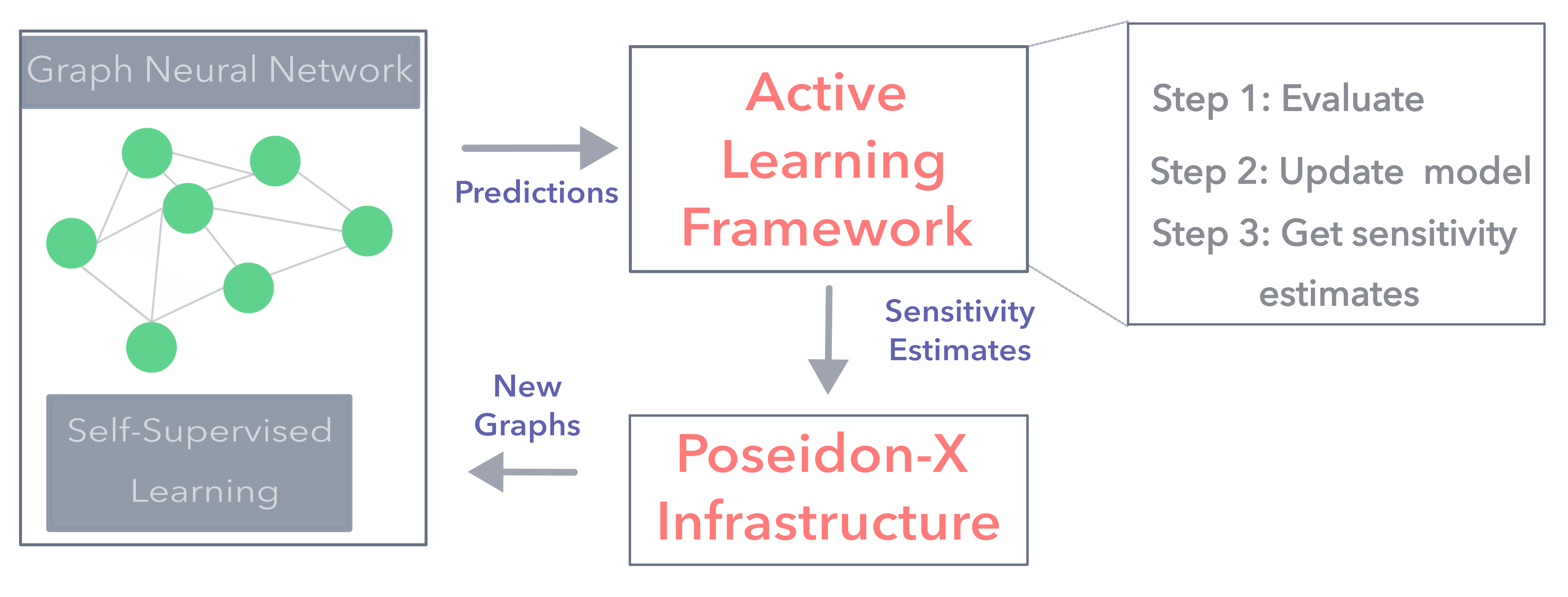
Advancing Anomaly Detection in Computational Workflows with Active Learning
Krishnan Raghavan, George Papadimitriou, Hongwei Jin, Anirban Mandal, Mariam Kiran, Prasanna Balaprakash, Ewa Deelman
A computational workflow, also known as workflow, consists of tasks that are executed in a certain order to attain a specific computational campaign. Computational workflows are commonly employed in science domains, such as physics, chemistry, genomics, to complete large-scale experiments in distributed and heterogeneous computing environments. However, running computations at such a large scale makes the workflow applications prone to failures and performance degradation, which can slowdown, stall, and ultimately lead to workflow failure. Learning how these workflows behave under normal and anomalous conditions can help us identify the causes of degraded performance and subsequently trigger appropriate actions to resolve them. However, learning in such circumstances is a challenging task because of the large volume of high-quality historical data needed to train accurate and reliable models. Generating such datasets not only takes a lot of time and effort but it also requires a lot of resources to be devoted to data generation for training purposes. Active learning is a promising approach to this problem. It is an approach where the data is generated as required by the machine learning model and thus it can potentially reduce the training data needed to derive accurate models. In this work, we present an active learning approach that is supported by an experimental framework, Poseidon-X, that utilizes a modern workflow management system and two cloud testbeds. We evaluate our approach using three computational workflows. For one workflow we run an end-to-end live active learning experiment, for the other two we evaluate our active learning algorithms using pre-captured data traces provided by the Flow-Bench benchmark. Our findings indicate that active learning not only saves resources, but it also improves the accuracy of the detection of anomalies.
Read more5/13/2024
0
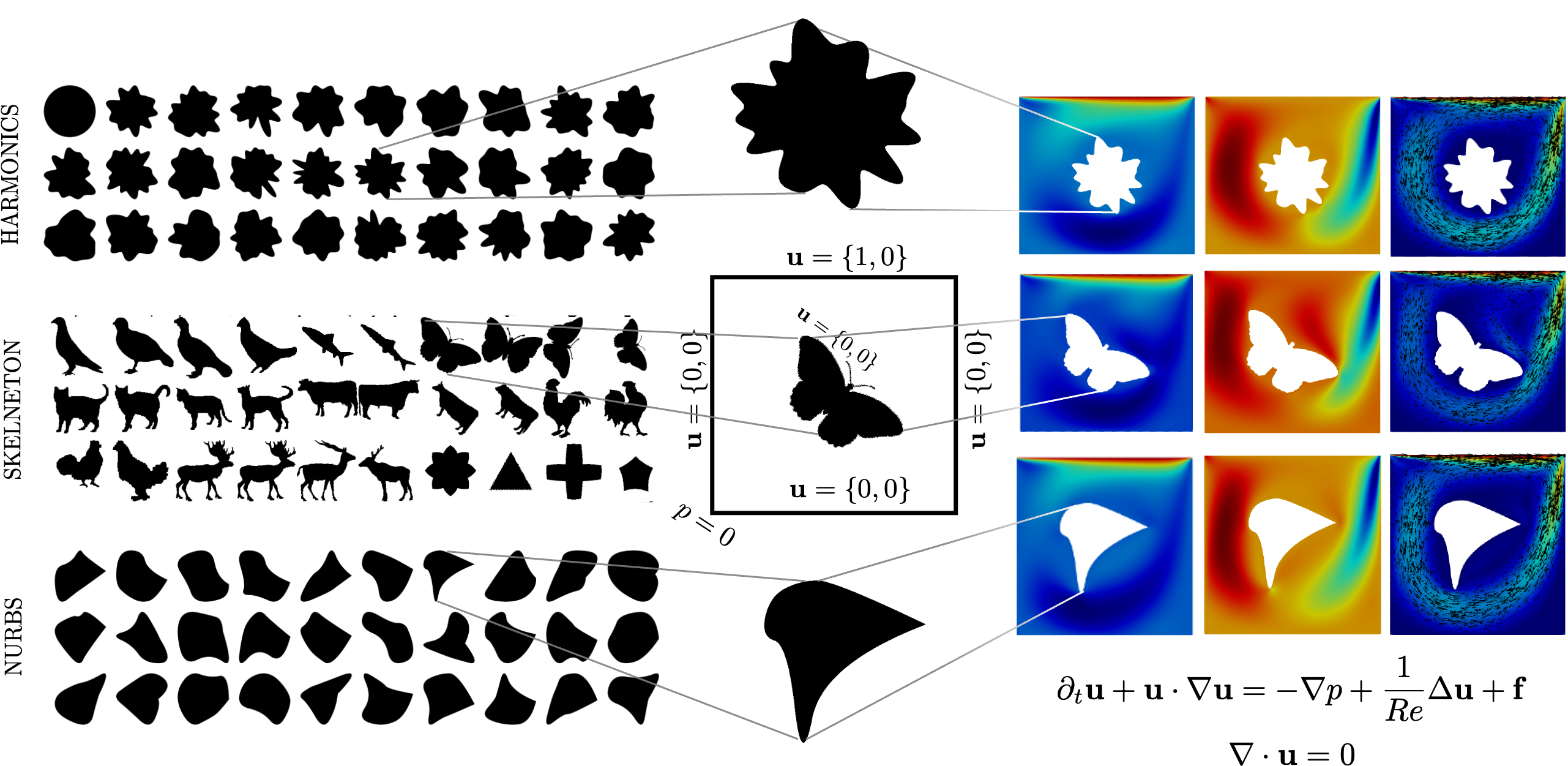
FlowBench: A Large Scale Benchmark for Flow Simulation over Complex Geometries
Ronak Tali, Ali Rabeh, Cheng-Hau Yang, Mehdi Shadkhah, Samundra Karki, Abhisek Upadhyaya, Suriya Dhakshinamoorthy, Marjan Saadati, Soumik Sarkar, Adarsh Krishnamurthy, Chinmay Hegde, Aditya Balu, Baskar Ganapathysubramanian
Simulating fluid flow around arbitrary shapes is key to solving various engineering problems. However, simulating flow physics across complex geometries remains numerically challenging and computationally resource-intensive, particularly when using conventional PDE solvers. Machine learning methods offer attractive opportunities to create fast and adaptable PDE solvers. However, benchmark datasets to measure the performance of such methods are scarce, especially for flow physics across complex geometries. We introduce FlowBench, a dataset for neural simulators with over 10K samples, which is currently larger than any publicly available flow physics dataset. FlowBench contains flow simulation data across complex geometries (textit{parametric vs. non-parametric}), spanning a range of flow conditions (textit{Reynolds number and Grashoff number}), capturing a diverse array of flow phenomena (textit{steady vs. transient; forced vs. free convection}), and for both 2D and 3D. FlowBench contains over 10K data samples, with each sample the outcome of a fully resolved, direct numerical simulation using a well-validated simulator framework designed for modeling transport phenomena in complex geometries. For each sample, we include velocity, pressure, and temperature field data at 3 different resolutions and several summary statistics features of engineering relevance (such as coefficients of lift and drag, and Nusselt numbers). %Additionally, we include masks and signed distance fields for each shape. We envision that FlowBench will enable evaluating the interplay between complex geometry, coupled flow phenomena, and data sufficiency on the performance of current, and future, neural PDE solvers. We enumerate several evaluation metrics to help rank order the performance of neural PDE solvers. We benchmark the performance of several baseline methods including FNO, CNO, WNO, and DeepONet.
Read more9/27/2024

0
A System for Quantifying Data Science Workflows with Fine-Grained Procedural Logging and a Pilot Study
Jinjin Zhao, Avidgor Gal, Sanjay Krishnan
It is important for researchers to understand precisely how data scientists turn raw data into insights, including typical programming patterns, workflow, and methodology. This paper contributes a novel system, called DataInquirer, that tracks incremental code executions in Jupyter notebooks (a type of computational notebook). The system allows us to quantitatively measure timing, workflow, and operation frequency in data science tasks without resorting to human annotation or interview. In a series of pilot studies, we collect 97 traces, logging data scientist activities across four studies. While this paper presents a general system and data analysis approach, we focus on a foundational sub-question in our pilot studies: How consistent are different data scientists in analyzing the same data? We taxonomize variation between data scientists on the same dataset according to three categories: semantic, syntactic, and methodological. Our results suggest that there are statistically significant differences in the conclusions reached by different data scientists on the same task and present quantitative evidence for this phenomenon. Furthermore, our results suggest that AI-powered code tools subtly influence these results, allowing student participants to generate workflows that more resemble expert data practitioners.
Read more5/29/2024