Time-Constrained Robust MDPs
2406.08395
0
0

Abstract
Robust reinforcement learning is essential for deploying reinforcement learning algorithms in real-world scenarios where environmental uncertainty predominates. Traditional robust reinforcement learning often depends on rectangularity assumptions, where adverse probability measures of outcome states are assumed to be independent across different states and actions. This assumption, rarely fulfilled in practice, leads to overly conservative policies. To address this problem, we introduce a new time-constrained robust MDP (TC-RMDP) formulation that considers multifactorial, correlated, and time-dependent disturbances, thus more accurately reflecting real-world dynamics. This formulation goes beyond the conventional rectangularity paradigm, offering new perspectives and expanding the analytical framework for robust RL. We propose three distinct algorithms, each using varying levels of environmental information, and evaluate them extensively on continuous control benchmarks. Our results demonstrate that these algorithms yield an efficient tradeoff between performance and robustness, outperforming traditional deep robust RL methods in time-constrained environments while preserving robustness in classical benchmarks. This study revisits the prevailing assumptions in robust RL and opens new avenues for developing more practical and realistic RL applications.
Create account to get full access
Overview
- This paper introduces a new framework called "Time-Constrained Robust MDPs" to address the challenge of making decisions under uncertainty with time constraints.
- The authors propose algorithms to solve this problem and provide theoretical analysis and empirical results.
- The research has implications for real-world applications that require decision-making with limited time, such as autonomous driving, robotics, and financial trading.
Plain English Explanation
The paper explores a type of decision-making problem where an agent (like a robot or self-driving car) needs to make choices under uncertain conditions, but also has a time limit to make those decisions. This is a common challenge in many real-world applications.
For example, imagine a self-driving car that needs to quickly decide how to navigate through traffic. There are many possible outcomes that could happen, and the car has to choose the best action, but it only has a short amount of time to do so before it needs to take that action. The authors of this paper developed new mathematical models and algorithms to help agents make these types of time-constrained decisions under uncertainty.
Their approach allows the agent to account for the possibility of different outcomes and choose actions that are robust to those uncertainties, all while meeting the time constraints. This could lead to more reliable and effective decision-making in domains like autonomous driving, multi-agent systems, and financial trading.
Technical Explanation
The paper formalizes the "Time-Constrained Robust MDP" (TC-RMDP) framework, which extends the standard Markov Decision Process (MDP) model to incorporate time constraints and uncertainty about the environment dynamics.
In a TC-RMDP, the agent must choose an action at each step that not only maximizes its expected reward, but also ensures that the decision can be made within a given time limit. The authors provide theoretical analysis to characterize the optimal policy for this problem, showing that it has a specific structure that can be exploited computationally.
They then propose two algorithms to solve TC-RMDPs: one based on robust dynamic programming, and another that uses a sample-based approach to handle large state spaces. These algorithms are evaluated on several benchmark problems, demonstrating their effectiveness at finding robust, time-constrained policies.
The results indicate that the TC-RMDP framework and the proposed methods can lead to more robust and risk-sensitive decision-making compared to standard MDP approaches, especially in domains with high uncertainty and strict time constraints.
Critical Analysis
The paper makes a compelling case for the importance of time-constrained decision-making under uncertainty, and the proposed TC-RMDP framework is a promising step forward. However, there are a few limitations and areas for further research:
-
The theoretical analysis assumes that the agent has perfect knowledge of the environment dynamics, which may not hold in many real-world scenarios. Extending the framework to handle distributional robustness or learning the dynamics could improve its applicability.
-
The experiments are conducted on relatively simple benchmark problems. Evaluating the algorithms on more complex, realistic domains would help validate their scalability and practical usefulness.
-
The paper does not discuss potential issues around the ethical implications of time-constrained decision-making, such as how to balance competing objectives or handle edge cases that may put human lives at risk. Addressing these concerns could strengthen the real-world impact of this research.
Overall, the TC-RMDP framework is an important contribution that opens up new avenues for decision-making under uncertainty and time pressure. Further refinements and extensions of this work could lead to significant advancements in fields like autonomous systems and financial trading.
Conclusion
The "Time-Constrained Robust MDPs" paper introduces a novel framework and algorithms to address the challenge of making robust decisions under uncertainty within strict time limits. This research has important implications for real-world applications that require fast, reliable decision-making, such as autonomous driving, robotics, and financial trading.
The authors provide theoretical analysis and empirical results demonstrating the effectiveness of their approach, which seeks to balance maximizing expected reward with ensuring that decisions can be made quickly. While the framework has some limitations, it represents a significant step forward in the field of decision-making under uncertainty and time pressure.
As AI systems become increasingly integrated into safety-critical domains, the ability to make robust, time-constrained decisions will only grow in importance. This paper lays the groundwork for further advancements in this area, which could lead to more reliable and efficient autonomous systems that can better navigate the complexities of the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
Solving Robust MDPs through No-Regret Dynamics
Etash Kumar Guha
0
0
Reinforcement Learning is a powerful framework for training agents to navigate different situations, but it is susceptible to changes in environmental dynamics. However, solving Markov Decision Processes that are robust to changes is difficult due to nonconvexity and size of action or state spaces. While most works have analyzed this problem by taking different assumptions on the problem, a general and efficient theoretical analysis is still missing. However, we generate a simple framework for improving robustness by solving a minimax iterative optimization problem where a policy player and an environmental dynamics player are playing against each other. Leveraging recent results in online nonconvex learning and techniques from improving policy gradient methods, we yield an algorithm that maximizes the robustness of the Value Function on the order of $mathcal{O}left(frac{1}{T^{frac{1}{2}}}right)$ where $T$ is the number of iterations of the algorithm.
6/21/2024

When to Sense and Control? A Time-adaptive Approach for Continuous-Time RL
Lenart Treven, Bhavya Sukhija, Yarden As, Florian Dorfler, Andreas Krause
0
0
Reinforcement learning (RL) excels in optimizing policies for discrete-time Markov decision processes (MDP). However, various systems are inherently continuous in time, making discrete-time MDPs an inexact modeling choice. In many applications, such as greenhouse control or medical treatments, each interaction (measurement or switching of action) involves manual intervention and thus is inherently costly. Therefore, we generally prefer a time-adaptive approach with fewer interactions with the system. In this work, we formalize an RL framework, Time-adaptive Control & Sensing (TaCoS), that tackles this challenge by optimizing over policies that besides control predict the duration of its application. Our formulation results in an extended MDP that any standard RL algorithm can solve. We demonstrate that state-of-the-art RL algorithms trained on TaCoS drastically reduce the interaction amount over their discrete-time counterpart while retaining the same or improved performance, and exhibiting robustness over discretization frequency. Finally, we propose OTaCoS, an efficient model-based algorithm for our setting. We show that OTaCoS enjoys sublinear regret for systems with sufficiently smooth dynamics and empirically results in further sample-efficiency gains.
6/5/2024
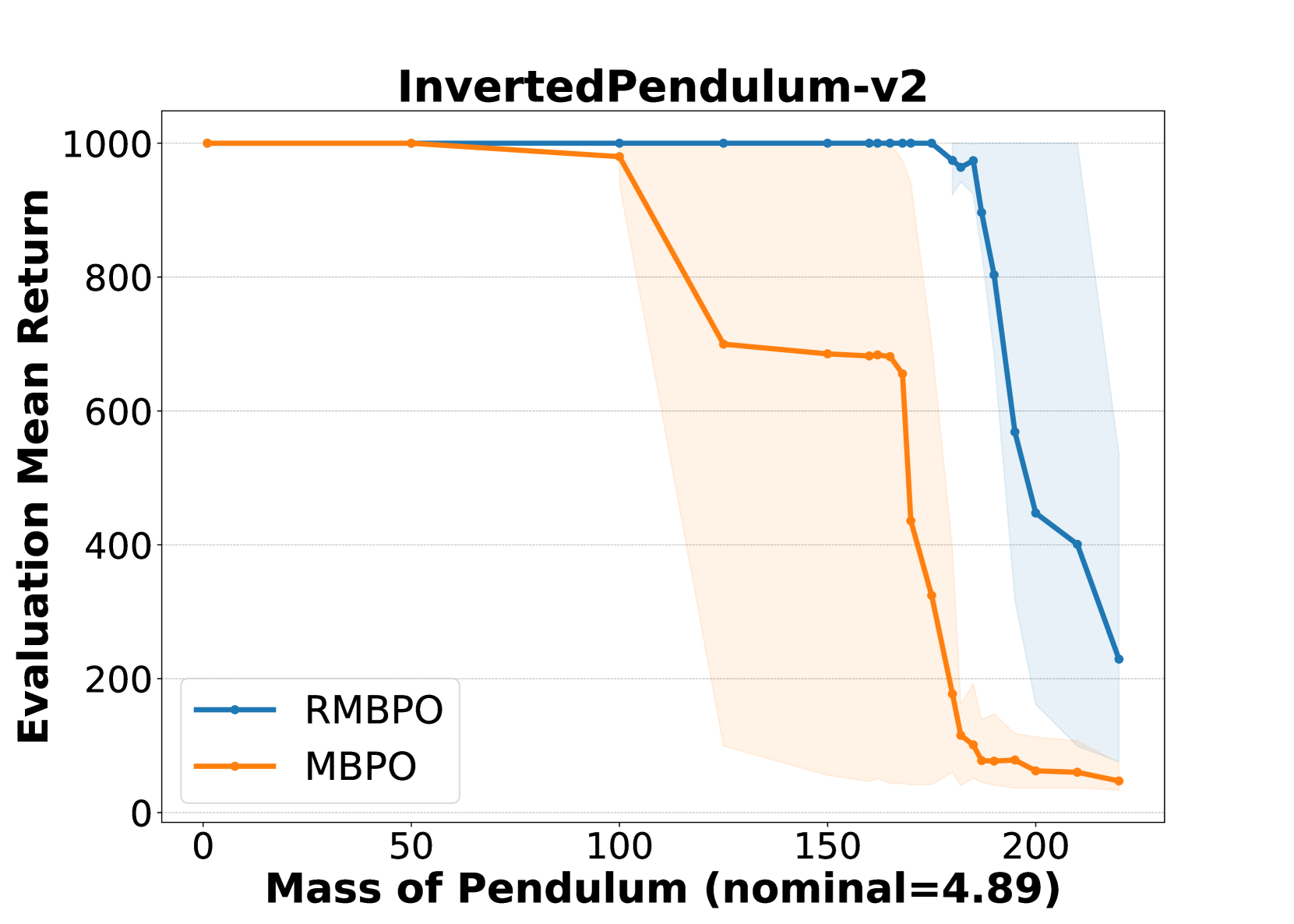
Robust Model-Based Reinforcement Learning with an Adversarial Auxiliary Model
Siemen Herremans, Ali Anwar, Siegfried Mercelis
0
0
Reinforcement learning has demonstrated impressive performance in various challenging problems such as robotics, board games, and classical arcade games. However, its real-world applications can be hindered by the absence of robustness and safety in the learned policies. More specifically, an RL agent that trains in a certain Markov decision process (MDP) often struggles to perform well in nearly identical MDPs. To address this issue, we employ the framework of Robust MDPs (RMDPs) in a model-based setting and introduce a novel learned transition model. Our method specifically incorporates an auxiliary pessimistic model, updated adversarially, to estimate the worst-case MDP within a Kullback-Leibler uncertainty set. In comparison to several existing works, our work does not impose any additional conditions on the training environment, such as the need for a parametric simulator. To test the effectiveness of the proposed pessimistic model in enhancing policy robustness, we integrate it into a practical RL algorithm, called Robust Model-Based Policy Optimization (RMBPO). Our experimental results indicate a notable improvement in policy robustness on high-dimensional MuJoCo control tasks, with the auxiliary model enhancing the performance of the learned policy in distorted MDPs. We further explore the learned deviation between the proposed auxiliary world model and the nominal model, to examine how pessimism is achieved. By learning a pessimistic world model and demonstrating its role in improving policy robustness, our research contributes towards making (model-based) RL more robust.
6/17/2024
Sample-Efficient Robust Multi-Agent Reinforcement Learning in the Face of Environmental Uncertainty
Laixi Shi, Eric Mazumdar, Yuejie Chi, Adam Wierman
0
0
To overcome the sim-to-real gap in reinforcement learning (RL), learned policies must maintain robustness against environmental uncertainties. While robust RL has been widely studied in single-agent regimes, in multi-agent environments, the problem remains understudied -- despite the fact that the problems posed by environmental uncertainties are often exacerbated by strategic interactions. This work focuses on learning in distributionally robust Markov games (RMGs), a robust variant of standard Markov games, wherein each agent aims to learn a policy that maximizes its own worst-case performance when the deployed environment deviates within its own prescribed uncertainty set. This results in a set of robust equilibrium strategies for all agents that align with classic notions of game-theoretic equilibria. Assuming a non-adaptive sampling mechanism from a generative model, we propose a sample-efficient model-based algorithm (DRNVI) with finite-sample complexity guarantees for learning robust variants of various notions of game-theoretic equilibria. We also establish an information-theoretic lower bound for solving RMGs, which confirms the near-optimal sample complexity of DRNVI with respect to problem-dependent factors such as the size of the state space, the target accuracy, and the horizon length.
5/10/2024