Efficient Edge AI: Deploying Convolutional Neural Networks on FPGA with the Gemmini Accelerator

0
🧠
Sign in to get full access
Overview
- Growing concerns about energy consumption and privacy have led to the development of edge-based AI solutions.
- Deploying Convolutional Neural Networks (CNNs) on non-off-the-shelf edge devices is a complex and labor-intensive task.
- This paper presents an end-to-end workflow for deploying CNNs on Field Programmable Gate Arrays (FPGAs) using the Gemmini accelerator, which has been modified for efficient FPGA implementation.
- The authors leverage open-source software, describe their customizations, and evaluate the performance of their FPGA-based solution.
Plain English Explanation
The paper addresses the challenge of deploying powerful AI models on edge devices - small, low-power computers that can process data locally instead of sending it to the cloud. This is important because cloud-based AI processing can consume a lot of energy and raise privacy concerns by sending sensitive data to remote servers.
The researchers focused on deploying Convolutional Neural Networks (CNNs), a type of AI model commonly used for image and video analysis, on Field Programmable Gate Arrays (FPGAs). FPGAs are a type of chip that can be reprogrammed to accelerate specific tasks, like running AI models.
The key contributions of the paper are:
- Developing an end-to-end workflow for deploying CNNs on FPGAs, which can be a complex process.
- Modifying an open-source accelerator called Gemmini to work efficiently on FPGAs.
- Achieving real-time performance on a FPGA with high energy efficiency, outperforming other embedded hardware and FPGA-based solutions.
- Demonstrating how this FPGA-based solution can be integrated into a wider system, such as a traffic monitoring application.
By creating this optimized FPGA-based approach, the researchers have shown how powerful AI models can be deployed on energy-efficient edge devices, addressing concerns about cloud computing's environmental impact and data privacy.
Technical Explanation
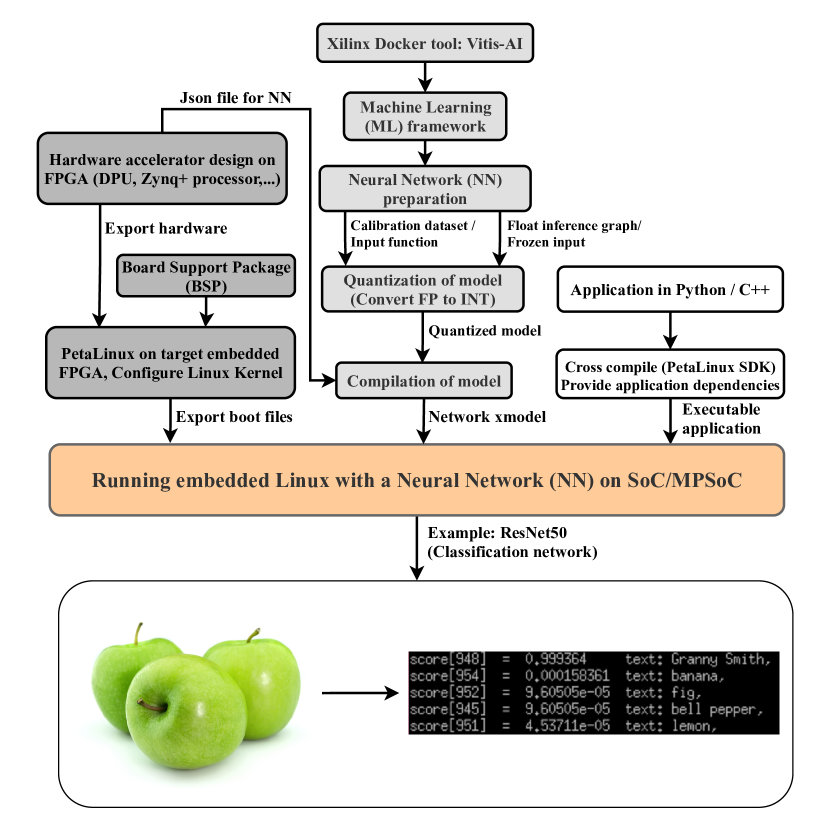
The paper presents an end-to-end workflow for deploying Convolutional Neural Networks (CNNs) on Field Programmable Gate Arrays (FPGAs) using the Gemmini accelerator. The authors modified Gemmini to enable efficient FPGA implementation and leverage open-source software tools at each step of the deployment process.
The researchers used a YOLOv7 model, a popular object detection CNN, as the target for their FPGA deployment. They implemented the model on a Xilinx ZCU102 FPGA and were able to achieve real-time performance with an energy efficiency of 36.5 GOP/s/W (giga-operations per second per watt).
The authors compared their FPGA-based solution to other embedded hardware devices and FPGA reference implementations, demonstrating superior power efficiency. They also integrated their proposed platform into a traffic monitoring scenario to showcase its potential for wider system integration.
The key technical elements of the paper include:
- Modifying the open-source Gemmini accelerator for efficient FPGA implementation
- Leveraging open-source software tools at each step of the deployment process
- Deploying a YOLOv7 CNN model on a Xilinx ZCU102 FPGA
- Achieving real-time performance with high energy efficiency
- Comparing the FPGA-based solution to other embedded hardware and FPGA implementations
- Integrating the platform into a traffic monitoring application
Critical Analysis
The paper presents a well-designed and comprehensive workflow for deploying CNNs on FPGAs, which addresses the challenges of complexity and labor-intensiveness associated with this task. The authors' use of open-source tools and customizations to the Gemmini accelerator demonstrate a thoughtful approach to optimizing the deployment process.
One potential limitation of the research is the focus on a single CNN model (YOLOv7) and a single FPGA platform (Xilinx ZCU102). While the results are impressive, it would be valuable to see the workflow applied to a broader range of models and edge devices to further validate its generalizability.
Additionally, the paper does not provide much detail on the specific challenges or trade-offs encountered during the optimization process. A more in-depth discussion of the design decisions and their impact on the final system's performance could help other researchers and practitioners better understand the nuances of FPGA-based CNN deployment.
Overall, the paper makes a valuable contribution by showcasing a practical solution for deploying powerful AI models on energy-efficient edge devices. Further exploration of the technique's scalability and adaptability to different use cases could strengthen the impact of this research.
Conclusion
This paper presents an end-to-end workflow for deploying Convolutional Neural Networks (CNNs) on Field Programmable Gate Arrays (FPGAs), addressing the growing demand for energy-efficient and privacy-preserving AI solutions at the edge. The researchers leveraged open-source tools and modified the Gemmini accelerator to enable efficient FPGA implementation, resulting in a high-performance and power-efficient system.
The demonstrated ability to deploy a state-of-the-art CNN model like YOLOv7 with real-time performance on an FPGA platform is a significant achievement, with potential applications in various domains, such as the traffic monitoring scenario presented in the paper. By sharing this workflow and the insights gained, the authors have provided a valuable resource for researchers and practitioners working to bring advanced AI capabilities to the edge.
As edge computing continues to grow in importance, solutions like the one described in this paper will play a crucial role in addressing the challenges of energy consumption and privacy while unlocking the full potential of AI for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Efficient Edge AI: Deploying Convolutional Neural Networks on FPGA with the Gemmini Accelerator
Federico Nicolas Peccia, Svetlana Pavlitska, Tobias Fleck, Oliver Bringmann
The growing concerns regarding energy consumption and privacy have prompted the development of AI solutions deployable on the edge, circumventing the substantial CO2 emissions associated with cloud servers and mitigating risks related to sharing sensitive data. But deploying Convolutional Neural Networks (CNNs) on non-off-the-shelf edge devices remains a complex and labor-intensive task. In this paper, we present and end-to-end workflow for deployment of CNNs on Field Programmable Gate Arrays (FPGAs) using the Gemmini accelerator, which we modified for efficient implementation on FPGAs. We describe how we leverage the use of open source software on each optimization step of the deployment process, the customizations we added to them and its impact on the final system's performance. We were able to achieve real-time performance by deploying a YOLOv7 model on a Xilinx ZCU102 FPGA with an energy efficiency of 36.5 GOP/s/W. Our FPGA-based solution demonstrates superior power efficiency compared with other embedded hardware devices, and even outperforms other FPGA reference implementations. Finally, we present how this kind of solution can be integrated into a wider system, by testing our proposed platform in a traffic monitoring scenario.
Read more8/15/2024
0
Latency optimized Deep Neural Networks (DNNs): An Artificial Intelligence approach at the Edge using Multiprocessor System on Chip (MPSoC)
Seyed Nima Omidsajedi, Rekha Reddy, Jianming Yi, Jan Herbst, Christoph Lipps, Hans Dieter Schotten
Almost in every heavily computation-dependent application, from 6G communication systems to autonomous driving platforms, a large portion of computing should be near to the client side. Edge computing (AI at Edge) in mobile devices is one of the optimized approaches for addressing this requirement. Therefore, in this work, the possibilities and challenges of implementing a low-latency and power-optimized smart mobile system are examined. Utilizing Field Programmable Gate Array (FPGA) based solutions at the edge will lead to bandwidth-optimized designs and as a consequence can boost the computational effectiveness at a system-level deadline. Moreover, various performance aspects and implementation feasibilities of Neural Networks (NNs) on both embedded FPGA edge devices (using Xilinx Multiprocessor System on Chip (MPSoC)) and Cloud are discussed throughout this research. The main goal of this work is to demonstrate a hybrid system that uses the deep learning programmable engine developed by Xilinx Inc. as the main component of the hardware accelerator. Then based on this design, an efficient system for mobile edge computing is represented by utilizing an embedded solution.
Read more7/29/2024

0
New!Automatic Generation of Fast and Accurate Performance Models for Deep Neural Network Accelerators
Konstantin Lubeck, Alexander Louis-Ferdinand Jung, Felix Wedlich, Mika Markus Muller, Federico Nicol'as Peccia, Felix Thommes, Jannik Steinmetz, Valentin Biermaier, Adrian Frischknecht, Paul Palomero Bernardo, Oliver Bringmann
Implementing Deep Neural Networks (DNNs) on resource-constrained edge devices is a challenging task that requires tailored hardware accelerator architectures and a clear understanding of their performance characteristics when executing the intended AI workload. To facilitate this, we present an automated generation approach for fast performance models to accurately estimate the latency of a DNN mapped onto systematically modeled and concisely described accelerator architectures. Using our accelerator architecture description method, we modeled representative DNN accelerators such as Gemmini, UltraTrail, Plasticine-derived, and a parameterizable systolic array. Together with DNN mappings for those modeled architectures, we perform a combined DNN/hardware dependency graph analysis, which enables us, in the best case, to evaluate only 154 loop kernel iterations to estimate the performance for 4.19 billion instructions achieving a significant speedup. We outperform regression and analytical models in terms of mean absolute percentage error (MAPE) compared to simulation results, while being several magnitudes faster than an RTL simulation.
Read more9/16/2024

0
H2PIPE: High throughput CNN Inference on FPGAs with High-Bandwidth Memory
Mario Doumet, Marius Stan, Mathew Hall, Vaughn Betz
Convolutional Neural Networks (CNNs) combine large amounts of parallelizable computation with frequent memory access. Field Programmable Gate Arrays (FPGAs) can achieve low latency and high throughput CNN inference by implementing dataflow accelerators that pipeline layer-specific hardware to implement an entire network. By implementing a different processing element for each CNN layer, these layer-pipelined accelerators can achieve high compute density, but having all layers processing in parallel requires high memory bandwidth. Traditionally this has been satisfied by storing all weights on chip, but this is infeasible for the largest CNNs, which are often those most in need of acceleration. In this work we augment a state-of-the-art dataflow accelerator (HPIPE) to leverage both High-Bandwidth Memory (HBM) and on-chip storage, enabling high performance layer-pipelined dataflow acceleration of large CNNs. Based on profiling results of HBM's latency and throughput against expected address patterns, we develop an algorithm to choose which weight buffers should be moved off chip and how deep the on-chip FIFOs to HBM should be to minimize compute unit stalling. We integrate the new hardware generation within the HPIPE domain-specific CNN compiler and demonstrate good bandwidth efficiency against theoretical limits. Compared to the best prior work we obtain speed-ups of at least 19.4x, 5.1x and 10.5x on ResNet-18, ResNet-50 and VGG-16 respectively.
Read more8/20/2024