The Effect of Model Size on LLM Post-hoc Explainability via LIME
2405.05348
0
0

Abstract
Large language models (LLMs) are becoming bigger to boost performance. However, little is known about how explainability is affected by this trend. This work explores LIME explanations for DeBERTaV3 models of four different sizes on natural language inference (NLI) and zero-shot classification (ZSC) tasks. We evaluate the explanations based on their faithfulness to the models' internal decision processes and their plausibility, i.e. their agreement with human explanations. The key finding is that increased model size does not correlate with plausibility despite improved model performance, suggesting a misalignment between the LIME explanations and the models' internal processes as model size increases. Our results further suggest limitations regarding faithfulness metrics in NLI contexts.
Create account to get full access
Overview
- This research paper examines the effect of model size on the post-hoc explainability of large language models (LLMs) using the LIME technique.
- The authors investigate how the effectiveness of LIME in explaining LLM decisions changes as the model size increases.
- The study provides insights into the relationship between model complexity and the interpretability of its decisions, which is crucial for the responsible development and deployment of AI systems.
Plain English Explanation
The paper looks at how the size of large language models (like the ones used in chatbots and text generation) affects the ability to explain how they make their decisions. The researchers used a technique called LIME to try to understand the reasoning behind the models' outputs.
As language models get larger and more complex, it becomes harder to understand exactly why they produce the results they do. LIME is a method that tries to break down the model's thinking process and identify the key factors influencing its decisions.
The study found that as the models got bigger, LIME became less effective at providing meaningful explanations. The larger, more sophisticated models seemed to rely on more nuanced and interconnected patterns that were difficult to disentangle using LIME. This suggests that as language models continue to grow in scale, we may need new techniques to understand and verify their behavior.
Understanding how these powerful AI systems make decisions is critical, both for improving their capabilities and ensuring they behave in alignment with human values. This research highlights the challenges we face in making complex AI models more transparent and accountable.
Technical Explanation
The authors conducted experiments to assess the effectiveness of LIME (Local Interpretable Model-agnostic Explanations) in explaining the decisions of LLMs of varying sizes. LIME is a post-hoc explainability technique that aims to identify the most influential input features contributing to a model's prediction for a given instance.
The researchers used language models from the GPT-2 and GPT-3 families, ranging from the smaller 117M parameter model to the larger 175B parameter model. They evaluated LIME's performance on a variety of NLP tasks, including sentiment analysis, natural language inference, and question answering.
The results showed that as the model size increased, the LIME explanations became less faithful and less stable, providing less insight into the models' decision-making processes. The authors hypothesize that this is due to the growing complexity of the internal representations and decision-making mechanisms in larger LLMs, which cannot be easily approximated by the local linear models used by LIME.
These findings suggest that existing post-hoc explainability techniques may struggle to keep pace with the growing sophistication of large language models. As AI systems become more powerful, new approaches to interpretability and transparency may be needed to ensure their responsible development and deployment.
Critical Analysis
The paper provides valuable insights into the limitations of post-hoc explainability methods, such as LIME, when applied to large and complex language models. The authors acknowledge that their findings do not necessarily generalize to other explainability techniques or to different types of AI models.
One potential concern is the reliance on a single explainability method (LIME) in the study. It would be informative to see how other approaches, such as SHAP or counterfactual explanations, perform on these large language models. Additionally, the paper does not explore potential mitigation strategies or alternative explanatory frameworks that could be more suited to understanding the decision-making of complex LLMs.
Further research is needed to better understand the factors that contribute to the decrease in LIME's effectiveness as model size increases. Investigating the specific model characteristics, architectural choices, or training regimes that lead to this phenomenon could inform the development of more robust explainability methods.
Overall, the paper raises important questions about the scalability and generalizability of existing post-hoc explainability techniques, which will need to be addressed as AI systems continue to grow in complexity and become more ubiquitous in real-world applications.
Conclusion
This research highlights the challenges in providing meaningful explanations for the decisions of large and sophisticated language models using post-hoc techniques like LIME. As language models become increasingly powerful and complex, the ability to understand and verify their behavior becomes crucial for the responsible development and deployment of AI systems.
The findings suggest that new approaches to interpretability and transparency may be necessary to keep pace with the growing sophistication of large language models. Continued research in this area can help ensure that these powerful AI systems are aligned with human values and can be trusted to make decisions that positively impact society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
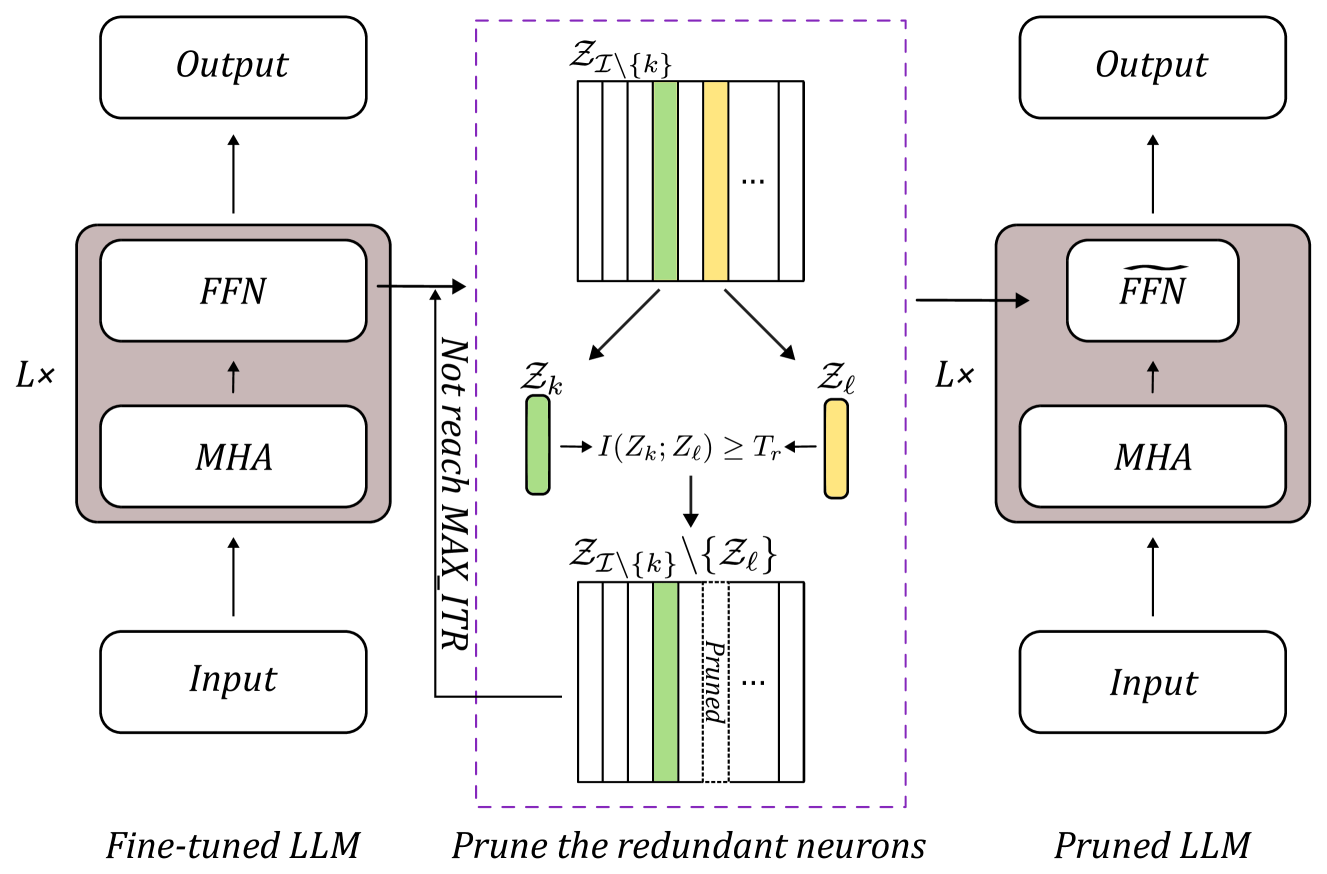
Large Language Model Pruning
Hanjuan Huang (Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology, Taipei, Taiwan), Hao-Jia Song (Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology, Taipei, Taiwan), Hsing-Kuo Pao (Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology, Taipei, Taiwan)
0
0
We surely enjoy the larger the better models for their superior performance in the last couple of years when both the hardware and software support the birth of such extremely huge models. The applied fields include text mining and others. In particular, the success of LLMs on text understanding and text generation draws attention from researchers who have worked on NLP and related areas for years or even decades. On the side, LLMs may suffer from problems like model overfitting, hallucination, and device limitation to name a few. In this work, we suggest a model pruning technique specifically focused on LLMs. The proposed methodology emphasizes the explainability of deep learning models. By having the theoretical foundation, we obtain a trustworthy deep model so that huge models with a massive number of model parameters become not quite necessary. A mutual information-based estimation is adopted to find neurons with redundancy to eliminate. Moreover, an estimator with well-tuned parameters helps to find precise estimation to guide the pruning procedure. At the same time, we also explore the difference between pruning on large-scale models vs. pruning on small-scale models. The choice of pruning criteria is sensitive in small models but not for large-scale models. It is a novel finding through this work. Overall, we demonstrate the superiority of the proposed model to the state-of-the-art models.
6/4/2024
💬
Towards Uncovering How Large Language Model Works: An Explainability Perspective
Haiyan Zhao, Fan Yang, Bo Shen, Himabindu Lakkaraju, Mengnan Du
0
0
Large language models (LLMs) have led to breakthroughs in language tasks, yet the internal mechanisms that enable their remarkable generalization and reasoning abilities remain opaque. This lack of transparency presents challenges such as hallucinations, toxicity, and misalignment with human values, hindering the safe and beneficial deployment of LLMs. This paper aims to uncover the mechanisms underlying LLM functionality through the lens of explainability. First, we review how knowledge is architecturally composed within LLMs and encoded in their internal parameters via mechanistic interpretability techniques. Then, we summarize how knowledge is embedded in LLM representations by leveraging probing techniques and representation engineering. Additionally, we investigate the training dynamics through a mechanistic perspective to explain phenomena such as grokking and memorization. Lastly, we explore how the insights gained from these explanations can enhance LLM performance through model editing, improve efficiency through pruning, and better align with human values.
4/17/2024
💬
Language in Vivo vs. in Silico: Size Matters but Larger Language Models Still Do Not Comprehend Language on a Par with Humans
Vittoria Dentella, Fritz Guenther, Evelina Leivada
0
0
Understanding the limits of language is a prerequisite for Large Language Models (LLMs) to act as theories of natural language. LLM performance in some language tasks presents both quantitative and qualitative differences from that of humans, however it remains to be determined whether such differences are amenable to model size. This work investigates the critical role of model scaling, determining whether increases in size make up for such differences between humans and models. We test three LLMs from different families (Bard, 137 billion parameters; ChatGPT-3.5, 175 billion; ChatGPT-4, 1.5 trillion) on a grammaticality judgment task featuring anaphora, center embedding, comparatives, and negative polarity. N=1,200 judgments are collected and scored for accuracy, stability, and improvements in accuracy upon repeated presentation of a prompt. Results of the best performing LLM, ChatGPT-4, are compared to results of n=80 humans on the same stimuli. We find that increased model size may lead to better performance, but LLMs are still not sensitive to (un)grammaticality as humans are. It seems possible but unlikely that scaling alone can fix this issue. We interpret these results by comparing language learning in vivo and in silico, identifying three critical differences concerning (i) the type of evidence, (ii) the poverty of the stimulus, and (iii) the occurrence of semantic hallucinations due to impenetrable linguistic reference.
4/24/2024

Why Larger Language Models Do In-context Learning Differently?
Zhenmei Shi, Junyi Wei, Zhuoyan Xu, Yingyu Liang
0
0
Large language models (LLM) have emerged as a powerful tool for AI, with the key ability of in-context learning (ICL), where they can perform well on unseen tasks based on a brief series of task examples without necessitating any adjustments to the model parameters. One recent interesting mysterious observation is that models of different scales may have different ICL behaviors: larger models tend to be more sensitive to noise in the test context. This work studies this observation theoretically aiming to improve the understanding of LLM and ICL. We analyze two stylized settings: (1) linear regression with one-layer single-head linear transformers and (2) parity classification with two-layer multiple attention heads transformers (non-linear data and non-linear model). In both settings, we give closed-form optimal solutions and find that smaller models emphasize important hidden features while larger ones cover more hidden features; thus, smaller models are more robust to noise while larger ones are more easily distracted, leading to different ICL behaviors. This sheds light on where transformers pay attention to and how that affects ICL. Preliminary experimental results on large base and chat models provide positive support for our analysis.
5/31/2024