Efficient Duple Perturbation Robustness in Low-rank MDPs
2404.08089
0
0
👀
Abstract
The pursuit of robustness has recently been a popular topic in reinforcement learning (RL) research, yet the existing methods generally suffer from efficiency issues that obstruct their real-world implementation. In this paper, we introduce duple perturbation robustness, i.e. perturbation on both the feature and factor vectors for low-rank Markov decision processes (MDPs), via a novel characterization of $(xi,eta)$-ambiguity sets. The novel robust MDP formulation is compatible with the function representation view, and therefore, is naturally applicable to practical RL problems with large or even continuous state-action spaces. Meanwhile, it also gives rise to a provably efficient and practical algorithm with theoretical convergence rate guarantee. Examples are designed to justify the new robustness concept, and algorithmic efficiency is supported by both theoretical bounds and numerical simulations.
Create account to get full access
Overview
- This paper explores a method for efficiently training reinforcement learning agents to be robust against "duple perturbations" in low-rank Markov Decision Processes (MDPs).
- Duple perturbations are a type of uncertainty in the environment where both the transition dynamics and reward functions can be perturbed.
- The proposed approach leverages the low-rank structure of the MDP to efficiently compute robust policies without requiring expensive robust optimization.
Plain English Explanation
The paper looks at a challenge in reinforcement learning (RL) where the environment an RL agent operates in can change in unpredictable ways. Specifically, it considers a setting where both how the agent moves through the environment (the "transition dynamics") and the rewards it receives can be perturbed or altered. This type of uncertainty is called "duple perturbation."
To address this challenge, the researchers developed a method that can efficiently compute policies (decision-making strategies) that are robust to these duple perturbations. Their key insight is that they can leverage the fact that the underlying MDP (Markov Decision Process, a mathematical model used in RL) has a low-rank structure. This low-rank property allows them to compute robust policies without having to resort to expensive robust optimization techniques.
The low-rank assumption means that the transition dynamics and reward functions of the MDP can be approximated using a small number of parameters. This makes the problem of finding robust policies more tractable. The researchers show that their approach can provide strong robustness guarantees while being much more computationally efficient than previous methods.
Technical Explanation
The paper considers a reinforcement learning setting where the Markov Decision Process (MDP) underlying the environment is subject to "duple perturbations." This means that both the transition dynamics and the reward function of the MDP can be perturbed or altered in uncertain ways.
To address this challenge, the authors propose an approach that exploits the low-rank structure of the MDP. Specifically, they show that if the transition dynamics and reward function of the MDP can be well-approximated by low-rank matrices, then it is possible to efficiently compute robust policies without resorting to expensive robust optimization techniques.
The key idea is to first compute a low-rank approximation of the transition dynamics and reward function. Then, they use this low-rank structure to efficiently solve for the robust value function and robust policy using a novel algorithm. This algorithm provides strong robustness guarantees while being much more computationally efficient than previous approaches, which relied on more general robust optimization techniques.
The authors provide theoretical analysis to characterize the robustness and sample complexity of their approach. They also demonstrate the practical effectiveness of their method through a series of experiments on synthetic and real-world RL benchmarks.
Critical Analysis
The paper presents a promising approach for addressing the challenge of duple perturbation robustness in reinforcement learning. By exploiting the low-rank structure of the underlying MDP, the authors are able to develop an efficient algorithm for computing robust policies without the high computational costs of general robust optimization.
One potential limitation is the reliance on the low-rank assumption. While the authors show that this assumption holds in certain domains, it may not be applicable in all MDP settings. Further research is needed to understand the broader applicability of this approach and its robustness to violations of the low-rank assumption.
Additionally, the paper focuses on the theoretical aspects of the problem and provides limited experimental validation. It would be helpful to see more extensive testing on a diverse set of RL benchmarks to better understand the practical implications and limitations of the proposed method.
Another area for further research is the potential integration of this approach with other techniques for improving robustness in reinforcement learning, such as Distributionally Robust Reinforcement Learning or Game-Theoretic Robust Reinforcement Learning. Combining these methods may lead to even more robust and reliable RL agents.
Conclusion
This paper presents an efficient approach for computing robust policies in reinforcement learning settings with duple perturbations, where both the transition dynamics and reward function of the underlying MDP can be altered in uncertain ways. By exploiting the low-rank structure of the MDP, the authors develop a computationally efficient algorithm that provides strong robustness guarantees.
The proposed method represents a significant advancement in the field of robust reinforcement learning, with potential applications in safety-critical domains where environmental uncertainty is a major concern. While further research is needed to fully understand the limitations and broader applicability of this approach, it is a promising step towards building more reliable and robust RL agents that can operate effectively in complex and changing environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Time-Constrained Robust MDPs
Adil Zouitine, David Bertoin, Pierre Clavier, Matthieu Geist, Emmanuel Rachelson
0
0
Robust reinforcement learning is essential for deploying reinforcement learning algorithms in real-world scenarios where environmental uncertainty predominates. Traditional robust reinforcement learning often depends on rectangularity assumptions, where adverse probability measures of outcome states are assumed to be independent across different states and actions. This assumption, rarely fulfilled in practice, leads to overly conservative policies. To address this problem, we introduce a new time-constrained robust MDP (TC-RMDP) formulation that considers multifactorial, correlated, and time-dependent disturbances, thus more accurately reflecting real-world dynamics. This formulation goes beyond the conventional rectangularity paradigm, offering new perspectives and expanding the analytical framework for robust RL. We propose three distinct algorithms, each using varying levels of environmental information, and evaluate them extensively on continuous control benchmarks. Our results demonstrate that these algorithms yield an efficient tradeoff between performance and robustness, outperforming traditional deep robust RL methods in time-constrained environments while preserving robustness in classical benchmarks. This study revisits the prevailing assumptions in robust RL and opens new avenues for developing more practical and realistic RL applications.
6/13/2024
🏅
The Curious Price of Distributional Robustness in Reinforcement Learning with a Generative Model
Laixi Shi, Gen Li, Yuting Wei, Yuxin Chen, Matthieu Geist, Yuejie Chi
0
0
This paper investigates model robustness in reinforcement learning (RL) to reduce the sim-to-real gap in practice. We adopt the framework of distributionally robust Markov decision processes (RMDPs), aimed at learning a policy that optimizes the worst-case performance when the deployed environment falls within a prescribed uncertainty set around the nominal MDP. Despite recent efforts, the sample complexity of RMDPs remained mostly unsettled regardless of the uncertainty set in use. It was unclear if distributional robustness bears any statistical consequences when benchmarked against standard RL. Assuming access to a generative model that draws samples based on the nominal MDP, we characterize the sample complexity of RMDPs when the uncertainty set is specified via either the total variation (TV) distance or $chi^2$ divergence. The algorithm studied here is a model-based method called {em distributionally robust value iteration}, which is shown to be near-optimal for the full range of uncertainty levels. Somewhat surprisingly, our results uncover that RMDPs are not necessarily easier or harder to learn than standard MDPs. The statistical consequence incurred by the robustness requirement depends heavily on the size and shape of the uncertainty set: in the case w.r.t.~the TV distance, the minimax sample complexity of RMDPs is always smaller than that of standard MDPs; in the case w.r.t.~the $chi^2$ divergence, the sample complexity of RMDPs can often far exceed the standard MDP counterpart.
4/15/2024
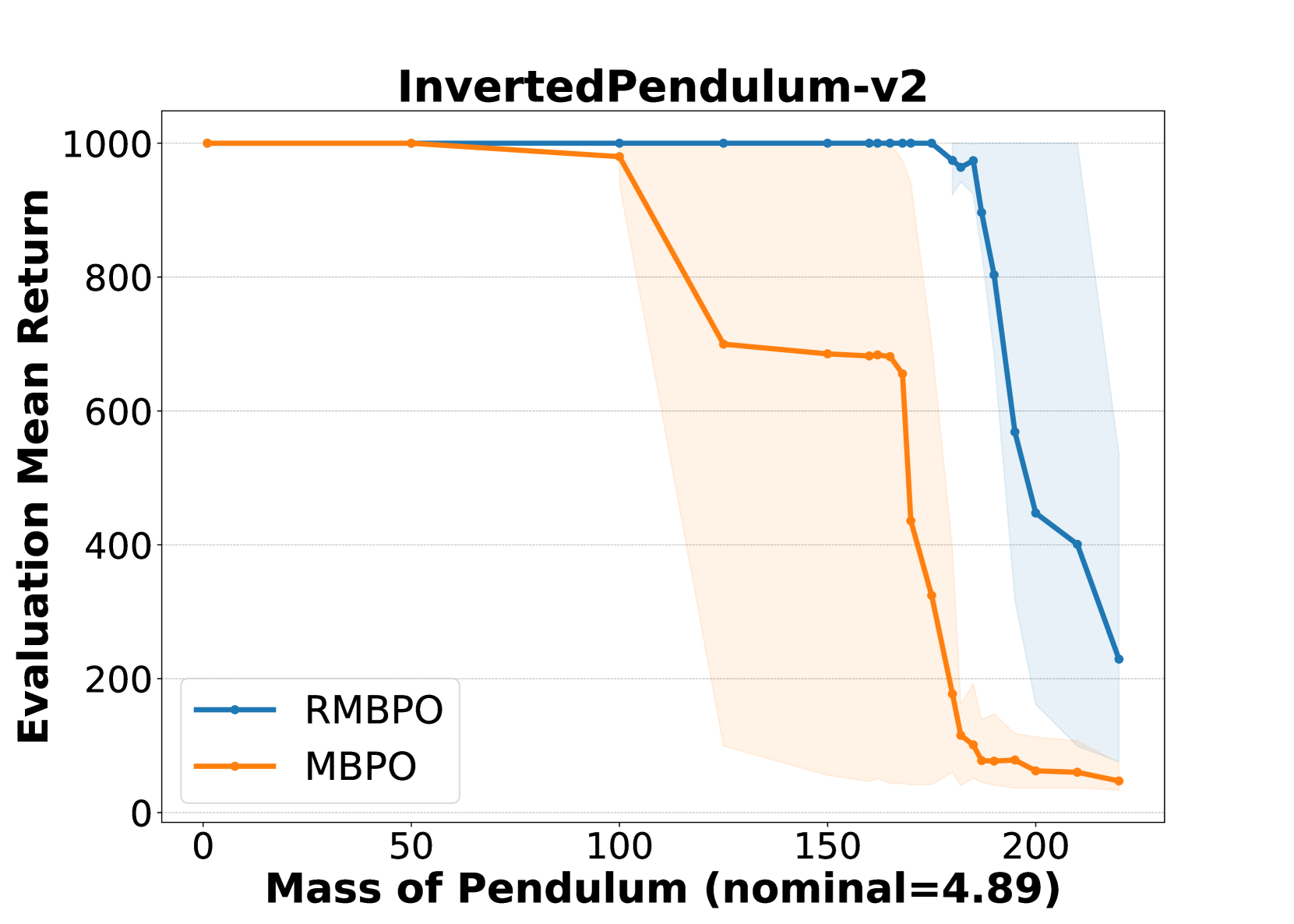
Robust Model-Based Reinforcement Learning with an Adversarial Auxiliary Model
Siemen Herremans, Ali Anwar, Siegfried Mercelis
0
0
Reinforcement learning has demonstrated impressive performance in various challenging problems such as robotics, board games, and classical arcade games. However, its real-world applications can be hindered by the absence of robustness and safety in the learned policies. More specifically, an RL agent that trains in a certain Markov decision process (MDP) often struggles to perform well in nearly identical MDPs. To address this issue, we employ the framework of Robust MDPs (RMDPs) in a model-based setting and introduce a novel learned transition model. Our method specifically incorporates an auxiliary pessimistic model, updated adversarially, to estimate the worst-case MDP within a Kullback-Leibler uncertainty set. In comparison to several existing works, our work does not impose any additional conditions on the training environment, such as the need for a parametric simulator. To test the effectiveness of the proposed pessimistic model in enhancing policy robustness, we integrate it into a practical RL algorithm, called Robust Model-Based Policy Optimization (RMBPO). Our experimental results indicate a notable improvement in policy robustness on high-dimensional MuJoCo control tasks, with the auxiliary model enhancing the performance of the learned policy in distorted MDPs. We further explore the learned deviation between the proposed auxiliary world model and the nominal model, to examine how pessimism is achieved. By learning a pessimistic world model and demonstrating its role in improving policy robustness, our research contributes towards making (model-based) RL more robust.
6/17/2024
🐍
Sample Complexity of Offline Distributionally Robust Linear Markov Decision Processes
He Wang, Laixi Shi, Yuejie Chi
0
0
In offline reinforcement learning (RL), the absence of active exploration calls for attention on the model robustness to tackle the sim-to-real gap, where the discrepancy between the simulated and deployed environments can significantly undermine the performance of the learned policy. To endow the learned policy with robustness in a sample-efficient manner in the presence of high-dimensional state-action space, this paper considers the sample complexity of distributionally robust linear Markov decision processes (MDPs) with an uncertainty set characterized by the total variation distance using offline data. We develop a pessimistic model-based algorithm and establish its sample complexity bound under minimal data coverage assumptions, which outperforms prior art by at least $widetilde{O}(d)$, where $d$ is the feature dimension. We further improve the performance guarantee of the proposed algorithm by incorporating a carefully-designed variance estimator.
6/28/2024