The Effect of Data Poisoning on Counterfactual Explanations
2402.08290
0
0
📊
Abstract
Counterfactual explanations provide a popular method for analyzing the predictions of black-box systems, and they can offer the opportunity for computational recourse by suggesting actionable changes on how to change the input to obtain a different (i.e. more favorable) system output. However, recent work highlighted their vulnerability to different types of manipulations. This work studies the vulnerability of counterfactual explanations to data poisoning. We formally introduce and investigate data poisoning in the context of counterfactual explanations for increasing the cost of recourse on three different levels: locally for a single instance, or a sub-group of instances, or globally for all instances. In this context, we characterize and prove the correctness of several different data poisonings. We also empirically demonstrate that state-of-the-art counterfactual generation methods and toolboxes are vulnerable to such data poisoning.
Create account to get full access
Overview
- This paper examines the vulnerability of counterfactual explanations to data poisoning attacks.
- Counterfactual explanations are a popular method for analyzing the predictions of black-box systems, as they can suggest actionable changes to obtain a different (more favorable) output.
- However, recent research has highlighted the susceptibility of counterfactual explanations to various manipulations.
- This work formalizes data poisoning in the context of counterfactual explanations and demonstrates that state-of-the-art counterfactual generation methods are vulnerable to such attacks.
Plain English Explanation
Counterfactual explanations are a way to understand how black-box AI systems make their predictions. They suggest changes to the input that would result in a different, more favorable output from the system. This can be helpful for users who want to know how to get a better outcome from the system.
However, recent studies have shown that counterfactual explanations can be manipulated in various ways. This paper looks at a specific type of manipulation called "data poisoning." The researchers formalize how an attacker could intentionally modify the training data to make it harder for users to find ways to change the system's output, even if that output is unfavorable to them.
The paper demonstrates that current methods and tools for generating counterfactual explanations are vulnerable to these data poisoning attacks. This is an important finding, as it highlights a potential weakness in a popular technique for explaining AI systems.
Technical Explanation
The paper formalizes the concept of data poisoning in the context of counterfactual explanations. The authors consider three levels of data poisoning attacks:
- Local: Poisoning the data for a single instance or a subgroup of instances to increase the cost of finding a counterfactual explanation.
- Group-level: Poisoning the data for a specific subgroup of instances to make it harder for members of that group to find counterfactual explanations.
- Global: Poisoning the entire dataset to increase the cost of finding counterfactual explanations across all instances.
The paper demonstrates the vulnerability of state-of-the-art counterfactual generation methods and toolboxes, such as DICE and DiCE, to these data poisoning attacks. The researchers show how an attacker can strategically modify the training data to make it significantly more difficult for users to find actionable counterfactual explanations.
Critical Analysis
The paper provides a valuable contribution by highlighting a potential weakness in the use of counterfactual explanations. By demonstrating the vulnerability of these methods to data poisoning attacks, the authors raise important questions about the robustness and reliability of counterfactual explanations in real-world applications.
However, the paper does not fully address the broader implications of these findings. For example, it would be helpful to understand the feasibility and likelihood of such data poisoning attacks occurring in practice, as well as the potential impacts on users and stakeholders. Additionally, the paper does not discuss potential countermeasures or mitigation strategies that could be developed to address this vulnerability.
Further research could explore the development of more robust counterfactual explanation methods that are less susceptible to data poisoning, or the integration of counterfactual explanations with other AI interpretability techniques to provide a more comprehensive understanding of system behavior.
Conclusion
This paper highlights a critical vulnerability in the use of counterfactual explanations for analyzing the predictions of black-box AI systems. By formalizing the concept of data poisoning and demonstrating the susceptibility of state-of-the-art counterfactual generation methods, the authors have revealed a significant limitation in a widely-used technique for interpreting AI system outputs.
While counterfactual explanations offer the promise of computational recourse, this research suggests that their reliability and usefulness may be compromised by strategic data manipulation. As the use of AI systems becomes more widespread, understanding and addressing such vulnerabilities will be crucial for ensuring the transparency, accountability, and trustworthiness of these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
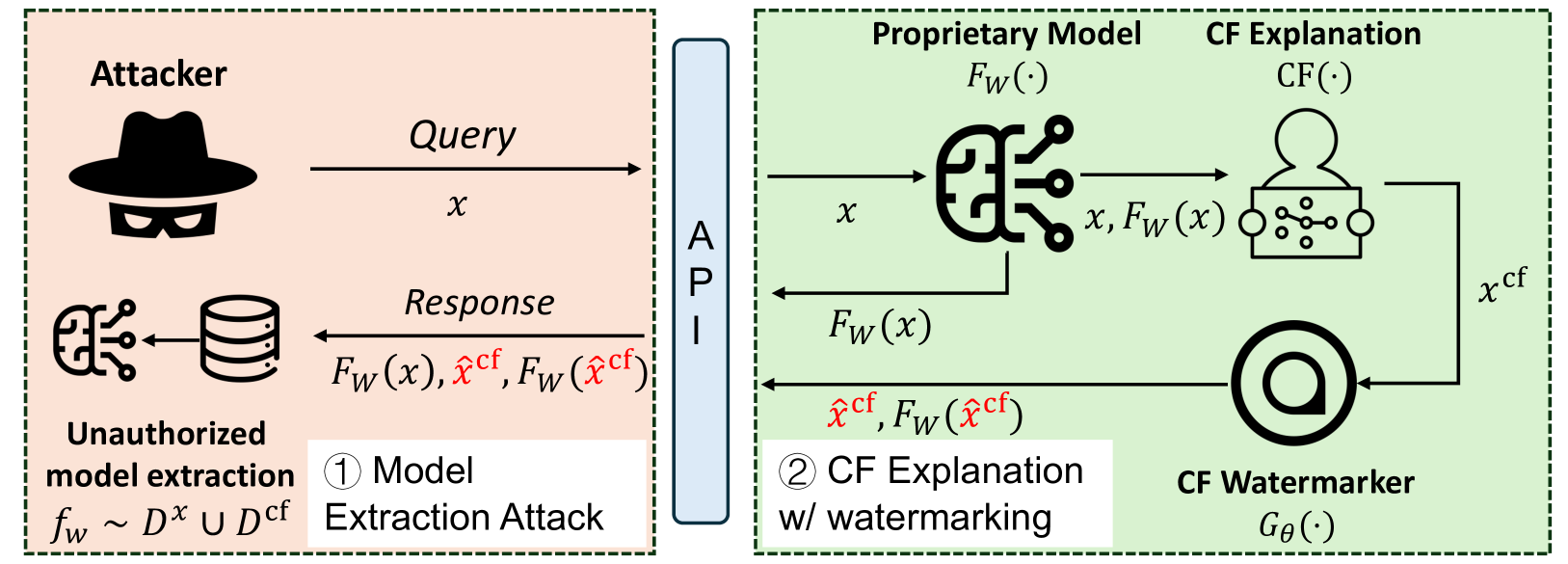
Watermarking Counterfactual Explanations
Hangzhi Guo, Amulya Yadav
0
0
The field of Explainable Artificial Intelligence (XAI) focuses on techniques for providing explanations to end-users about the decision-making processes that underlie modern-day machine learning (ML) models. Within the vast universe of XAI techniques, counterfactual (CF) explanations are often preferred by end-users as they help explain the predictions of ML models by providing an easy-to-understand & actionable recourse (or contrastive) case to individual end-users who are adversely impacted by predicted outcomes. However, recent studies have shown significant security concerns with using CF explanations in real-world applications; in particular, malicious adversaries can exploit CF explanations to perform query-efficient model extraction attacks on proprietary ML models. In this paper, we propose a model-agnostic watermarking framework (for adding watermarks to CF explanations) that can be leveraged to detect unauthorized model extraction attacks (which rely on the watermarked CF explanations). Our novel framework solves a bi-level optimization problem to embed an indistinguishable watermark into the generated CF explanation such that any future model extraction attacks that rely on these watermarked CF explanations can be detected using a null hypothesis significance testing (NHST) scheme, while ensuring that these embedded watermarks do not compromise the quality of the generated CF explanations. We evaluate this framework's performance across a diverse set of real-world datasets, CF explanation methods, and model extraction techniques, and show that our watermarking detection system can be used to accurately identify extracted ML models that are trained using the watermarked CF explanations. Our work paves the way for the secure adoption of CF explanations in real-world applications.
5/30/2024
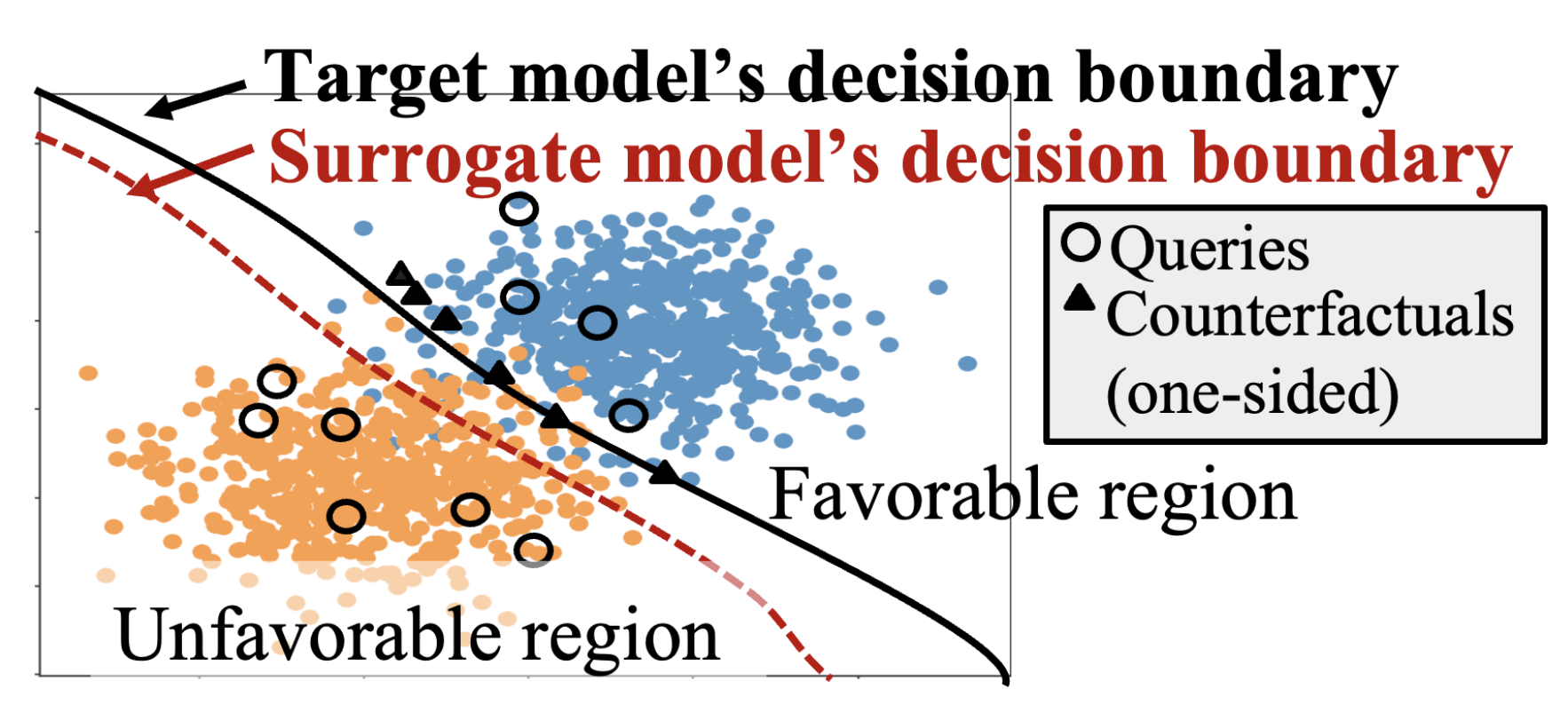
Model Reconstruction Using Counterfactual Explanations: Mitigating the Decision Boundary Shift
Pasan Dissanayake, Sanghamitra Dutta
0
0
Counterfactual explanations find ways of achieving a favorable model outcome with minimum input perturbation. However, counterfactual explanations can also be exploited to steal the model by strategically training a surrogate model to give similar predictions as the original (target) model. In this work, we investigate model extraction by specifically leveraging the fact that the counterfactual explanations also lie quite close to the decision boundary. We propose a novel strategy for model extraction that we call Counterfactual Clamping Attack (CCA) which trains a surrogate model using a unique loss function that treats counterfactuals differently than ordinary instances. Our approach also alleviates the related problem of decision boundary shift that arises in existing model extraction attacks which treat counterfactuals as ordinary instances. We also derive novel mathematical relationships between the error in model approximation and the number of queries using polytope theory. Experimental results demonstrate that our strategy provides improved fidelity between the target and surrogate model predictions on several real world datasets.
5/10/2024
🎯
Benchmarking Instance-Centric Counterfactual Algorithms for XAI: From White Box to Black Bo
Catarina Moreira, Yu-Liang Chou, Chihcheng Hsieh, Chun Ouyang, Joaquim Jorge, Jo~ao Madeiras Pereira
0
0
This study investigates the impact of machine learning models on the generation of counterfactual explanations by conducting a benchmark evaluation over three different types of models: a decision tree (fully transparent, interpretable, white-box model), a random forest (semi-interpretable, grey-box model), and a neural network (fully opaque, black-box model). We tested the counterfactual generation process using four algorithms (DiCE, WatcherCF, prototype, and GrowingSpheresCF) in the literature in 25 different datasets. Our findings indicate that: (1) Different machine learning models have little impact on the generation of counterfactual explanations; (2) Counterfactual algorithms based uniquely on proximity loss functions are not actionable and will not provide meaningful explanations; (3) One cannot have meaningful evaluation results without guaranteeing plausibility in the counterfactual generation. Algorithms that do not consider plausibility in their internal mechanisms will lead to biased and unreliable conclusions if evaluated with the current state-of-the-art metrics; (4) A counterfactual inspection analysis is strongly recommended to ensure a robust examination of counterfactual explanations and the potential identification of biases.
6/12/2024
📊
Generating Counterfactual Explanations Using Cardinality Constraints
Rub'en Ruiz-Torrubiano
0
0
Providing explanations about how machine learning algorithms work and/or make particular predictions is one of the main tools that can be used to improve their trusworthiness, fairness and robustness. Among the most intuitive type of explanations are counterfactuals, which are examples that differ from a given point only in the prediction target and some set of features, presenting which features need to be changed in the original example to flip the prediction for that example. However, such counterfactuals can have many different features than the original example, making their interpretation difficult. In this paper, we propose to explicitly add a cardinality constraint to counterfactual generation limiting how many features can be different from the original example, thus providing more interpretable and easily understantable counterfactuals.
4/12/2024